
Heim >Java >JavaInterview Fragen >Zusammenfassung der neuen Java-Grundlageninterviewfragen für 2020
Zusammenfassung der neuen Java-Grundlageninterviewfragen für 2020

- 王林nach vorne
- 2020-10-21 16:51:034577Durchsuche

Der Unterschied zwischen ==, equal und hashCode in Java
(Weitere Empfehlungen für Interviewfragen: Java-Interviewfragen und -antworten)
1. ==
Die Datentypen in Java können in zwei Kategorien unterteilt werden :
Grundlegende Datentypen, auch primitive Datentypen genannt Um Byte, Short, Char, Int, Long, Float, Double und Boolean zu vergleichen, verwenden Sie das doppelte Gleichheitszeichen (==) und vergleichen Sie ihre Werte.
Referenztyp (Klasse, Schnittstelle, Array) Wenn sie mit (==) vergleichen, vergleichen sie ihre Speicheradressen im Speicher. Daher ist das Ergebnis ihres Vergleichs wahr, es sei denn, es handelt sich um dasselbe neue Objekt, andernfalls ist das Ergebnis des Vergleichs falsch. Objekte werden auf dem Heap platziert und die Referenz (Adresse) des Objekts wird auf dem Stapel gespeichert. Schauen Sie sich zunächst die Speicherzuordnung und den Code der virtuellen Maschine an:
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
Das Ergebnis ist:
false
true

Sowohl s1 als auch s2 speichern jeweils die Adressen der entsprechenden Objekte. Wenn also s1 == s2 verwendet wird, werden die Adresswerte der beiden Objekte verglichen (dh ob die Referenzen gleich sind), was falsch ist. Beim Aufruf der Gleichheitsrichtung wird der Wert in der entsprechenden Adresse verglichen, sodass der Wert wahr ist. Hier müssen wir equal() im Detail beschreiben.
2. Detaillierte Erläuterung der Methode equal()
equals() wird verwendet, um zu bestimmen, ob andere Objekte diesem Objekt gleich sind. Es ist in Object definiert, sodass jedes Objekt über die Methode equal() verfügt. Der Unterschied besteht darin, ob die Methode überschrieben wird oder nicht.
Werfen wir zunächst einen Blick auf den Quellcode:
public boolean equals(Object obj) { return (this == obj);
}
Offensichtlich definiert Object einen Vergleich der Adresswerte zweier Objekte (also den Vergleich, ob die Referenzen gleich sind). Aber warum vergleicht der Aufruf von equal() in String nicht die Adresse, sondern den Wert in der Heap-Speicheradresse? Hier ist der entscheidende Punkt. Wenn Kapselungsklassen wie String, Math, Integer, Double usw. die Methode equal() verwenden, haben sie bereits die Methode equal() der Objektklasse behandelt. Schauen Sie sich das umgeschriebene equal() in String an:
public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}
Nach dem Umschreiben ist dies der Inhaltsvergleich und nicht mehr der vorherige Adressvergleich. Analog dazu überschreiben Math, Integer, Double und andere Klassen alle die Methode equal(), um Inhalte zu vergleichen. Natürlich führen Basistypen Wertevergleiche durch.
Es ist zu beachten, dass beim Überschreiben der Methode equal() auch hashCode() überschrieben wird. Gemäß der Implementierung der allgemeinen Methode hashCode() müssen gleiche Objekte gleiche Hashcodes haben. Warum ist das so? Hier müssen wir den Hashcode noch einmal kurz erwähnen.
3. Eine kurze Diskussion zu hashcode()
Es geht offensichtlich um den Unterschied zwischen ==, equal und hashCode in Java, aber warum hängt es plötzlich mit hashcode() zusammen? Sie müssen sehr deprimiert sein, okay, lassen Sie mich ein einfaches Beispiel geben und Sie werden wissen, warum HashCode beteiligt ist, wenn == oder gleich ist.
Lassen Sie uns ein Beispiel geben: Wenn Sie herausfinden möchten, ob eine Sammlung ein Objekt enthält, wie sollten Sie das Programm schreiben? Wenn Sie die indexOf-Methode nicht verwenden, durchlaufen Sie einfach die Sammlung und vergleichen Sie, ob Sie daran denken. Was wäre, wenn es 10.000 Elemente in der Sammlung gäbe, wäre das doch ermüdend, oder? Um die Effizienz zu verbessern, wurde der Hash-Algorithmus geboren. Die Kernidee besteht darin, die Sammlung in mehrere Speicherbereiche zu unterteilen (kann als Buckets betrachtet werden) und kann entsprechend dem Hash-Code gruppiert werden. Ein Objekt kann nach dem Hash-Code gruppiert werden. Sein Hash-Code kann in verschiedene Speicherbereiche (unterschiedliche Bereiche) unterteilt werden.
Beim Vergleichen von Elementen wird also tatsächlich zuerst der Hashcode verglichen, und wenn sie gleich sind, wird die Gleichheitsmethode verglichen.
Sehen Sie sich das Hashcode-Diagramm an:

Ein Objekt hat im Allgemeinen einen Schlüssel und einen Wert. Sein HashCode-Wert kann basierend auf dem Schlüssel berechnet und dann basierend auf seinem HashCode-Wert in verschiedenen Speicherbereichen gespeichert werden in der Abbildung oben dargestellt. Verschiedene Bereiche können mehrere Werte speichern, da es zu Hash-Konflikten kommt. Ganz einfach: Wenn der HashCode zweier verschiedener Objekte gleich ist, spricht man von einem Hash-Konflikt. Einfach ausgedrückt bedeutet dies, dass der Hashcode derselbe ist, Equals jedoch ein anderer Wert ist. Für den Vergleich von 10.000 Elementen ist es nicht erforderlich, die gesamte Sammlung zu durchlaufen. Sie müssen lediglich den HashCode des Schlüssels des gesuchten Objekts berechnen und dann den dem HashCode entsprechenden Speicherbereich finden.

