
Heim >Datenbank >MySQL-Tutorial >Ein kurzes Verständnis von MySQL-Sperren, Transaktionen und MVCC
Ein kurzes Verständnis von MySQL-Sperren, Transaktionen und MVCC

- coldplay.xixinach vorne
- 2020-11-04 17:31:122486Durchsuche
Die Spalte „MySQL-Tutorial“ führt in ein einfaches Verständnis von MySQL-Sperren, Transaktionen und MVCC ein.
Weitere verwandte kostenlose Lernempfehlungen:
MySQL-Tutorial (Video)
Wird eine einzelne SQL-Anweisung als Transaktion übermittelt, wenn sie ausgeführt wird?
Der folgende Inhalt ist ein Auszug aus „High-Performance MySQL“ (3. Auflage)“
MySQL verwendet standardmäßig den automatischen Commit-Modus (AUTOCOMMIT). Das heißt, wenn eine Transaktion nicht explizit gestartet wird , jede Abfrage wird als Transaktion behandelt, um einen Festschreibungsvorgang auszuführen. In der aktuellen Verbindung können Sie den automatischen Festschreibungsmodus aktivieren oder deaktivieren, indem Sie die AUTOCOMMIT-Variable festlegen SÄURE?Transaktionen haben die vier Merkmale von ACID. Wie implementiert MySQL diese vier Attribute von Transaktionen?Atomar Entweder sind alle erfolgreich oder alle scheitern. MySQL erreicht Atomizität durch die Aufzeichnung von undo_log. Undo_log ist ein
 , das auf die Festplatte geschrieben wird, bevor das eigentliche SQL ausgeführt wird, und dann die Datenbankdaten verarbeitet. Wenn eine Ausnahme oder ein Rollback auftritt, können Sie auf der Grundlage von „undo_log“ umgekehrte Vorgänge ausführen, um die Daten in dem Zustand wiederherzustellen, in dem sie vor der Ausführung der Transaktion waren.
, das auf die Festplatte geschrieben wird, bevor das eigentliche SQL ausgeführt wird, und dann die Datenbankdaten verarbeitet. Wenn eine Ausnahme oder ein Rollback auftritt, können Sie auf der Grundlage von „undo_log“ umgekehrte Vorgänge ausführen, um die Daten in dem Zustand wiederherzustellen, in dem sie vor der Ausführung der Transaktion waren. Beharrlichkeit Sobald eine Transaktion normal festgeschrieben wird, sollten ihre Auswirkungen auf die Datenbank dauerhaft sein. Selbst wenn das System zu diesem Zeitpunkt abstürzt, gehen die geänderten Daten nicht verloren. InnoDB ist die Speicher-Engine von MySQL und die Daten werden auf der Festplatte gespeichert. Wenn jedoch jedes Mal Festplatten-E/A erforderlich ist, um Daten zu lesen und zu schreiben, ist die Effizienz sehr gering. Zu diesem Zweck stellt InnoDB einen Cache (Buffer Pool) als Puffer für den Zugriff auf die Datenbank bereit: Beim Lesen von Daten aus der Datenbank werden diese zunächst aus dem Buffer Pool gelesen vom Datenträger ablegen und in den Pufferpool legen; beim Schreiben von Daten in die Datenbank werden diese zuerst in den Pufferpool geschrieben und die geänderten Daten im Pufferpool werden regelmäßig auf dem Datenträger aktualisiert.
Ein solches Design bringt auch entsprechende Probleme mit sich: Wenn die Daten übermittelt werden und sich die Daten noch im Pufferpool befinden (die Festplatte wurde noch nicht geleert), was soll ich tun, wenn MySQL ausfällt oder die Stromversorgung verliert? Gehen Daten verloren?
Die Antwort ist nein, MySQL gewährleistet die Haltbarkeit durch den redo_log-Mechanismus. Redo_log ist Redo-Log. Wenn die Daten geändert werden, wird der Vorgang zusätzlich zur Änderung der Daten im Pufferpool auch in redo_log aufgezeichnet das redo_log. Wenn MySQL ausfällt, können Sie die Daten in redo_log lesen und die Datenbank beim Neustart wiederherstellen.
isolation
isolation ist die komplexeste in Säure, die das Konzept der Isolationsniveaus beinhaltet.
