Verstehen Sie den Assoziationsregel-Apriori-Algorithmus: Der Apriori-Algorithmus ist der erste Assoziationsregel-Mining-Algorithmus und der klassischste Algorithmus. Er verwendet eine iterative Methode der schichtweisen Suche, um die Beziehung zwischen Elementmengen in der Datenbank zu finden und Regeln zu bilden . Der Prozess besteht aus Verbindungen. Er besteht aus [matrixähnlichen Operationen] und Bereinigung [Entfernen unnötiger Zwischenergebnisse].

Den Assoziationsregel-Apriori-Algorithmus verstehen:
1. Konzept
Tabelle 1 Transaktionsdatenbank eines Supermarkts
Transaktionsnummer TID | Von Kunden gekaufte Artikel | Transaktionsnummer TID
|
Vom Kunden gekaufte Artikel |
T1 |
Brot, Sahne, Milch, Tee |
T6 |
Brot , Tee |
|
T2 |
Brot, Sahne, Milch |
T7 |
Bier, Milch, Tee |
T3 |
Kuchen, Milch |
T8
|
Brot, Tee |
T4 |
Milch, Tee |
T9 |
Brot, Sahne, Milch, Tee |
|
T5 |
Brot, Kuchen, Milch |
T10 |
Brot, Milch, Tee |
Definition 1: Sei I={i1,i2,…,im}, was eine Menge von m verschiedenen Projekten ist, und jedes ik wird als Projekt bezeichnet. Eine Sammlung I von Elementen wird als itemset bezeichnet. Die Anzahl seiner Elemente wird als Länge des Itemsets bezeichnet, und ein Itemset mit der Länge k wird als k-Itemset bezeichnet. Im Beispiel ist jedes Produkt ein Artikel, die Artikelmenge ist I={Brot, Bier, Kuchen, Sahne, Milch, Tee} und die Länge von I beträgt 6.
Definition 2: Jede TransaktionT ist eine Teilmenge der Artikelmenge I. Für jede Transaktion gibt es eine eindeutige Identifikationstransaktionsnummer, die als TID aufgezeichnet wird. Alle Transaktionen bilden die TransaktionsdatenbankD, und |D| entspricht der Anzahl der Transaktionen in D. Das Beispiel enthält 10 Transaktionen, also |D|=10.
Definition 3: Für Itemset X setze count(X⊆T) auf die Anzahl der Transaktionen, die support(X)=count(X⊆T)/|D|Im Beispiel erscheint X={Brot, Milch} in T1, T2, T5, T9 und T10, sodass die Unterstützung 0,5 beträgt.
Definition vier
:
Minimale Unterstützung ist der minimale Unterstützungsschwellenwert des Itemsets, aufgezeichnet als SUPmin, der die minimale Bedeutung der Zuordnungsregeln darstellt, die den Benutzern wichtig sind. Elementmengen, deren Unterstützung nicht weniger als SUPmin beträgt, werden als häufige Mengen bezeichnet, und häufige Mengen mit der Länge k werden als k-häufige Mengen bezeichnet. Wenn SUPmin auf 0,3 gesetzt ist, beträgt die Unterstützung von {Brot, Milch} im Beispiel 0,5, es handelt sich also um einen 2-häufigen Satz. Definition fünf:
Assoziationsregel ist eine Implikation: R: . Gibt an, dass, wenn der Artikelsatz X in einer bestimmten Transaktion erscheint, auch Y mit einer bestimmten Wahrscheinlichkeit erscheint. Verbandsregeln, die den Benutzern am Herzen liegen, können an zwei Maßstäben gemessen werden: Unterstützung und Glaubwürdigkeit. Definition 6
: Die
Unterstützung
einer Assoziationsregel
R ist das Verhältnis der Anzahl der Transaktionen, die der Transaktionssatz sowohl X als auch Y enthält, zu |D|. Das heißt: support(X⇒Y)=count(X⋃Y)/|D|Support spiegelt die Wahrscheinlichkeit wider, dass X und Y gleichzeitig auftreten. Die Unterstützung von Assoziationsregeln entspricht der Unterstützung häufiger Mengen. Definition 7
: Für die Assoziationsregel
R bezieht sich
Glaubwürdigkeit
auf das Verhältnis der Anzahl der Transaktionen, die X und Y enthalten, zur Anzahl der Transaktionen, die X enthalten. Das heißt: Konfidenz(X⇒Y)=Unterstützung(X⇒Y)/Unterstützung(X)Konfidenz spiegelt die Wahrscheinlichkeit wider, dass die Transaktion Y enthält, wenn X in der Transaktion enthalten ist. Generell sind für Nutzer nur Vereinsregeln mit hoher Unterstützung und Glaubwürdigkeit von Interesse. Definition 8: Legen Sie die Mindestunterstützung und Mindestglaubwürdigkeit der Verbandsregeln als SUPmin und CONFmin fest. Wenn die Unterstützung und Glaubwürdigkeit der Regel R nicht geringer als SUPmin und CONFmin sind, spricht man von einer „starken Assoziationsregel“. Der Zweck des Association Rule Mining besteht darin, starke Assoziationsregeln zu finden, die den Händlern bei der Entscheidungsfindung helfen.