大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。再重写了equals最好把hashCode也重写。其实这是一条规范,如果不这样做程序也可以执行,只不过会隐藏bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,那么重写equals后最好也重写hashCode。
总结:
- hashCode是为了提高在散列结构存储中查找的效率,在线性表中没有作用。
- equals重写的时候hashCode也跟着重写
- 两对象equals如果相等那么hashCode也一定相等,反之不一定。
2. int、char、long 各占多少字节数
byte 是 字节
bit 是 位
1 byte = 8 bit
char在java中是2个字节,java采用unicode,2个字节来表示一个字符
short 2个字节
int 4个字节
long 8个字节
float 4个字节
double 8个字节
3. int和Integer的区别
- Integer是int的包装类,int则是java的一种基本数据类型
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- Integer的默认值是null,int的默认值是0
延伸: 关于Integer和int的比较
- 由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false
- Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true
- 非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false
- 对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100; Integer j = 100; System.out.print(i == j); //true
Integer i = 128; Integer j = 128; System.out.print(i == j); //false
对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <p>java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了</p><h2 class="heading" data-id="heading-6">4. java多态的理解</h2><h3 class="heading" data-id="heading-7">1.多态概述</h3><ol>
<li><p>多态是继封装、继承之后,面向对象的第三大特性。</p></li>
<li><p>多态现实意义理解:</p></li>
</ol>
现实事物经常会体现出多种形态,如学生,学生是人的一种,则一个具体的同学张三既是学生也是人,即出现两种形态。
Java作为面向对象的语言,同样可以描述一个事物的多种形态。如Student类继承了Person类,一个Student的对象便既是Student,又是Person。
多态体现为父类引用变量可以指向子类对象。
前提条件:必须有子父类关系。
注意:在使用多态后的父类引用变量调用方法时,会调用子类重写后的方法。
- 多态的定义与使用格式
定义格式:父类类型 变量名=new 子类类型();
2.多态中成员的特点
- 多态成员变量:编译运行看左边
Fu f=new Zi();
System.out.println(f.num);//f是Fu中的值,只能取到父中的值
- 多态成员方法:编译看左边,运行看右边
Fu f1=new Zi();
System.out.println(f1.show());//f1的门面类型是Fu,但实际类型是Zi,所以调用的是重写后的方法。
3.instanceof关键字
作用:用来判断某个对象是否属于某种数据类型。
* 注意: 返回类型为布尔类型
使用案例:
Fu f1=new Zi();
Fu f2=new Son();if(f1 instanceof Zi){
System.out.println("f1是Zi的类型");
}else{
System.out.println("f1是Son的类型");
}
4.多态的转型
多态的转型分为向上转型和向下转型两种
-
向上转型:多态本身就是向上转型过的过程
使用格式:父类类型 变量名=new 子类类型();
适用场景:当不需要面对子类类型时,通过提高扩展性,或者使用父类的功能就能完成相应的操作。
-
向下转型:一个已经向上转型的子类对象可以使用强制类型转换的格式,将父类引用类型转为子类引用各类型
使用格式:子类类型 变量名=(子类类型)父类类型的变量;
适用场景:当要使用子类特有功能时。
5.多态案例:
例1:
package day0524;
public class demo04 {
public static void main(String[] args) {
People p=new Stu();
p.eat();
//调用特有的方法
Stu s=(Stu)p;
s.study();
//((Stu) p).study();
}
}
class People{
public void eat(){
System.out.println("吃饭");
}
}
class Stu extends People{
@Override
public void eat(){
System.out.println("吃水煮肉片");
}
public void study(){
System.out.println("好好学习");
}
}
class Teachers extends People{
@Override
public void eat(){
System.out.println("吃樱桃");
}
public void teach(){
System.out.println("认真授课");
}
}
答案:吃水煮肉片 好好学习
例2:
请问题目运行结果是什么?
package day0524;
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}
答案:A B
5. String、StringBuffer和StringBuilder区别
1、长度是否可变
- String 是被 final 修饰的,他的长度是不可变的,就算调用 String 的concat 方法,那也是把字符串拼接起来并重新创建一个对象,把拼接后的 String 的值赋给新创建的对象
- StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象,StringBuffer 与 StringBuilder 中的方法和功能完全是等价的。调用StringBuffer 的 append 方法,来改变 StringBuffer 的长度,并且,相比较于 StringBuffer,String 一旦发生长度变化,是非常耗费内存的!