- Serialisierbar
Einfach ausgedrückt legt die Isolationsstufe fest: Änderung von Daten in einer Transaktion, welche Transaktionen sichtbar und welche nicht sichtbar sind. Bei der Isolation geht es darum, die Zugriffssequenz mehrerer gleichzeitiger Lese- und Schreibanforderungen zu verwalten. - MySQL wird später die spezifische Implementierung der Isolation besprechen.
- Konsistenz
Durch die vorherige Frage weiß ich, dass eine einzelne DDL-Ausführung auch automatisch als Transaktion übermittelt wird, also unabhängig davon, ob es sich um mehrere SQL gleichzeitig handelt oder mehrere manuell Die Transaktionsparallelität der Organisation, die mehrere SQL-Anweisungen enthält, führt zu Problemen mit der Transaktionsparallelität.
Im Einzelnen:
Dirty Write (von einer Transaktion festgeschriebene Daten überschreiben nicht festgeschriebene Daten einer anderen Transaktion) Dirty Read (eine Transaktion liest nicht festgeschriebene Daten einer anderen Transaktion) Nicht wiederholbares Lesen (der entscheidende Punkt ist, dass die in einer Aktualisierungs- und Löschtransaktion mehrmals gelesenen Daten unterschiedlich sind) Phantomlesung (der entscheidende Punkt ist, dass die Anzahl der in einer Einfügetransaktion mehrmals gelesenen Datensätze unterschiedlich ist)
Wir haben es erwähnt Die Isolationsstufe der oben genannten Transaktionen kann garantieren, dass keine schmutzigen Schreibvorgänge auftreten. Die einzigen verbleibenden Probleme sind schmutzige Lesevorgänge, nicht wiederholbare Lesevorgänge und Phantom-Lesevorgänge.
Sehen wir uns genauer an, wie jede Isolationsstufe die oben genannten Probleme löst oder nicht löst:

Nicht festgeschrieben lesen
Nicht festgeschrieben lesen, diese Stufe fügt während des Lesevorgangs keine Sperren hinzu , wird nur beim Schreiben einer Anforderung gesperrt, sodass der Schreibvorgang die Daten während des Lesevorgangs ändert, was zu fehlerhaften Lesevorgängen führt. Es kommt natürlich zu nicht wiederholbaren Lesevorgängen und Phantom-Lesevorgängen.
Festgeschriebenes Lesen
Festgeschriebenes Lesen ist wie nicht festgeschriebenes Lesen nicht zum Lesen und nicht zum Schreiben gesperrt. Der Unterschied besteht darin, dass der MVCC-Mechanismus verwendet wird, um das Problem von Dirty Reads zu vermeiden. Es gibt auch Probleme von nicht wiederholbaren Lesevorgängen und Phantom Reads. Wir werden später ausführlich über MVCC sprechen.
Wiederholbares Lesen
MySQL-Standardisolationsstufe Auf dieser Ebene verwendet MySQL zwei Methoden, um das Problem zu lösen
Lese-/Schreibsperre Beim parallelen Lesen wird eine Lesesperre hinzugefügt, und Lesen und Lesen teilen sich die Sperre. Solange eine Schreibanforderung vorliegt, wird eine Schreibsperre hinzugefügt, sodass Lesen und Schreiben seriell erfolgen. Beim Lesen von Daten wird eine Sperre durchgeführt, und andere Transaktionen können die Daten nicht ändern. Daher werden nicht wiederholbare Lesevorgänge nicht durchgeführt. Sperren sind auch beim Ändern oder Löschen von Daten erforderlich. Andere Transaktionen können die Daten nicht lesen, sodass keine schmutzigen Lesevorgänge stattfinden. Die erste Methode wird oft als „pessimistische Sperre“ bezeichnet. Die Daten werden während des gesamten Transaktionsprozesses gesperrt, was relativ konservativ ist und einen relativ großen Leistungsaufwand mit sich bringt. MVCC (später besprochen)- Darüber hinaus wird die Next-Key-Sperre auch verwendet, um das Problem des Phantomlesens bis zu einem gewissen Grad zu lösen. Wir werden später darüber sprechen.