Diese acht Definitionen umfassen mehrere wichtige Grundkonzepte im Zusammenhang mit Assoziationsregeln. Es gibt zwei Hauptprobleme beim Assoziationsregel-Mining:
- Suchen Sie alle häufigen Itemsets in der Transaktionsdatenbank, die größer oder gleich der vom Benutzer angegebenen Mindestunterstützung sind.
- Verwenden Sie häufige Elementsätze, um die erforderlichen Assoziationsregeln zu generieren, und filtern Sie starke Assoziationsregeln basierend auf der vom Benutzer festgelegten Mindestglaubwürdigkeit heraus.
Derzeit untersuchen Forscher hauptsächlich das erste Problem. Es ist schwierig, häufige Mengen zu finden, aber es ist relativ einfach, starke Assoziationsregeln mit häufigen Mengen neu zu generieren.
2. Theoretische Grundlagen
Betrachten wir zunächst die Eigenschaften einer häufigen Menge.
Theorem: Wenn die Elementmenge X eine häufige Menge ist, dann sind ihre nicht leeren Teilmengen alle häufige Mengen .
Nach dem Satz unterscheiden sich bei gegebener Itemmenge Dies beweist, dass die k-Kandidatenmenge, die durch die Verkettung von k-1 häufigen Mengen erzeugt wird, die k-häufige Menge abdeckt. Wenn gleichzeitig die Itemmenge Y in der k-Kandidatenmenge eine k-1-Ordnungsteilmenge enthält, die nicht zur k-1-häufigen Menge gehört, kann Y keine häufige Menge sein und sollte aus der Kandidatenmenge entfernt werden. Der Apriori-Algorithmus macht sich diese Eigenschaft häufiger Mengen zunutze.
3. Algorithmusschritte:
Zuerst sind die Testdaten:
Transaktions-ID | Produkt-ID Liste T100 I 3 |
|
T400 |
I1, I2, I4 |
|
T500 |
I1, I3 |
|
T600 |
I2, I3 |
| T700 |
I1, I3 |
|
T800 |
I1,I2,I3,I5 |
| T90 0
|
I1,I2,I3
|
Schrittdiagramm des Algorithmus:
Es ist zu erkennen, dass der Kandidatensatz in der dritten Runde deutlich reduziert wurde.
Bitte beachten Sie die beiden Bedingungen für die Auswahl von Kandidatensätzen:
1 Die beiden Bedingungen für die Verbindung zweier K-Artikelsätze sind, dass sie über gleiche K-1-Artikel verfügen. Daher können (I2, I4) und (I3, I5) nicht verbunden werden. Der Kandidatensatz wird eingegrenzt.
2. Wenn es sich bei einer Artikelmenge um eine häufige Menge handelt, gibt es keine häufige Menge, die keine Teilmenge ist. Beispielsweise erhalten (I1, I2) und (I1, I4) (I1, I2, I4) und die Teilmenge (I1, I4) von (I1, I2, I4) ist keine häufige Menge. Der Kandidatensatz wird eingegrenzt.
Die in der dritten Runde erhaltenen
2 Kandidatensätze haben genau die Unterstützung, die der Mindestunterstützung entspricht. Daher sind sie alle in häufigen Sets enthalten. Schauen Sie sich nun den Kandidatensatz und die häufigen Satzergebnisse der vierten Runde an
sind leerSie können sehen, dass der Kandidatensatz und der häufige Satz tatsächlich leer sind! Weil die durch die dritte Runde erhaltenen häufigen Mengen selbstverbunden sind, um
{I1, I2, I3, I5} zu erhalten, das die Teilmenge {I2, I3, I5} hat und {I2, I3, I5} nicht häufig ist Menge und erfüllt nicht: Die Teilmenge häufiger Mengen hat auch die Bedingung häufiger Mengen, sodass sie durch Beschneiden entfernt werden. Daher wird der gesamte Algorithmus beendet und der zuletzt berechnete häufige Satz wird als endgültiges Ergebnis des häufigen Satzes verwendet: Das heißt:
['I1,I2,I3', 'I1,I2,I5'] 4 . Code:
Schreiben Sie Python-Code, um den Apriori-Algorithmus zu implementieren. Der Code muss die folgenden zwei Punkte beachten:
Da der Apriori-Algorithmus davon ausgeht, dass die Elemente im Itemset in lexikografischer Reihenfolge sortiert sind und das Set selbst ungeordnet ist, müssen wir Set und List bei Bedarf konvertieren
Da es notwendig ist, ein Wörterbuch (support_data) zum Aufzeichnen der Unterstützung eines Elementsatzes zu verwenden, muss der Elementsatz als Schlüssel verwendet werden, und der Variablensatz kann nicht als Schlüssel des Wörterbuchs verwendet werden, daher sollte der Elementsatz in konvertiert werden ein fester Satz, eingefrorener Satz zum richtigen Zeitpunkt. -
def local_data(file_path): import pandas as pd
dt = pd.read_excel(file_path)
data = dt['con']
locdata = [] for i in data:
locdata.append(str(i).split(",")) # print(locdata) # change to [[1,2,3],[1,2,3]]
length = [] for i in locdata:
length.append(len(i)) # 计算长度并存储
# print(length)
ki = length[length.index(max(length))] # print(length[length.index(max(length))]) # length.index(max(length)读取最大值的位置,然后再定位取出最大值
return locdata,kidef create_C1(data_set): """
Create frequent candidate 1-itemset C1 by scaning data set.