2、执行效率
- 三者在执行速度方面的比较:StringBuilder > StringBuffer > String
3、应用场景
- 如果要操作少量的数据用 = String
- 单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
- 多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
StringBuffer和StringBuilder区别
1、是否线程安全
- StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问),StringBuffer是线程安全的。只是StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
2、应用场景
- 由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。
- 然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。 append方法与直接使用+串联相比,减少常量池的浪费。
6. 什么是内部类?内部类的作用
内部类的定义
将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
内部类的作用:
成员内部类 成员内部类可以无条件访问外部类的所有成员属性和成员方法(包括private成员和静态成员)。 当成员内部类拥有和外部类同名的成员变量或者方法时,会发生隐藏现象,即默认情况下访问的是成员内部类的成员。
局部内部类 局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
匿名内部类 匿名内部类就是没有名字的内部类
静态内部类 指被声明为static的内部类,他可以不依赖内部类而实例,而通常的内部类需要实例化外部类,从而实例化。静态内部类不可以有与外部类有相同的类名。不能访问外部类的普通成员变量,但是可以访问静态成员变量和静态方法(包括私有类型) 一个 静态内部类去掉static 就是成员内部类,他可以自由的引用外部类的属性和方法,无论是静态还是非静态。但是不可以有静态属性和方法
(学习视频推荐:java课程)
7. Der Unterschied zwischen abstrakten Klassen und Schnittstellen
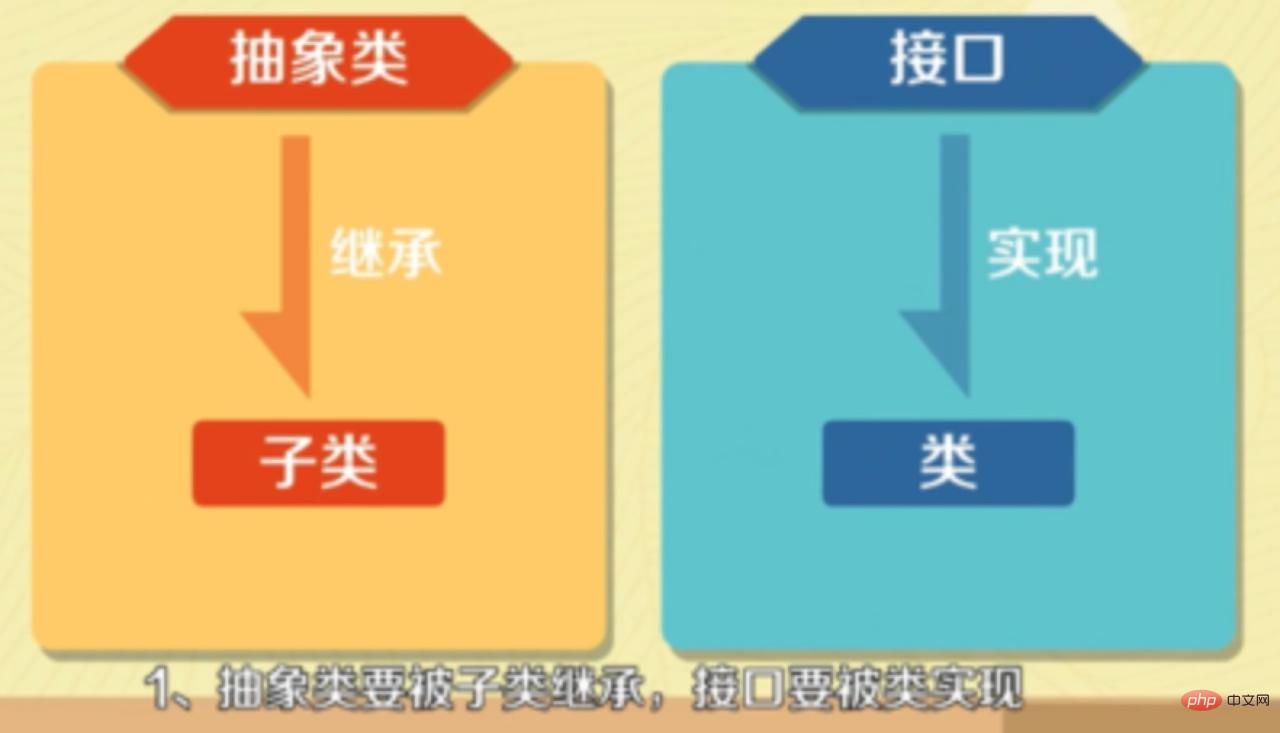
- Abstrakte Klassen müssen von Unterklassen geerbt werden und Schnittstellen müssen von Klassen implementiert werden.
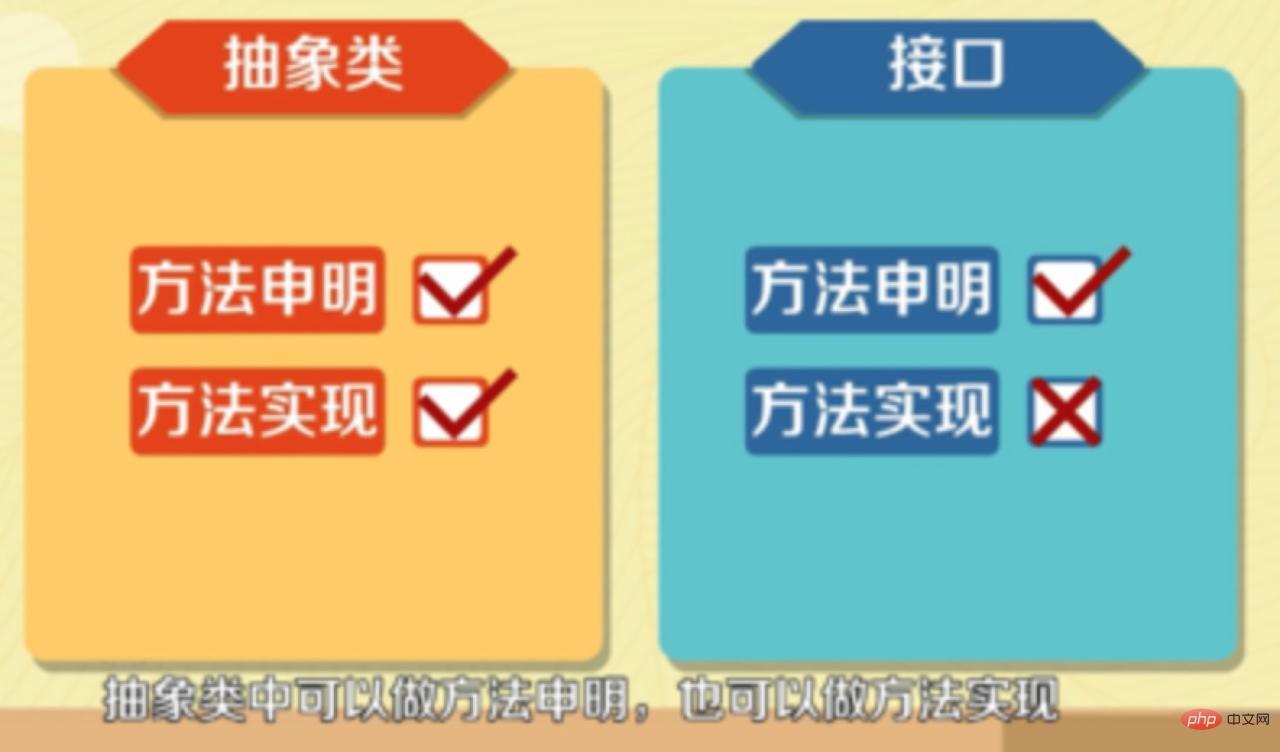
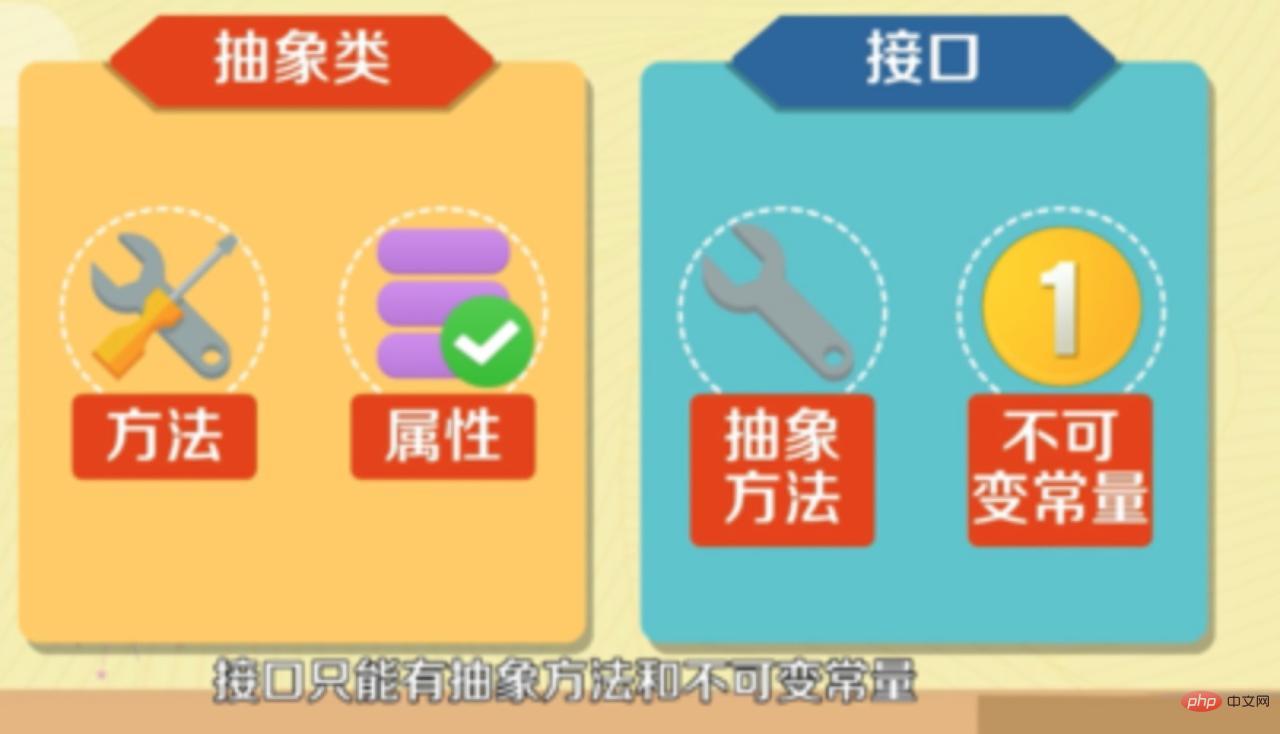
- Schnittstellen können nur Methodendeklarationen vornehmen, während abstrakte Klassen Methodendeklarationen und Methodenimplementierungen vornehmen können.
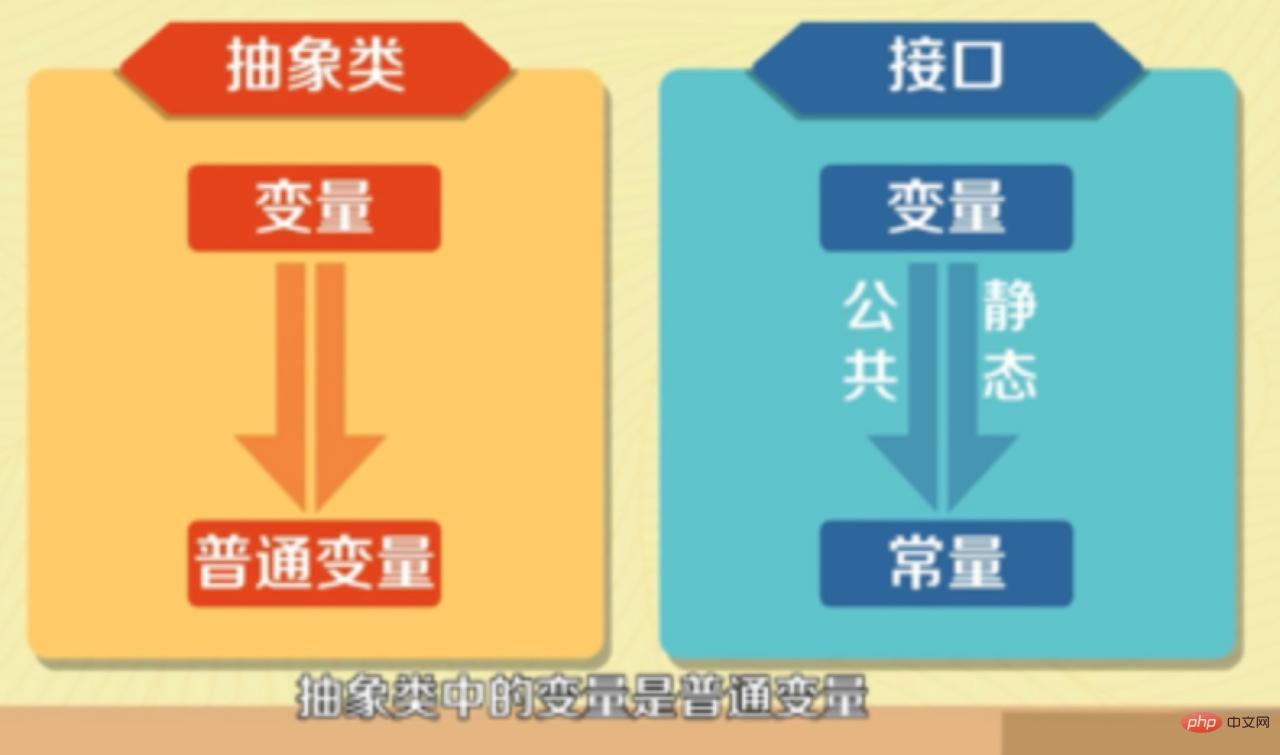
- In der Schnittstelle definierte Variablen können nur öffentliche statische Konstanten sein, und Variablen in abstrakten Klassen sind gewöhnliche Variablen.
