
Heim >Datenbank >MySQL-Tutorial >47 Bilder, die Sie durch die Weiterentwicklung von MySQL führen
47 Bilder, die Sie durch die Weiterentwicklung von MySQL führen

- coldplay.xixinach vorne
- 2020-10-14 17:27:202609Durchsuche
Die Spalte „MySQL-Tutorial“ führt Sie durch 47 Bilder, um das fortgeschrittene MySQL zu verstehen.
Im MySQL-Einführungskapitel stellen wir hauptsächlich die grundlegenden SQL-Befehle, Datentypen und Funktionen vor. Wenn Sie jedoch ein qualifizierter Entwickler werden möchten, müssen Sie die oben genannten Kenntnisse erwerben Um über einige fortgeschrittenere Fähigkeiten zu verfügen, besprechen wir, welche fortgeschrittenen Fähigkeiten für MySQL erforderlich sind. Wie und wie Daten gespeichert werden, ist also der Schlüssel zur Speicherung. Daher entspricht die Speicher-Engine der Datenspeicher-Engine und steuert die Speicherung der Daten auf Festplattenebene.
Die Architektur von MySQL kann nach dem dreistufigen Modell verstanden werden
Parallelität
Unterstützung von Transaktionen

- MySQL unterstützt standardmäßig mehrere Speicher-Engines, um verschiedenen Datenbankanwendungen gerecht zu werden . Folgendes wird von der MySQL Storage Engine unterstützt: MyISAM, InnoDB, MEMORY, MERGE, EXAMPLE, NDB-Cluster, ARCHIVE, CSV, Blackhole
- FÖDERIERT
- Standardmäßig ist Wenn Sie eine Tabelle erstellen, ohne die Speicher-Engine anzugeben, wird die Standard-Speicher-Engine verwendet. Wenn Sie die Standard-Speicher-Engine ändern möchten, können Sie
default-table-typein der Parameterdatei festlegen, um den aktuellen Speicher anzuzeigen engine
show variables like 'table_type';复制代码

show engines \g复制代码

ENGINE legt die Speicher-Engine der neuen Tabelle fest. create table cxuan002(id int(10),name varchar(20)) engine = MyISAM;复制代码

MyISAM angegeben. show create table anzeigen 
default-table-type,能够查看当前的存储引擎
alter table cxuan003 engine = myisam;复制代码

奇怪,为什么没有了呢?网上求证一下,在 5.5.3 取消了这个参数
可以通过下面两种方法查询当前数据库支持的存储引擎
select character_set_name, default_collate_name, description, maxlen from information_schema.character_sets;复制代码

在创建新表的时候,可以通过增加 ENGINE 关键字设置新建表的存储引擎。
create table product(id int(11),name varchar(20),price float(10,2));复制代码
上图我们指定了 MyISAM 的存储引擎。
如果你不知道表的存储引擎怎么办?你可以通过 show create table 来查看

如果不指定存储引擎的话,从MySQL 5.1 版本之后,MySQL 的默认内置存储引擎已经是 InnoDB了。建一张表看一下

如上图所示,我们没有指定默认的存储引擎,下面查看一下表

可以看到,默认的存储引擎是 InnoDB。
如果你的存储引擎想要更换,可以使用
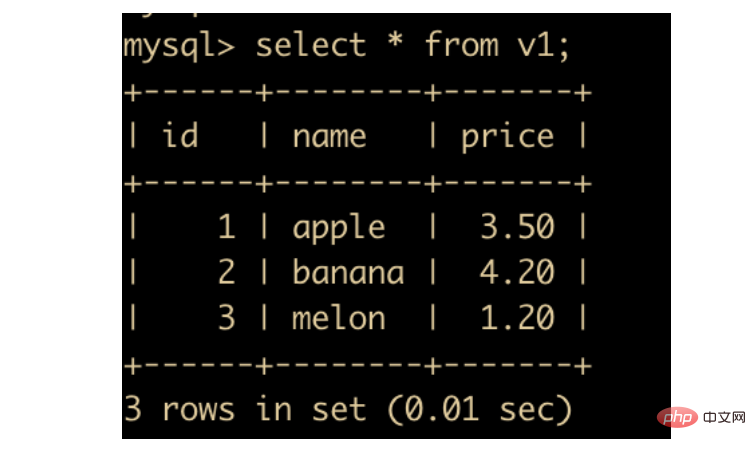
insert into product values(1, "apple","3.5"),(2,"banana","4.2"),(3,"melon","1.2");复制代码
来更换,更换完成后回显示 0 rows affected ,但其实已经操作成功

我们使用 show create tableWie im Bild oben gezeigt, haben wir keine Standardspeicher-Engine angegeben. Sehen Sie sich die Tabelle unten an