Unter dieser Isolationsstufe werden Transaktionen seriell ausgeführt. Wenn Autocommit deaktiviert ist, konvertiert InnoDB implizit alle gewöhnlichen SELECT-Anweisungen in SELECT ... LOCK IN SHARE MODE. Das heißt, dem Lesevorgang wird implizit eine gemeinsame Lesesperre hinzugefügt, wodurch die Probleme von schmutzigen Lesevorgängen, nicht wiederholbaren Lesevorgängen und Phantom-Lesevorgängen vermieden werden. Multiversion-Parallelitätskontrolle (MCC oder MVCC) ist eine Parallelitätskontrollmethode, die häufig von Datenbankverwaltungssystemen verwendet wird, um gleichzeitigen Zugriff auf die Datenbank bereitzustellen, und in Programmiersprachen, um Transaktionsspeicher zu implementieren
“
Einfach ausgedrückt handelt es sich um eine Methode, die von der Datenbank zur Steuerung der Parallelität verwendet wird. Jede Datenbank kann eine andere Implementierung von MVCC haben.
Am Beispiel unseres häufig verwendeten MySQL implementiert die InnoDB-Engine von MySQL MVCC.Welche Probleme kann MVCC lösen?Wie InnoDB MVCC implementiert
Das Bild unten stammt aus „High-Performance MySQL“ (3. Auflage)
Dieses Buch ist gut geschrieben und gut übersetzt. Mein ursprüngliches System für MySQL ist auch Aufgrund der Lektüre dieses Buches denke ich jedoch, dass es einige Probleme mit der Beschreibung gibt, wie MVCC implementiert wird.
Mal sehen, wo das Problem liegt
Werfen wir zunächst einen Blick auf die offizielle Dokumentation von MySQL. Ich habe die Dokumente der drei Versionen 5.1, 5.6 und 5.7 verglichen[1], Die Beschreibung dieses Teils von MVCC ist nahezu identisch.
Dem Dokument zufolge ist es offensichtlich, dass jedem Datenelement drei versteckte Spalten hinzugefügt werden:
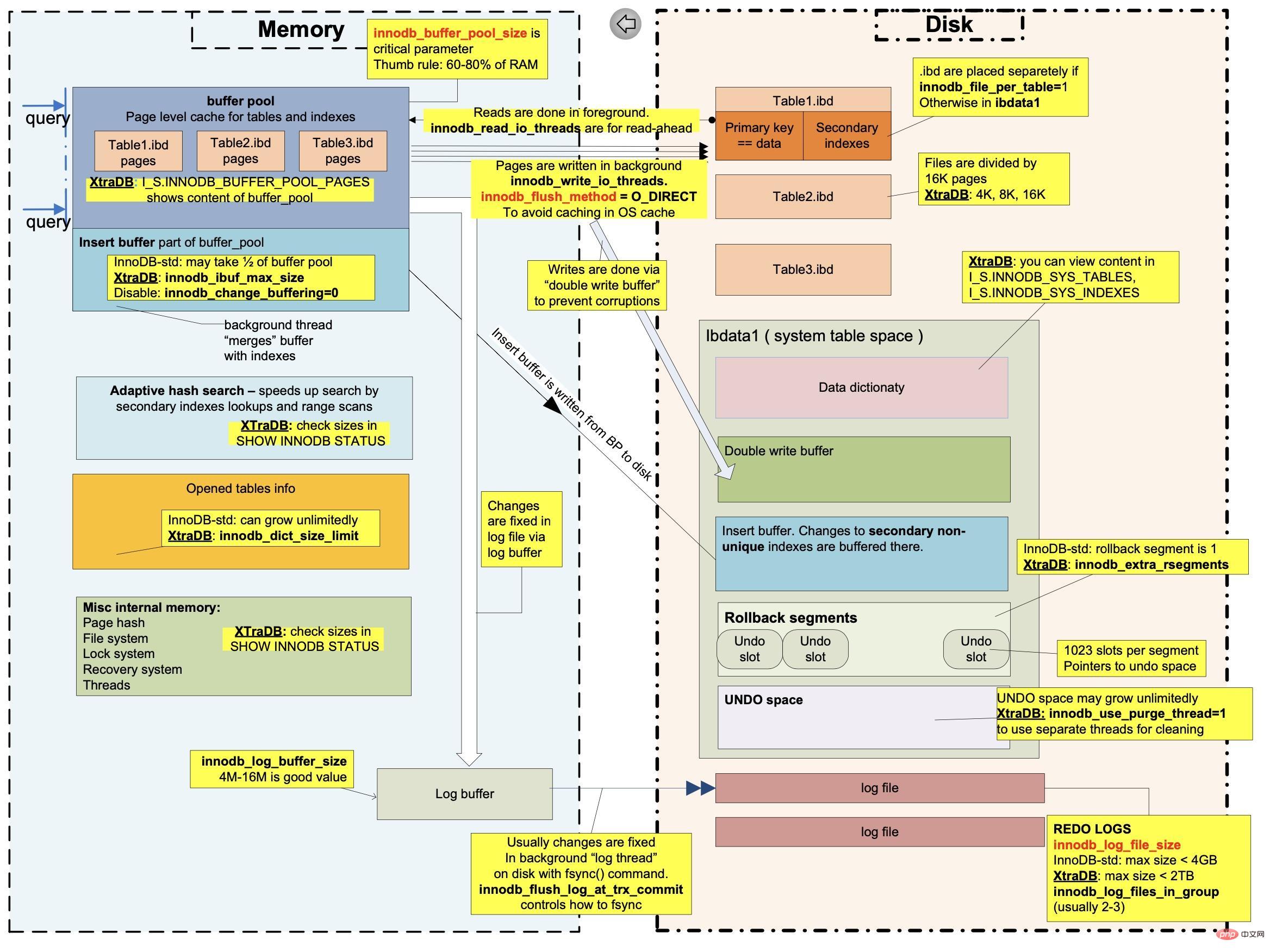