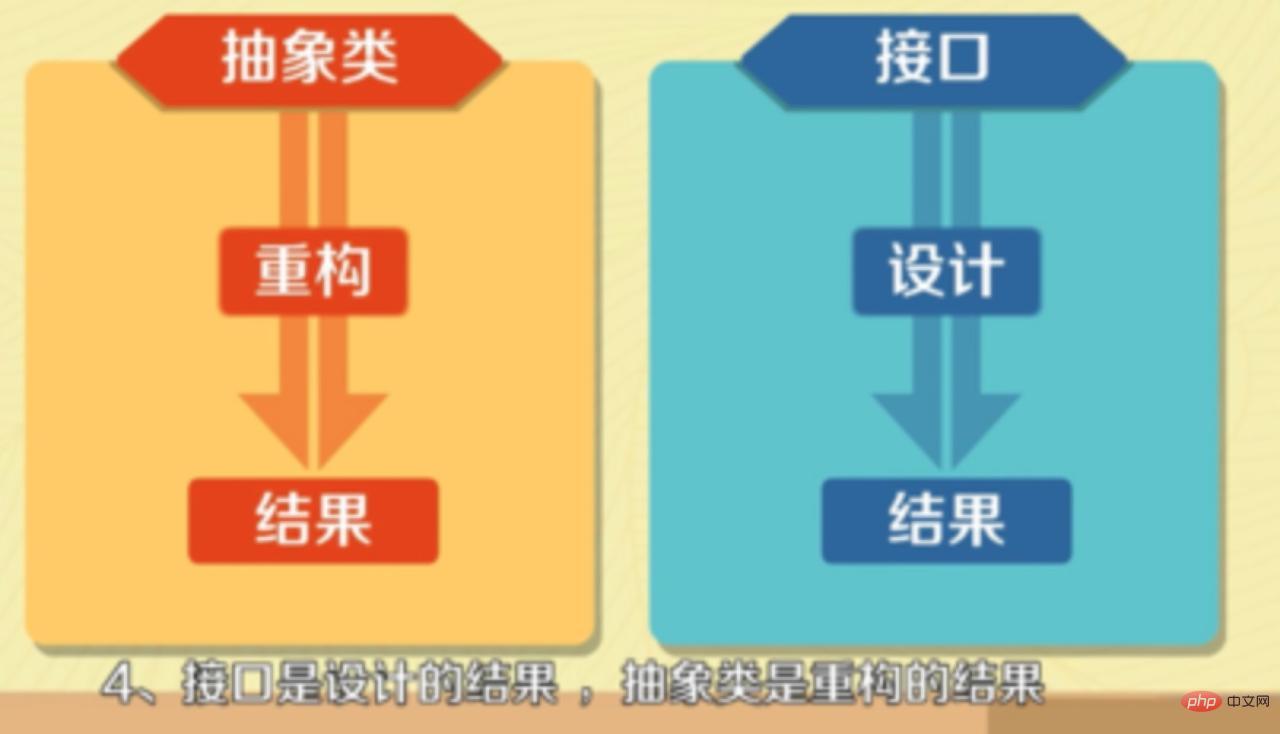
- Schnittstelle ist das Ergebnis von Design und abstrakte Klasse ist das Ergebnis von Refactoring.
- Abstrakte Klassen und Schnittstellen werden zum Abstrahieren bestimmter Objekte verwendet, Schnittstellen weisen jedoch die höchste Abstraktionsebene auf.
- Abstrakte Klassen können bestimmte Methoden und Eigenschaften haben, während Schnittstellen nur abstrakte Methoden und unveränderliche Konstanten haben können.
- Abstrakte Klassen werden hauptsächlich zum Abstrahieren von Kategorien verwendet, und Schnittstellen werden hauptsächlich zum Abstrahieren von Funktionen verwendet.
8. Die Bedeutung der abstrakten Klasse
Abstrakte Klasse: Wenn eine Klasse abstrakte Methoden enthält, sollte die Klasse mit dem Schlüsselwort abstract als abstrakte Klasse deklariert werden.
Bedeutung:
- Stellen Sie einen gemeinsamen Typ für Unterklassen bereit.
- Kapseln Sie wiederholte Inhalte (Mitgliedsvariablen und Methoden).
- 9. Anwendungsszenarien von abstrakten Klassen und Schnittstellen
1. Anwendungsszenarien von Schnittstellen:
Spezifische Schnittstellen werden für die Koordination zwischen Klassen benötigt, unabhängig davon, wie sie implementiert sind.- Existiert als Bezeichner, der bestimmte Funktionen implementieren kann, oder es kann ein reiner Bezeichner ohne Schnittstellenmethoden sein.
- Eine Klassengruppe muss als einzelne Klasse behandelt werden, und der Anrufer kontaktiert diese Klassengruppe nur über die Schnittstelle.
