
Heim >Backend-Entwicklung >C#.Net-Tutorial >Welche Dateien werden nach dem Kompilieren in C-Sprache generiert?
Welche Dateien werden nach dem Kompilieren in C-Sprache generiert?

- 青灯夜游Original
- 2020-10-22 19:15:1321717Durchsuche
C-Sprache wird kompiliert, um eine „.OBJ“-Binärdatei zu generieren. Nachdem das C-Sprachquellprogramm vom C-Sprachcompiler kompiliert wurde, wird eine Binärdatei mit dem Suffix „.OBJ“ generiert. Schließlich kombiniert eine Software namens „Linker“ diese „.OBJ“-Datei mit verschiedenen Programmen, die von bereitgestellt werden C-Sprache. Die Bibliotheksfunktionen werden miteinander verbunden, um eine Datei mit der Endung „.EXE“ zu generieren.

Nachdem das C-Sprachquellprogramm vom C-Sprachcompiler kompiliert wurde, wird eine Binärdatei (Objektdatei genannt) mit dem Suffix „.OBJ“ generiert und schließlich von einem Programm namens „ verarbeitet. „Link“ Die Software verbindet diese „.OBJ“-Datei mit verschiedenen Bibliotheksfunktionen der C-Sprache, um eine ausführbare Datei mit der Endung „.EXE“ zu generieren. Offensichtlich kann die C-Sprache nicht sofort ausgeführt werden.
Empfohlenes Tutorial: „c-Sprach-Tutorial-Video“
CDie vier Phasen der Kompilierung und Ausführung von Sprachdateien werden separat beschrieben.
CDer Kompilierungs- und Verknüpfungsprozess der Sprache erfordert uns Um ein geschriebenes c-Programm (Quellcode) in ein Programm (ausführbaren Code) umzuwandeln, das auf der Hardware ausgeführt werden kann, muss es kompiliert und verknüpft werden. Beim Kompilieren handelt es sich um den Prozess der Übersetzung von Quellcode in Textform in Objektdateien in Maschinenspracheform. Beim Verknüpfen werden Zieldateien, Betriebssystem-Startcode und verwendete Bibliotheksdateien organisiert, um schließlich ausführbaren Code zu generieren. Das Prozessdiagramm sieht wie folgt aus:
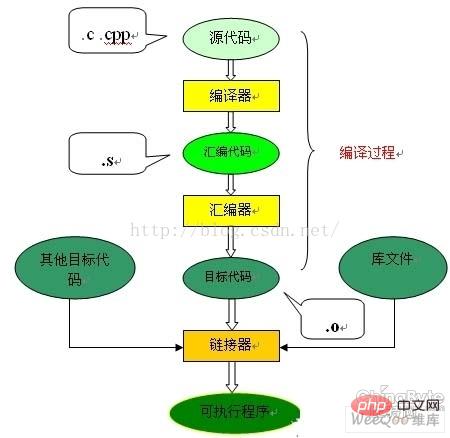
Wie Sie auf dem Bild sehen können, ist der Kompilierungsprozess des gesamten Codes in zwei Prozesse unterteilt: Kompilierung und Verknüpfung entsprechen dem in geschweiften Klammern eingeschlossenen Teil die Figur, und der Rest ist der Verknüpfungsprozess.
Kompilierungsprozess
Der Kompilierungsprozess kann in zwei Phasen unterteilt werden: Kompilierung und Montage.