Das 6-Byte-Feld DB_TRX_ID stellt die Transaktions-ID der letzten Einfügung oder Aktualisierung dar der Rekord. Das 7-Byte-Feld DB_ROLL_PTR verweist auf den Undo-Log-Datensatz des Rollback-Segments des Datensatzes. 6-Byte-DB_ROW_ID, die automatisch erhöht wird, wenn neue Daten eingefügt werden. Wenn in der Tabelle kein Benutzerprimärschlüssel vorhanden ist, generiert InnoDB automatisch einen Clustered-Index, einschließlich des Felds DB_ROW_ID. Hier füge ich ein MySQL-internes Strukturdiagramm einschließlich Rollback-Segment hinzu Wir nennen diese verknüpfte Liste eine Versionskette. Der Kopfknoten der Versionskette ist der neueste Wert des aktuellen Datensatzes.
ReadView
Durch das Ausblenden von Spalten und Versionsketten kann MySQL Daten in einer bestimmten Version wiederherstellen. Welche Version wiederhergestellt werden soll, muss jedoch anhand von ReadView bestimmt werden. Die sogenannte ReadView bedeutet, dass eine Transaktion (aufgezeichnet als Transaktion A) zu einem bestimmten Zeitpunkt einen Snapshot des gesamten Transaktionssystems (trx_sys) erstellt. Wenn später ein Lesevorgang ausgeführt wird, wird die Transaktions-ID in den gelesenen Daten verglichen den trx_sys-Snapshot, damit Bestimmen Sie, ob die Daten für ReadView sichtbar sind, d. h. ob sie für Transaktion A sichtbar sind.
Bisher haben wir herausgefunden, dass MVCC basierend auf versteckten Feldern, der Undo_log-Kette und ReadView implementiert wird.
MVCC in Read-Committed
Zuvor haben wir über die Verwendung von MVCC in der Read-Committed-Isolationsstufe gesprochen, um das Dirty-Read-Problem zu lösen. Hier verweise ich auf zwei Artikel:
https://cloud.tencent.com/developer/article/1150633 https://cloud.tencent.com/developer/article/1150630 InnoDB sucht nur nach Datenzeilen, deren Version älter als die aktuelle Transaktionsversion ist (d. h. die Versionsnummer der Zeile ist kleiner oder gleich der Systemversionsnummer der Transaktion). Dadurch wird sichergestellt, dass die von den Daten gelesenen Zeilen auch nicht vorhanden sind bereits vor Beginn der Transaktion vorhanden, entweder eingefügt oder durch die Transaktion selbst geändert. So kommt es zu keinen Dirty Reads.