- Bestimmte Mehrfachfunktionen müssen implementiert werden, und diese Funktionen haben möglicherweise überhaupt keine Verbindung.
- 2. Anwendungsfälle der abstrakten Klasse (abstract.class):
Kurz gesagt, Sie können sie verwenden, wenn Sie sowohl eine einheitliche Schnittstelle als auch Instanzvariablen oder Standardmethoden benötigen. Die häufigsten sind:
definiert eine Reihe von Schnittstellen, möchte aber nicht jede Implementierungsklasse zwingen, alle Schnittstellen zu implementieren. Sie können abstract.class verwenden, um eine Reihe von Methodenkörpern oder sogar leere Methodenkörper zu definieren, und dann kann die Unterklasse die Methoden auswählen, die sie abdecken möchte.- In einigen Fällen können reine Schnittstellen allein die Koordination zwischen Klassen nicht erfüllen. Zur Unterscheidung verschiedener Beziehungen werden auch Variablen benötigt, die Zustände in der Klasse darstellen. Die Vermittlerrolle des Abstrakten kann dies sehr gut erfüllen.
- Standardisiert eine Reihe gegenseitig koordinierter Methoden, von denen einige gemeinsam und zustandsunabhängig sind und gemeinsam genutzt werden können, ohne dass Unterklassen sie separat implementieren müssen, während andere Methoden erfordern, dass jede Unterklasse spezifische Methoden basierend auf ihren eigenen spezifischen Zuständen implementiert . Funktion
- 10. Kann eine abstrakte Klasse keine Methoden und Attribute haben?
Abstrakte Klassen benötigen keine abstrakten Methoden, aber diejenigen mit abstrakten Methoden müssen abstrakte Klassen sein. Daher kann es in Java keine abstrakten Methoden in abstrakten Klassen geben. Beachten Sie, dass selbst abstrakte Klassen ohne abstrakte Methoden und Eigenschaften nicht instanziiert werden können.
11. 接口的意义
- 定义接口的重要性:在Java编程,abstract class 和interface是支持抽象类定义的两种机制。正是由于这两种机制的存在,才使得Java成为面向对象的编程语言。
- 定义接口有利于代码的规范:对于一个大型项目而言,架构师往往会对一些主要的接口来进行定义,或者清理一些没有必要的接口。这样做的目的一方面是为了给开发人员一个清晰的指示,告诉他们哪些业务需要实现;同时也能防止由于开发人员随意命名而导致的命名不清晰和代码混乱,影响开发效率。
- 有利于对代码进行维护:比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类。可是在不久将来,你突然发现现有的类已经不能够满足需要,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦。如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
- 保证代码的安全和严密:一个好的程序一定符合高内聚低耦合的特征,那么实现低耦合,定义接口是一个很好的方法,能够让系统的功能较好地实现,而不涉及任何具体的实现细节。这样就比较安全、严密一些,这一思想一般在软件开发中较为常见。
12. Java泛型中的extends和super理解
在平时看源码的时候我们经常看到泛型,且经常会看到extends和super的使用,看过其他的文章里也有讲到上界通配符和下届通配符,总感觉讲的不够明白。这里备注一下,以免忘记。
- extends也成为上界通配符,就是指定上边界。即泛型中的类必须为当前类的子类或当前类。
- super也称为下届通配符,就是指定下边界。即泛型中的类必须为当前类或者其父类。
这两点不难理解,extends修饰的只能取,不能放,这是为什么呢? 先看一个列子:
public class Food {}
public class Fruit extends Food {}
public class Apple extends Fruit {}
public class Banana extends Fruit{}
public class GenericTest {
public void testExtends(List extends Fruit> list){
//报错,extends为上界通配符,只能取值,不能放.
//因为Fruit的子类不只有Apple还有Banana,这里不能确定具体的泛型到底是Apple还是Banana,所以放入任何一种类型都会报错
//list.add(new Apple());
//可以正常获取
Fruit fruit = list.get(1);
}
public void testSuper(List super Fruit> list){
//super为下界通配符,可以存放元素,但是也只能存放当前类或者子类的实例,以当前的例子来讲,
//无法确定Fruit的父类是否只有Food一个(Object是超级父类)
//因此放入Food的实例编译不通过
list.add(new Apple());
// list.add(new Food());
Object object = list.get(1);
}
}
在testExtends方法中,因为泛型中用的是extends,在向list中存放元素的时候,我们并不能确定List中的元素的具体类型,即可能是Apple也可能是Banana。因此调用add方法时,不论传入new Apple()还是new Banana(),都会出现编译错误。
理解了extends之后,再看super就很容易理解了,即我们不能确定testSuper方法的参数中的泛型是Fruit的哪个父类,因此在调用get方法时只能返回Object类型。结合extends可见,在获取泛型元素时,使用extends获取到的是泛型中的上边界的类型(本例子中为Fruit),范围更小。
总结:在使用泛型时,存取元素时用super,获取元素时,用extends。
13. 父类的静态方法能否被子类重写
不能,父类的静态方法能够被子类继承,但是不能够被子类重写,即使子类中的静态方法与父类中的静态方法完全一样,也是两个完全不同的方法。
class Fruit{
static String color = "五颜六色";
static public void call() {
System.out.println("这是一个水果");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Fruit fruit = new Banana();
System.out.println(fruit.color); //五颜六色
fruit.call(); //这是一个水果
}
}
如代码所示,如果能够被重写,则输出的应该是这是一个香蕉。与此类似的是,静态变量也不能够被重写。如果想要调用父类的静态方法,应该使用类来调用。 那为什么会出现这种情况呢? 我们要从重写的定义来说:
重写指的是根据运行时对象的类型来决定调用哪个方法,而不是根据编译时的类型。
对于静态方法和静态变量来说,虽然在上述代码中使用对象来进行调用,但是底层上还是使用父类来调用的,静态变量和静态方法在编译的时候就将其与类绑定在一起。既然它们在编译的时候就决定了调用的方法、变量,那就和重写没有关系了。
静态属性和静态方法是否可以被继承
可以被继承,如果子类中有相同的静态方法和静态变量,那么父类的方法以及变量就会被覆盖。要想调用就就必须使用父类来调用。
class Fruit{
static String color = "五颜六色";
static String xingzhuang = "奇形怪状";
static public void call() {
System.out.println("这是一个水果");
}
static public void test() {
System.out.println("这是没有被子类覆盖的方法");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Banana banana = new Banana();
banana.test(); //这是没有被子类覆盖的方法
banana.call(); //调用Banana类中的call方法 这是一个香蕉
Fruit.call(); //调用Fruit类中的方法 这是一个水果
System.out.println(banana.xingzhuang + " " + banana.color); //奇形怪状 黄色
}
}
从上述代码可以看出,子类中覆盖了父类的静态方法的话,调用的是子类的方法,这个时候要是还想调用父类的静态方法,应该是用父类直接调用。如果子类没有覆盖,则调用的是父类的方法。静态变量与此相似。
14. Der Unterschied zwischen Threads und Prozessen
- Definition: Ein Prozess ist eine laufende Aktivität eines Programms für eine bestimmte Datensammlung; ein Thread ist ein Ausführungspfad in einem Prozess. (Ein Prozess kann mehrere Threads erstellen)
- Rollenaspekt: In einem System, das den Thread-Mechanismus unterstützt, ist der Prozess die Einheit der Systemressourcenzuweisung und der Thread die Einheit der CPU-Planung.