Args:
data_set: A list of transactions. Each transaction contains several items.
Returns:
C1: A set which contains all frequent candidate 1-itemsets """
C1 = set() for t in data_set: for item in t:
item_set = frozenset([item])
C1.add(item_set) return C1def is_apriori(Ck_item, Lksub1): """
Judge whether a frequent candidate k-itemset satisfy Apriori property.
Args:
Ck_item: a frequent candidate k-itemset in Ck which contains all frequent
candidate k-itemsets.
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
Returns:
True: satisfying Apriori property.
False: Not satisfying Apriori property. """
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item]) if sub_Ck not in Lksub1: return False return Truedef create_Ck(Lksub1, k): """
Create Ck, a set which contains all all frequent candidate k-itemsets
by Lk-1's own connection operation.
Args:
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
k: the item number of a frequent itemset.
Return:
Ck: a set which contains all all frequent candidate k-itemsets. """
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1) for i in range(len_Lksub1): for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort() if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j] # pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item) return Ckdef generate_Lk_by_Ck(data_set, Ck, min_support, support_data): """
Generate Lk by executing a delete policy from Ck.
Args:
data_set: A list of transactions. Each transaction contains several items.
Ck: A set which contains all all frequent candidate k-itemsets.
min_support: The minimum support.
support_data: A dictionary. The key is frequent itemset and the value is support.
Returns:
Lk: A set which contains all all frequent k-itemsets. """
Lk = set()
item_count = {} for t in data_set: for item in Ck: if item.issubset(t): if item not in item_count:
item_count[item] = 1 else:
item_count[item] += 1
t_num = float(len(data_set)) for item in item_count: if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num return Lkdef generate_L(data_set, k, min_support): """
Generate all frequent itemsets.
Args:
data_set: A list of transactions. Each transaction contains several items.
k: Maximum number of items for all frequent itemsets.
min_support: The minimum support.
Returns:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support. """
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1) for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1) return L, support_datadef generate_big_rules(L, support_data, min_conf): """
Generate big rules from frequent itemsets.
Args:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
min_conf: Minimal confidence.
Returns:
big_rule_list: A list which contains all big rules. Each big rule is represented
as a 3-tuple. """
big_rule_list = []
sub_set_list = [] for i in range(0, len(L)): for freq_set in L[i]: for sub_set in sub_set_list: if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf) if conf >= min_conf and big_rule not in big_rule_list: # print freq_set-sub_set, " => ", sub_set, "conf: ", conf big_rule_list.append(big_rule)
sub_set_list.append(freq_set) return big_rule_listif __name__ == "__main__": """
Test """
file_path = "test_aa.xlsx"
data_set,k = local_data(file_path)
L, support_data = generate_L(data_set, k, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.4) print(L) for Lk in L: if len(list(Lk)) == 0: break
print("="*50) print("frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport") print("="*50) for freq_set in Lk: print(freq_set, support_data[freq_set]) print() print("Big Rules") for item in big_rules_list: print(item[0], "=>", item[1], "conf: ", item[2])
Dateiformat: test_aa.xlsx
name con
T1 2,3,5T2 1,2,4T3 3,5T5 2,3,4T6 2,3,5T7 1,2,4T8 3,5T9 2,3,4T10 1,2,3,4,5
Zugehörige kostenlose Lernempfehlungen: Python-Video-Tutorial
Das obige ist der detaillierte Inhalt vonWie man den Assoziationsregel-Apriori-Algorithmus versteht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



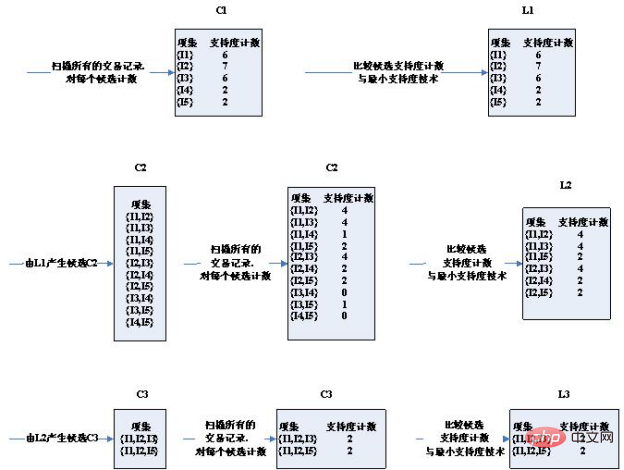 Es ist zu erkennen, dass der Kandidatensatz in der dritten Runde deutlich reduziert wurde.
Es ist zu erkennen, dass der Kandidatensatz in der dritten Runde deutlich reduziert wurde.