
Heim >Backend-Entwicklung >Python-Tutorial >Stimmt es, dass Multithreading schneller ist als Singlethreading?
Stimmt es, dass Multithreading schneller ist als Singlethreading?

- coldplay.xixinach vorne
- 2020-11-09 17:11:403422Durchsuche
In der Kolumne
Pyrhon-Video-Tutorial erfahren Sie, ob Multi-Threading wirklich schneller ist als Single-Threading.

Tatsächlich heißt ein weiteres sehr wichtiges Thema im Python-Multithreading GIL (Global Interpreter Lock, d. h. globale Interpretersperre). GIL(Global Interpreter Lock,即全局解释器锁)。
多线程不一定比单线程快
在Python中,可以通过多进程、多线程和多协程来实现多任务。难道多线程就一定比单线程快?
下面我用一段代码证明我自己得观点。
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import threading, timedef my_counter():
i = 0
for _ in range(100000000):
i = i+1
return Truedef main1():
start_time = time.time() for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
t.join() # 第一次循环的时候join方法引起主线程阻塞,但第二个线程并没有启动,所以两个线程是顺序执行的
print("单线程顺序执行total_time: {}".format(time.time() - start_time))def main2():
thread_ary = {}
start_time = time.time() for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
thread_ary[tid] = t for i in range(2):
thread_ary[i].join() # 两个线程均已启动,所以两个线程是并发的
print("多线程执行total_time: {}".format(time.time() - start_time))if __name__ == "__main__":
main1()
main2()复制代码
运行结果
单线程顺序执行total_time: 17.754502773284912多线程执行total_time: 20.01178550720215复制代码
我怕你说我乱得出来得结果,我还是截个图看清楚点