- Ressourcenfreigabe: Ressourcen können nicht zwischen Prozessen gemeinsam genutzt werden, aber Threads teilen sich den Adressraum und andere Ressourcen des Prozesses, in dem sie sich befinden. Gleichzeitig verfügt der Thread auch über einen eigenen Stapel, Stapelzeiger, Programmzähler und andere Register.
- In Bezug auf die Unabhängigkeit: Der Prozess verfügt über einen eigenen unabhängigen Adressraum, der Thread jedoch nicht. Der Thread muss vom Prozess abhängig sein, um zu existieren.
- In Bezug auf die Ausgaben. Prozesswechsel sind teuer. Die Fäden sind relativ klein. (Wie bereits erwähnt, ist die Einführung von Threads auch auf Kostenüberlegungen zurückzuführen.)
Sie können diesen Artikel lesen: juejin.im/post/684490…
15. Der Unterschied zwischen final, final und finalize
- final wird zum Deklarieren von Eigenschaften, Methoden und Klassen verwendet, was bedeutet, dass Eigenschaften unveränderlich sind, Methoden nicht überschrieben werden können und Klassen nicht vererbt werden können.
- finally ist Teil der Anweisungsstruktur zur Ausnahmebehandlung und gibt an, dass sie immer ausgeführt wird.
- finalize ist eine Methode der Object-Klasse. Diese Methode des recycelten Objekts wird aufgerufen, wenn der Garbage Collector ausgeführt wird. Diese Methode kann überschrieben werden, um während der Garbage Collection andere Ressourcen wie das Schließen von Dateien usw. bereitzustellen 16. Der Unterschied zwischen Serializable und Parcelable
in Android Wenn Intent ein Klassenobjekt übergeben möchte, kann dies auf zwei Arten erreicht werden.
Methode 1: Serialisierbar, die zu übergebende Klasse implementiert die Serializable-Schnittstelle, um das Objekt zu übergeben. Methode 2: Parcelable, die zu übertragende Klasse implementiert die Parcelable-Schnittstelle, um das Objekt zu übertragen.Serialisierbar (wird mit Java geliefert):
Serialisierbar bedeutet Serialisierung, was bedeutet, dass ein Objekt in einen speicherbaren oder übertragbaren Zustand umgewandelt wird. Serialisierte Objekte können über das Netzwerk übertragen oder lokal gespeichert werden. Serializable ist eine getaggte Schnittstelle, was bedeutet, dass Java dieses Objekt effizient serialisieren kann, ohne Methoden zu implementieren.
Parcelable (nur Android):Parcelable von Android wurde ursprünglich entwickelt, weil Serializable zu langsam ist (unter Verwendung von Reflektion) und darauf ausgelegt ist, Daten effizient zwischen verschiedenen Komponenten innerhalb des Programms und zwischen verschiedenen Android-Programmen zu übertragen (AIDL). in Erinnerung. Das Implementierungsprinzip der Parcelable-Methode besteht darin, ein vollständiges Objekt zu zerlegen. Jeder Teil nach der Zerlegung ist ein von Intent unterstützter Datentyp, wodurch die Funktion der Übergabe des Objekts realisiert wird. Effizienz und Auswahl:
Parcelable hat eine bessere Leistung als Serializable, da letzteres während des Reflexionsprozesses häufig GCs durchführt. Daher wird empfohlen, Parcelable beim Übertragen von Daten zwischen Speichern, z. B. beim Übertragen von Daten zwischen Aktivitäten, zu verwenden. Serialisierbar kann Daten zur einfachen Speicherung beibehalten. Wählen Sie daher Serialisierbar, wenn Sie Daten über das Netzwerk speichern oder übertragen müssen. Da Parcelable in verschiedenen Android-Versionen unterschiedlich sein kann, wird die Verwendung von Parcelable für die Datenpersistenz nicht empfohlen. Parcelable kann nicht verwendet werden, wenn Daten auf der Festplatte gespeichert werden sollen, da Parcelable die Persistenz von Daten bei Änderungen in der Außenwelt nicht garantieren kann. Obwohl Serializable weniger effizient ist, wird dennoch empfohlen, zu diesem Zeitpunkt Serializable zu verwenden.
Bei der absichtlichen Übergabe komplexer Datentypen müssen Sie zunächst eine der beiden Schnittstellen implementieren. Die entsprechenden Methoden sind getSerializableExtra() und getParcelableExtra().