Kompilierung
Bei der Kompilierung wird das Quellprogramm (Zeichenstrom) gelesen, eine lexikalische und syntaktische Analyse durchgeführt und hochsprachliche Anweisungen in funktional äquivalenten Assemblercode umgewandelt. Der Kompilierungsprozess von Quelldateien umfasst zwei Hauptphasen:
Die erste Stufe ist die Vorverarbeitungsstufe, die vor der formalen Kompilierungsstufe durchgeführt wird. In der Vorverarbeitungsphase wird der Inhalt der Quelldatei basierend auf den in der Datei platzierten Vorverarbeitungsanweisungen geändert. Beispielsweise ist die Anweisung #include eine Vorverarbeitungsanweisung, die den Inhalt der Header-Datei zur Datei .cpp hinzufügt. Diese Methode zum Ändern von Quelldateien vor der Kompilierung bietet große Flexibilität bei der Anpassung an die Einschränkungen verschiedener Computer- und Betriebssystemumgebungen. Der für eine Umgebung erforderliche Code kann sich von dem für eine andere Umgebung erforderlichen Code unterscheiden, da die verfügbare Hardware oder die Betriebssysteme unterschiedlich sind. In vielen Fällen können Sie Code für verschiedene Umgebungen in derselben Datei ablegen und den Code dann während der Vorverarbeitungsphase ändern, um ihn an die aktuelle Umgebung anzupassen. Behandelt hauptsächlich die folgenden Aspekte:
(1) Makrodefinitionsanweisungen, wie #define a b Für diese Art von Pseudoanweisung muss die Vorkompilierung lediglich alle a im Programm durch b ersetzen, aber a als Stringkonstante wird nicht ersetzt. Es gibt auch #undef, das die Definition eines bestimmten Makros aufhebt, sodass zukünftige Vorkommen der Zeichenfolge nicht mehr ersetzt werden. (2) Bedingte Kompilierungsanweisungen, wie #ifdef, #ifndef, #else, #elif, #endif usw. Die Einführung dieser Pseudoanweisungen ermöglicht es Programmierern, durch die Definition verschiedener Makros zu entscheiden, welche Codes vom Compiler verarbeitet werden sollen. Der Precompiler filtert unnötigen Code basierend auf relevanten Dateien heraus. (3) Die Header-Datei enthält Anweisungen wie #include 'FileName' oder #include usw. In Header-Dateien werden Pseudoanweisungen #define im Allgemeinen verwendet, um eine große Anzahl von Makros zu definieren (am häufigsten sind Zeichenkonstanten) und enthalten auch Deklarationen verschiedener externer Symbole. Der Zweck der Verwendung von Header-Dateien besteht hauptsächlich darin, bestimmte Definitionen mehreren verschiedenen C-Quellprogrammen zur Verfügung zu stellen. Denn im C-Quellprogramm, das diese Definitionen verwenden muss, müssen Sie nur eine #include-Anweisung hinzufügen, ohne diese Definitionen in dieser Datei wiederholen zu müssen. Der Precompiler fügt alle Definitionen in der Header-Datei zur Ausgabedatei hinzu, die er zur Verarbeitung durch den Compiler generiert. Die im c-Quellprogramm enthaltenen Header-Dateien können vom System bereitgestellt werden. Diese Header-Dateien werden im Allgemeinen im Verzeichnis /usr/include abgelegt. Im Programm #include verwenden sie spitze Klammern (< >). Darüber hinaus können Entwickler auch ihre eigenen Header-Dateien definieren. Diese Dateien werden im Allgemeinen im selben Verzeichnis wie das c-Quellprogramm abgelegt. In diesem Fall sollten in #include doppelte Anführungszeichen verwendet werden. ( ) Spezielle Symbole, der Precompiler kann einige spezielle Symbole erkennen. Zum Beispiel wird das im Quellprogramm erscheinende -Logo als aktuelle Zeilennummer (Dezimalzahl) interpretiert und FILE wird als Name des aktuell kompilierten C-Quellprogramms interpretiert. Der Precompiler ersetzt Vorkommen dieser Zeichenfolgen im Quellprogramm durch entsprechende Werte. Der Precompiler „ersetzt“ im Grunde das Quellprogramm. Nach dieser Ersetzung wird eine Ausgabedatei ohne Makrodefinitionen, ohne Anweisungen zur bedingten Kompilierung und ohne spezielle Symbole generiert. Die Bedeutung dieser Datei ist dieselbe wie die der nicht vorverarbeiteten Quelldatei, der Inhalt ist jedoch unterschiedlich. Anschließend wird diese Ausgabedatei als Ausgabe des Compilers in