Nicht wiederholbare Lesevorgänge unter der Isolationsstufe „committedRead“ werden durch den Generierungsmechanismus der Leseansicht verursacht. Auf der Ebene „Festgeschrieben lesen“ sind Daten sichtbar, die festgeschrieben wurden, bevor die aktuelle Anweisung ausgeführt wird. Bei jeder Anweisungsausführung wird die Leseansicht geschlossen und die aktuelle Leseansicht neu erstellt. Auf diese Weise kann das Transaktionsintervall der Leseansicht basierend auf der aktuellen globalen Transaktionsliste erstellt werden. Einfach ausgedrückt generiert MVCC unter der Isolationsstufe „Read committed“ eine Snapshot-Version für jede Auswahl, sodass jede Auswahl unterschiedliche Versionen von Daten liest, sodass nicht wiederholbare Lesevorgänge stattfinden. MVCC in
Wiederholbares Lesen löst das Problem des nicht wiederholbaren Lesens. Mehrere Lesevorgänge in einer Transaktion führen nicht zu unterschiedlichen Ergebnissen und gewährleisten so ein wiederholbares Lesen. Im vorherigen Artikel haben wir gesagt, dass es für wiederholbares Lesen zwei Implementierungsmethoden gibt: eine ist die pessimistische Sperrmethode und die andere ist MVCC, die optimistische Sperrmethode.
Die Isolationsstufe „Wiederholbares Lesen“ kann das Problem des nicht wiederholbaren Lesens lösen. Der Hauptgrund dafür ist, dass sich der Generierungsmechanismus der Leseansicht von dem des „Read Commit“ unterscheidet.
Read commit: Solange die Daten sichtbar sind, die vor der Ausführung der aktuellen Anweisung festgeschrieben wurden. Wiederholbares Lesen: Solange die Daten sichtbar sind, die vor der Ausführung der aktuellen Transaktion übermittelt wurden. Im Gegensatz zu Read Commit wird unter der Isolationsstufe Wiederholbarer Lesevorgang beim Erstellen einer Transaktion die aktuelle globale Leseansicht generiert und bis zum Ende der Transaktion beibehalten. Dies ermöglicht wiederholbare Lesevorgänge.
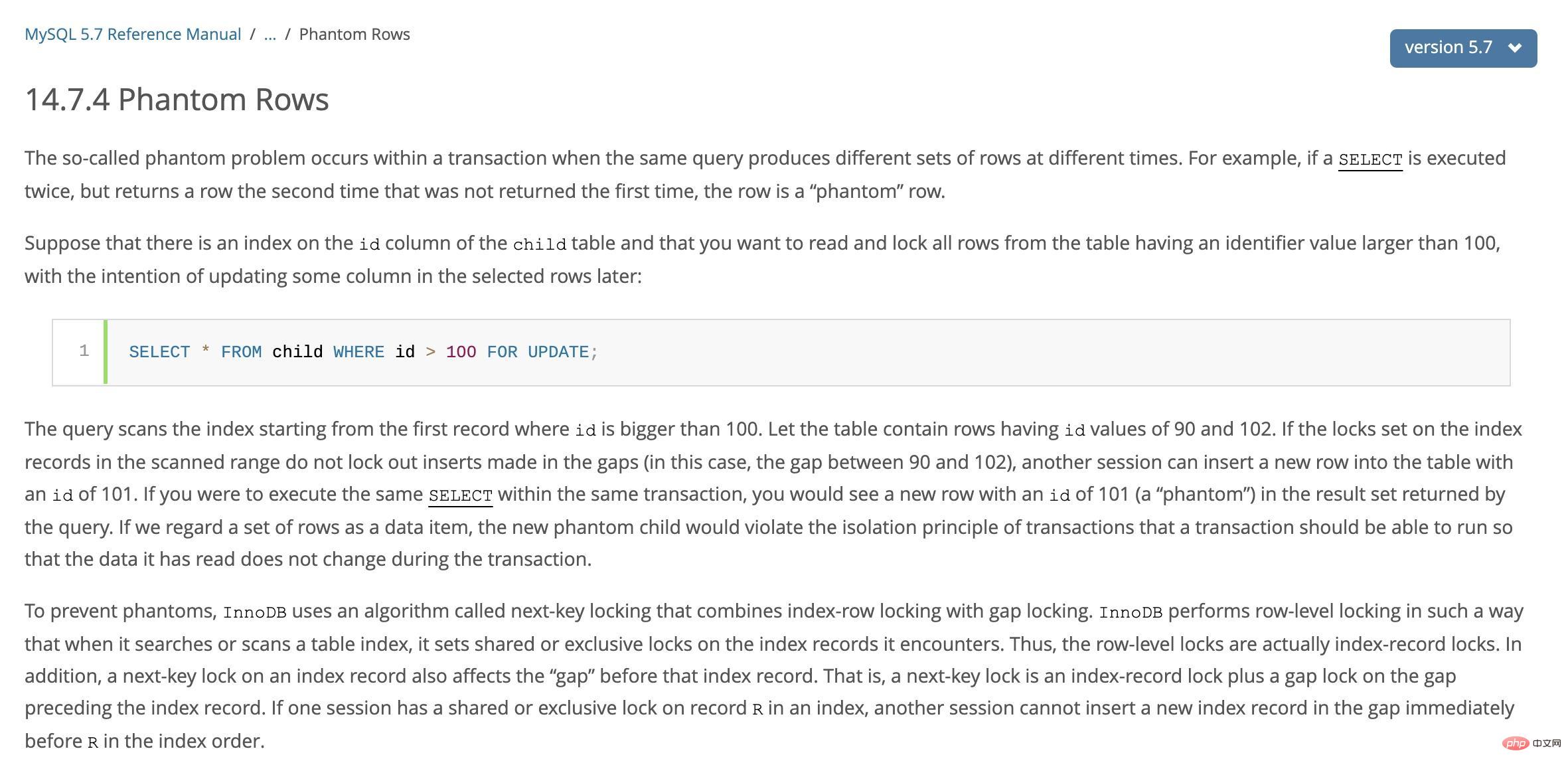
Phantom-Lesung und Next-Key-Sperre
Aktuelles Lesen und Snapshot-Lesen