17. Können statische Eigenschaften und statische Methoden vererbt werden? Kann es umgeschrieben werden? Und warum?
Statische Eigenschaften und Methoden der übergeordneten Klasse können von Unterklassen geerbt werdenkönnen nicht von Unterklassen überschrieben werden
: Wenn der Verweis der übergeordneten Klasse auf die Unterklasse zeigt, wird das Objekt zum Aufrufen statischer Methoden oder statischer Variablen verwendet die aufrufenden Methoden oder Variablen der übergeordneten Klasse in . Es wird nicht von Unterklassen überschrieben.
Grund:Weil die statische Methode seit dem Start des Programms Speicher zugewiesen hat, was bedeutet, dass sie fest codiert wurde. Alle Objekte, die auf diese Methode verweisen (entweder Objekte der übergeordneten Klasse oder Objekte der Unterklasse), verweisen auf dasselbe Datenelement im Speicher, nämlich die statische Methode.
Wenn eine statische Methode mit demselben Namen in einer Unterklasse definiert ist, wird sie nicht überschrieben. Stattdessen sollte eine andere statische Methode in der Unterklasse im Speicher zugewiesen werden, und es gibt kein Überschreiben.
18. Die Designabsicht statischer innerer Klassen in Java
Innere Klassen
Innere Klassen sind innerhalb einer Klasse definierte Klassen. Warum gibt es innere Klassen?
Wir wissen, dass es sich bei Klassen in Java um Einzelvererbungen handelt und eine Klasse nur eine andere konkrete Klasse oder abstrakte Klasse erben kann (die mehrere Schnittstellen implementieren kann). Der Zweck dieses Entwurfs besteht darin, dass bei der Mehrfachvererbung, wenn in mehreren übergeordneten Klassen doppelte Attribute oder Methoden vorhanden sind, das Aufrufergebnis der Unterklasse mehrdeutig ist, sodass eine Einzelvererbung verwendet wird.
Der Grund für die Verwendung innerer Klassen besteht darin, dass jede innere Klasse unabhängig eine Implementierung (der Schnittstelle) erben kann. Unabhängig davon, ob die äußere Klasse eine Implementierung (der Schnittstelle) geerbt hat, hat dies keine Auswirkungen auf die innere Klasse.
In unserer Programmierung gibt es manchmal einige Probleme, die mithilfe von Schnittstellen schwer zu lösen sind. Zu diesem Zeitpunkt können wir die von internen Klassen bereitgestellte Fähigkeit nutzen, mehrere konkrete oder abstrakte Klassen zu erben, um diese Programmierprobleme zu lösen. Man kann sagen, dass Schnittstellen nur einen Teil des Problems lösen und innere Klassen die Lösung der Mehrfachvererbung vollständiger machen.
Statische innere Klassen
Bevor wir über statische innere Klassen sprechen, wollen wir zunächst die inneren Klassen der Mitglieder (nicht statische innere Klassen) verstehen.
Innere Klasse des Mitglieds
Die innere Klasse des Mitglieds ist auch die häufigste innere Klasse, sodass sie uneingeschränkten Zugriff auf alle Mitgliedseigenschaften und -methoden der äußeren Klasse hat , die äußere Klasse Wenn eine Klasse auf die Mitgliedseigenschaften und -methoden einer inneren Klasse zugreifen möchte, muss sie über eine Instanz der inneren Klasse darauf zugreifen.
Zwei Punkte, die Sie bei inneren Mitgliedsklassen beachten sollten:
In inneren Mitgliedsklassen können keine statischen Variablen und Methoden vorhanden sein.
Innere Mitgliedsklassen sind an die äußere Klasse angehängt, sodass Sie zuerst nur die äußere Klasse erstellen können Nur dann können innere Klassen erstellt werden.
Statische innere Klassen
Es gibt einen größten Unterschied zwischen statischen inneren Klassen und nicht statischen inneren Klassen: Nicht statische innere Klassen speichern nach der Kompilierung implizit eine Referenz, die auf den Punkt verweist, an dem sie erstellt wurde. s äußere Klasse, die statische innere Klasse jedoch nicht.
Das Fehlen dieser Referenz bedeutet:
Seine Erstellung muss nicht von der Peripherieklasse abhängen.
Es können keine nicht statischen Mitgliedsvariablen und Methoden einer äußeren Klasse verwendet werden.
Die anderen beiden internen Klassen: lokale interne Klassen und anonyme interne Klassen
Lokale interne Klassen
Lokale interne Klassen sind in Methoden und Bereichen verschachtelt. Die Verwendung dieser Klasse dient hauptsächlich dem Anwendungs- und Lösungsvergleich für komplexe Probleme Wir möchten eine Klasse erstellen, um unsere Lösung zu unterstützen. Zu diesem Zeitpunkt möchten wir jedoch nicht, dass diese Klasse öffentlich verfügbar ist. Daher wird eine lokale innere Klasse generiert. Die lokale innere Klasse wird wie die innere Mitgliedsklasse kompiliert, ist jedoch die Wenn sich der Gültigkeitsbereich geändert hat, kann er nur innerhalb der Methode und des Attributs verwendet werden und wird außerhalb der Methode und des Attributs ungültig.
Anonyme innere Klassen
Anonyme innere Klassen haben keine Zugriffsmodifikatoren.
Neue anonyme innere Klasse, diese Klasse muss zuerst existieren.
Wenn der formale Parameter der Methode von der anonymen inneren Klasse verwendet werden muss, muss der formale Parameter endgültig sein.
Anonyme innere Klassen haben keinen expliziten Konstruktor und der Compiler generiert automatisch einen Konstruktor, der auf die äußere Klasse verweist.
Verwandte Empfehlungen: Erste Schritte mit Java
Das obige ist der detaillierte Inhalt vonZusammenfassung der neuen Java-Grundlageninterviewfragen für 2020. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!