Maschinenanweisungen übersetzt. In der zweiten Stufe der Kompilierung und Optimierung enthält die vorkompilierte Ausgabedatei nur Konstanten wie Zahlen, Zeichenfolgen, Variablendefinitionen und C-Sprachschlüsselwörter wie main, if, else , for, while, {,}, +, -, *, und so weiter. Die Arbeit des Compilers besteht darin, mithilfe der lexikalischen Analyse und der Syntaxanalyse zu bestätigen, dass alle Anweisungen den grammatikalischen Regeln entsprechen, und sie dann in eine entsprechende Zwischencodedarstellung oder einen Assemblercode zu übersetzen. Die Optimierungsverarbeitung ist eine relativ schwierige Technologie im Kompilierungssystem. Die damit verbundenen Probleme hängen nicht nur mit der Kompilierungstechnologie selbst zusammen, sondern haben auch viel mit der Hardwareumgebung der Maschine zu tun. Ein Teil der Optimierung ist die Optimierung des Zwischencodes. Diese Optimierung ist unabhängig vom jeweiligen Rechner. Eine andere Art der Optimierung zielt hauptsächlich auf die Generierung von Zielcode ab. Bei der früheren Optimierung besteht die Hauptarbeit darin, öffentliche Ausdrücke zu löschen, Schleifenoptimierung (Codeextraktion, Stärkeschwächung, Änderung der Schleifensteuerungsbedingungen, Zusammenführung bekannter Mengen usw.), Kopierweitergabe und Löschung nutzloser Zuweisungen usw. Warten. Die letztgenannte Art der Optimierung hängt eng mit der Hardwarestruktur der Maschine zusammen. Die wichtigste Überlegung besteht darin, die in jedem Hardwareregister der Maschine gespeicherten Werte relevanter Variablen vollständig zu nutzen, um die Speicherkapazität zu reduzieren Zugriffe. Darüber hinaus erfahren Sie, wie Sie einige Anpassungen an den Anweisungen entsprechend den Eigenschaften der Maschinenhardware-Ausführungsanweisung (z. B. Pipeline, RISC, CISC, VLIW usw.) vornehmen, um den Zielcode und die Ausführung kürzer zu machen Effizienzsteigerung ist ebenfalls ein wichtiges Forschungsthema. Assembly Assembly bezieht sich eigentlich auf den Prozess der Übersetzung von Assembler-Code in Zielmaschinenanweisungen. Für jedes vom Übersetzungssystem verarbeitete C-Sprachquellprogramm wird durch diese Verarbeitung schließlich die entsprechende Zieldatei erhalten. Was in der Zieldatei gespeichert ist, ist der Maschinensprachencode des Ziels, der dem Quellprogramm entspricht. Objektdateien bestehen aus Segmenten. Normalerweise gibt es in einer Objektdatei mindestens zwei Abschnitte: Codeabschnitt: Dieser Abschnitt enthält hauptsächlich die Anweisungen des Programms. Dieses Segment ist im Allgemeinen lesbar und ausführbar, jedoch im Allgemeinen nicht beschreibbar. Datensegment: Speichert hauptsächlich verschiedene globale Variablen oder statische Daten, die im Programm verwendet werden. Im Allgemeinen sind Datensegmente lesbar, beschreibbar und ausführbar. UNIXEs gibt drei Haupttypen von Objektdateien: (1) Verschiebbare Dateien , die Code enthalten, der zum Verknüpfen mit anderen Objektdateien geeignet ist, um eine ausführbare oder gemeinsam genutzte Objektdatei und Daten zu erstellen. (2)Shared-Object-Datei Diese Datei speichert Code und Daten, die für die Verknüpfung in zwei Kontexten geeignet sind. Der erste besteht darin, dass der Linker sie mit anderen verschiebbaren Dateien und gemeinsam genutzten Objektdateien verarbeiten kann, um eine weitere Objektdatei zu erstellen. Der zweite besteht darin, dass der dynamische Linker sie mit einer anderen ausführbaren Datei und anderen gemeinsam genutzten Objektdateien verarbeiten kann Bild. (3) Ausführbare Datei Sie enthält eine Datei, die von einem vom Betriebssystem erstellten Prozess ausgeführt werden kann. Was der Assembler generiert, ist tatsächlich die erste Art von Objektdatei. Für die beiden letztgenannten ist eine andere Verarbeitung erforderlich, um sie zu erhalten. Dies ist die Aufgabe des Linkers. Verknüpfungsprozess Die vom Assembler generierte Objektdatei kann nicht sofort ausgeführt werden und es können viele ungelöste Probleme auftreten. Zum Beispiel kann eine Funktion in einer Quelldatei auf