Durch den MVCC-Mechanismus werden die Daten zwar wiederholbar, die von uns gelesenen Daten können jedoch historische Daten sein , keine aktuellen Daten, nicht die aktuellen Daten in der Datenbank! Diese Art des Lesens historischer Daten nennen wir Snapshot Read (Snapshot Read), und die Art des Lesens der aktuellen Version der Datenbankdaten nennen wir current Read (aktuelles Lesen) Reference[3]
Snapshot-Lesevorgang: Wählen Sie * aus der Tabelle aus. Aktueller Lesevorgang: Spezielle Lesevorgänge, Einfüge-/Aktualisierungs-/Löschvorgänge, gehören zum aktuellen Lesevorgang und werden derzeit verarbeitet muss gesperrt werden.
Wählen Sie * aus der Tabelle, wo ? im Freigabemodus.
- Einfügen
- zu lösen, verwenden MySQL-Transaktionen die Next-Key-Sperre.
In Ordnung Um das Phantom-Lese-Problem beim aktuellen LesenWiederholbares Lesen vermeidet Phantomlesen durch den Sperrmechanismus für die nächste Taste.
InnoDB-Speicher-Engine verfügt über drei Zeilensperralgorithmen:
Datensatzsperre: Sperren eines einzelnen Datensatzes Lückensperre: Lückensperre, sperrt einen Bereich, schließt den Datensatz jedoch nicht ein Next-Key-Sperre: Lückensperre + Datensatzsperre Next-Key-Sperre ist eine Art Zeilensperre, die der Datensatzsperre + Lückensperre entspricht. Ihr Merkmal besteht darin, dass sie nicht nur den Datensatz selbst sperrt (die Funktion). der Datensatzsperre) und auch einen Bereich sperren (die Funktion der Lückensperre).
Wenn InnoDB den Indexdatensatz scannt, fügt es zunächst eine Zeilensperre (Record Lock) zum Indexdatensatz und dann eine Lückensperre (Gap Lock) zur Lücke auf beiden Seiten des Indexdatensatzes hinzu. Nach dem Hinzufügen der Lückensperre können andere Transaktionen keine Datensätze in dieser Lücke ändern oder einfügen.
Wenn der abgefragte Index eindeutige Attribute enthält, wird die Next-Key-Sperre optimiert und auf Record Lock herabgestuft, wodurch nur der Index selbst, nicht der Bereich, gesperrt wird.



Das obige ist der detaillierte Inhalt vonEin kurzes Verständnis von MySQL-Sperren, Transaktionen und MVCC. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!