这时,我怀疑:我的机器出问题了吗?其实不是这样,本质上来说Python 的线程失效了,没有起到并行计算的作用。
Python 的线程,的确封装了底层的操作系统线程,在 Linux 系统里是 Pthread(全称为 POSIX Thread),而在 Windows 系统里是 Windows Thread
Mehrere Threads sind nicht unbedingt schneller als einzelne ThreadsIn Python kann Multitasking durch Multiprozesse, Multithreads und Multi-Coroutinen erreicht werden. Ist Multithreading unbedingt schneller als Singlethreading?
Unten verwende ich einen Code, um meinen Standpunkt zu beweisen. '''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import time
COUNT = 50_000_000def count_down():
global COUNT while COUNT > 0:
COUNT -= 1s = time.perf_counter()
count_down()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 9.2957003复制代码Laufergebnisse
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import timefrom threading import Thread
COUNT = 50_000_000def count_down():
global COUNT while COUNT > 0:
COUNT -= 1s = time.perf_counter()
t1 = Thread(target=count_down)
t2 = Thread(target=count_down)
t1.start()
t2.start()
t1.join()
t2.join()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 17.110625复制代码
Ich fürchte, Sie werden sagen, dass ich das Ergebnis zufällig erhalten habe, also mache ich lieber einen Screenshot, um es deutlich zu sehen
Zu diesem Zeitpunkt fragte ich mich : Stimmt etwas mit meiner Maschine nicht? Tatsächlich ist dies nicht der Fall. Die Threads von Python sind fehlgeschlagen und spielen beim parallelen Rechnen keine Rolle.
Pythons Thread kapselt den zugrunde liegenden Betriebssystem-Thread. Im Linux-System ist es Pthread (vollständiger Name: POSIX Thread), während es im Windows-System so ist Windows-Thread. Darüber hinaus werden die Threads von Python auch vollständig vom Betriebssystem verwaltet, z. B. die Koordinierung des Ausführungszeitpunkts, die Verwaltung von Speicherressourcen, die Verwaltung von Interrupts usw.
GIL ist keine Funktion von PythonDas Konzept von GIL lässt sich in einem einfachen Satz erklären:
Ein einzelner CPython-Interpreter kann jederzeit, egal wie viele Threads vorhanden sind, nur einen Bytecode ausführen. Zu dieser Definition sind folgende Punkte zu beachten: Das erste, was klargestellt werden muss, ist, dass
GIL keine Funktion von Python ist, sondern ein Konzept, das bei der Implementierung des Python-Parsers (CPython) eingeführt wird. C++ ist eine Reihe von Sprach-(Grammatik-)Standards, die jedoch mit verschiedenen Compilern in ausführbaren Code kompiliert werden können. Berühmte Compiler wie GCC, INTEL C++, Visual C++ usw. Das Gleiche gilt für Python. Derselbe Code kann über verschiedene Python-Ausführungsumgebungen wie CPython, PyPy und Psyco ausgeführt werden.Andere Python-Interpreter verfügen möglicherweise nicht über GIL
. Beispielsweise verfügen Jython (JVM) und IronPython (CLR) nicht über GIL, während CPython und PyPy über GIL verfügen.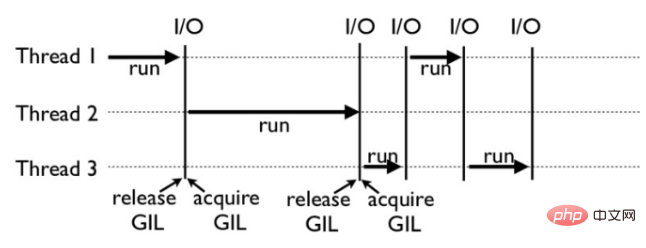 Da CPython in den meisten Umgebungen die Standardausführungsumgebung für Python ist. Daher ist CPython in der Vorstellung vieler Menschen Python und sie gehen davon aus, dass GIL ein Defekt der Python-Sprache ist. Lassen Sie uns hier klarstellen:
Da CPython in den meisten Umgebungen die Standardausführungsumgebung für Python ist. Daher ist CPython in der Vorstellung vieler Menschen Python und sie gehen davon aus, dass GIL ein Defekt der Python-Sprache ist. Lassen Sie uns hier klarstellen:
GIL ist im Wesentlichen eine Mutex-Sperre Mutex-Sperre: Das Wesen aller Mutex-Sperren ist das gleiche. Sie wandeln gleichzeitige Vorgänge in serielle Vorgänge um, um zu steuern, dass gemeinsam genutzte Daten nur von einer Aufgabe gleichzeitig geändert werden können, wodurch die Datensicherheit gewährleistet wird.
Eines ist sicher: Um die Sicherheit verschiedener Daten zu schützen, sollten unterschiedliche Sperren hinzugefügt werden.
So funktioniert GIL: Das Bild unten ist beispielsweise ein Beispiel dafür, wie GIL in einem Python-Programm funktioniert. Unter ihnen werden Thread 1, 2 und 3 nacheinander ausgeführt. Wenn jeder Thread mit der Ausführung beginnt, wird die GIL gesperrt, um die Ausführung anderer Threads für einen bestimmten Zeitraum zu verhindern Ermöglichen Sie die Ausführung anderer Threads. Der Thread beginnt, Ressourcen zu nutzen.
RechenintensiveRechenintensive Aufgaben zeichnen sich durch eine große Menge an Berechnungen und den Verbrauch von CPU-Ressourcen aus.
Schauen wir uns zunächst ein einfaches rechenintensives Beispiel an:rrreeeEin anderer Typ sind E/A-intensive Aufgaben, die Netzwerk- und Festplatten-E/A betreffen. Das Merkmal dieser Art von Aufgabe ist, dass der CPU-Verbrauch sehr gering ist und der Großteil der Aufgabe auf den E/A-Vorgang wartet abgeschlossen sein (weil die Geschwindigkeit von IO viel niedriger ist als die Geschwindigkeit von CPU und Speicher). Bei E/A-intensiven Aufgaben gilt: Je mehr Aufgaben, desto höher die CPU-Effizienz, es gibt jedoch eine Grenze. Bei den häufigsten Aufgaben handelt es sich um E/A-intensive Aufgaben, beispielsweise Webanwendungen. 🎜🎜🎜Zusammenfassung: Bei io-intensiver Arbeit (Python-Crawler) kann Multithreading die Codeeffizienz erheblich verbessern. Für CPU-intensives Computing (Python-Datenanalyse, maschinelles Lernen, Deep Learning) ist Multithreading möglicherweise etwas weniger effizient als Singlethreading. Daher gibt es kein Multithreading zur Verbesserung der Effizienz im Datenbereich. Die einzige Möglichkeit, die Rechenleistung zu verbessern, besteht darin, die CPU auf GPU und TPU aufzurüsten. 🎜🎜🎜🎜Verwandte kostenlose Lernempfehlungen: 🎜Python-Video-Tutorial🎜🎜🎜Dies ist ein einzelner Thread und die Zeit beträgt 9 Sekunden. Sehen wir uns zwei Threads an, um zu sehen, was das Ergebnis ist: rrreeeDie Hauptoperation unseres Programms ist die Berechnung Die CPU wartet nicht, aber nach dem Wechsel zu Multithreading und dem Hinzufügen von Threads erhöht sich der Zeitaufwand durch häufiges Wechseln zwischen Threads, und die Zeit erhöht sich natürlich.
Das obige ist der detaillierte Inhalt vonStimmt es, dass Multithreading schneller ist als Singlethreading?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!