ein Symbol (z. B. eine Variable oder einen Funktionsaufruf usw.) verweisen, das in einer anderen Quelldatei definiert ist, und eine Funktion in einer Bibliotheksdatei kann im Programm usw. aufgerufen werden. Alle diese Probleme müssen vom Linker gelöst werden. Die Hauptaufgabe des Linkers besteht darin, verwandte Zieldateien miteinander zu verbinden, dh die in einer Datei referenzierten Symbole mit der Definition des Symbols in einer anderen Datei zu verbinden, sodass alle diese Zieldateien zu einer betriebsfähigen Einheit werden das Ganze, das das System lädt und ausführt. Entsprechend den vom Entwickler angegebenen unterschiedlichen Verknüpfungsmethoden derselben Bibliotheksfunktion kann die Verknüpfungsverarbeitung in zwei Typen unterteilt werden: (1) Statische Verknüpfung Bei dieser Verknüpfungsmethode wird der Code der Funktion verwendet von ihrem Speicherort aus statisch sein. Die verknüpfte Bibliothek wird in das endgültige ausführbare Programm kopiert. Auf diese Weise werden diese Codes bei der Ausführung des Programms in den virtuellen Adressraum des Prozesses geladen. Eine statische Linkbibliothek ist eigentlich eine Sammlung von Objektdateien, von denen jede den Code für eine oder eine Gruppe verwandter Funktionen in der Bibliothek enthält. (2) Dynamic Link Bei dieser Methode wird der Code der Funktion in einer Objektdatei abgelegt, die als Dynamic Link Library oder Shared Object bezeichnet wird. Zu diesem Zeitpunkt zeichnet der Linker den Namen des gemeinsam genutzten Objekts und eine kleine Menge anderer Registrierungsinformationen im endgültigen ausführbaren Programm auf. Wenn diese ausführbare Datei ausgeführt wird, wird der gesamte Inhalt der Dynamic Link Library zur Laufzeit dem virtuellen Adressraum des entsprechenden Prozesses zugeordnet. Der dynamische Linker findet den entsprechenden Funktionscode basierend auf den im ausführbaren Programm aufgezeichneten Informationen. Für Funktionsaufrufe in ausführbaren Dateien kann jeweils eine dynamische Verknüpfung oder eine statische Verknüpfung verwendet werden. Die Verwendung dynamischer Verknüpfungen kann die endgültige ausführbare Datei kürzer machen und etwas Speicher sparen, wenn ein gemeinsam genutztes Objekt von mehreren Prozessen verwendet wird, da nur eine Kopie des Codes für dieses gemeinsam genutzte Objekt im Speicher gespeichert werden muss. Dies bedeutet jedoch nicht unbedingt, dass die Verwendung dynamischer Links der Verwendung statischer Links überlegen ist. In einigen Fällen kann die dynamische Verknüpfung zu Leistungseinbußen führen. Der gcc-Compiler, den wir in linux verwenden, bündelt die oben genannten Prozesse, sodass Benutzer die Kompilierungsarbeit zwar mit nur einem Befehl abschließen können, aber für Anfänger ist das Kompilieren sehr ungünstig Das Bild unten zeigt den Kompilierungsprozess von gccagent: Wie Sie auf dem Bild oben sehen können: Vorkompilieren Konvertieren Sie .c-Dateien in .i-Dateien gcc-Befehl lautet: gcc –E Entspricht dem Vorverarbeitungsbefehl CPP Compile .c/.h .S -Dateien Der verwendete Befehl ist: GCC -S, der dem Befehl compilation cc –s entspricht Assembly .s-Dateien in Der verwendete gcc-Befehl lautet: gcc –c Der entsprechende Assembly-Befehl lautet Link o Dateien werden in ausführbare Programme konvertiert gcc gcc ld Zusammenfassend besteht der Kompilierungsprozess aus den oben genannten vier Prozessen: Vorkompilierung, Kompilierung , Montage ,Link. Lia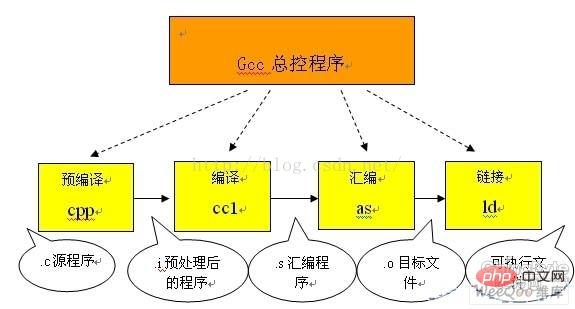
Das obige ist der detaillierte Inhalt vonWelche Dateien werden nach dem Kompilieren in C-Sprache generiert?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So finden Sie den Maximalwert in der C-Sprache
- Bei der Verwendung verschachtelter if-Anweisungen schreibt die C-Sprache vor, dass else immer was ist?
- Wie konvertiere ich Groß- und Kleinbuchstaben in der C-Sprache?
- Welches Programm sollte verwendet werden, um ein in C-Sprache geschriebenes Programm zu übersetzen, damit der Computer es erkennen kann?
- Wie man Macht in der C-Sprache ausdrückt