InnoDB. Wenn Sie die Speicher-Engine ersetzen möchten, können Sie sie mit
create view v1 as select * from product;复制代码ersetzen. Nach Abschluss des Austauschs wird 🎜0 betroffene Zeilen🎜 angezeigt, der Vorgang war jedoch tatsächlich erfolgreich🎜🎜
🎜🎜 🎜🎜Wir verwenden show create table. Überprüfen Sie die SQL der Tabelle und Sie werden es wissen🎜🎜🎜🎜🎜🎜🎜Eigenschaften der Speicher-Engine🎜🎜Im Folgenden werden einige häufig verwendete Speicher-Engines und ihre grundlegenden Eigenschaften vorgestellt. Diese Speicher-Engines sind **MyISAM, InnoDB, MEMORY AND MERGE**🎜MyISAM
Vor Version 5.1 war MyISAM die Standardspeicher-Engine von MySQL und wurde in weniger Szenarien verwendet. Sein Hauptmerkmal ist, dass
keine
transaction-Operationen unterstützt ACID Die Funktionen sind nicht mehr vorhanden und das Design ist auf Leistung und Effizienz ausgerichtet.事务操作,ACID 的特性也就不存在了,这一设计是为了性能和效率考虑的。不支持
外键操作,如果强行增加外键,MySQL 不会报错,只不过外键不起作用。MyISAM 默认的锁粒度是
表级锁,所以并发性能比较差,加锁比较快,锁冲突比较少,不太容易发生死锁的情况。MyISAM 会在磁盘上存储三个文件,文件名和表名相同,扩展名分别是
.frm(存储表定义)、.MYD(MYData,存储数据)、MYI(MyIndex,存储索引)。这里需要特别注意的是 MyISAM 只缓存索引文件,并不缓存数据文件。-
MyISAM 支持的索引类型有
全局索引(Full-Text)、B-Tree 索引、R-Tree 索引Full-Text 索引:它的出现是为了解决针对文本的模糊查询效率较低的问题。
B-Tree 索引:所有的索引节点都按照平衡树的数据结构来存储,所有的索引数据节点都在叶节点
R-Tree索引:它的存储方式和 B-Tree 索引有一些区别,主要设计用于存储空间和多维数据的字段做索引,目前的 MySQL 版本仅支持 geometry 类型的字段作索引,相对于 BTREE,RTREE 的优势在于范围查找。
数据库所在主机如果宕机,MyISAM 的数据文件容易损坏,而且难以恢复。
增删改查性能方面:SELECT 性能较高,适用于查询较多的情况
InnoDB
自从 MySQL 5.1 之后,默认的存储引擎变成了 InnoDB 存储引擎,相对于 MyISAM,InnoDB 存储引擎有了较大的改变,它的主要特点是
- 支持事务操作,具有事务 ACID 隔离特性,默认的隔离级别是
可重复读(repetable-read)、通过MVCC(并发版本控制)来实现的。能够解决脏读和不可重复读的问题。 - InnoDB 支持外键操作。
- InnoDB 默认的锁粒度
行级锁,并发性能比较好,会发生死锁的情况。 - 和 MyISAM 一样的是,InnoDB 存储引擎也有
.frm文件存储表结构定义,但是不同的是,InnoDB 的表数据与索引数据是存储在一起的,都位于 B+ 数的叶子节点上,而 MyISAM 的表数据和索引数据是分开的。 - InnoDB 有安全的日志文件,这个日志文件用于恢复因数据库崩溃或其他情况导致的数据丢失问题,保证数据的一致性。
- InnoDB 和 MyISAM 支持的索引类型相同,但具体实现因为文件结构的不同有很大差异。
- 增删改查性能方面,果执行大量的增删改操作,推荐使用 InnoDB 存储引擎,它在删除操作时是对行删除,不会重建表。
MEMORY
MEMORY 存储引擎使用存在内存中的内容来创建表。每个 MEMORY 表实际只对应一个磁盘文件,格式是 .frm。 MEMORY 类型的表访问速度很快,因为其数据是存放在内存中。默认使用 HASH 索引。
MERGE
MERGE 存储引擎是一组 MyISAM 表的组合,MERGE 表本身没有数据,对 MERGE 类型的表进行查询、更新、删除的操作,实际上是对内部的 MyISAM 表进行的。MERGE 表在磁盘上保留两个文件,一个是 .frm 文件存储表定义、一个是 .MRG
unterstützt keine Fremdschlüssel-Operationen. Wenn Sie einen Fremdschlüssel erzwingen, meldet MySQL keinen Fehler, aber der Fremdschlüssel funktioniert nicht.
Die standardmäßige Sperrgranularität von MyISAM ist Sperre auf Tabellenebene, daher ist die Parallelitätsleistung relativ schlecht, das Sperren erfolgt schneller, es gibt weniger Sperrkonflikte und es ist weniger wahrscheinlich, dass ein Deadlock auftritt . 🎜🎜🎜MyISAM speichert drei Dateien auf der Festplatte. Die Dateinamen und Tabellennamen sind gleich und die Erweiterungen sind .frm (Speichertabellendefinition), .MYD (MYData, Store-Daten), MYI(MyIndex, Store-Index). Hier ist besonders zu beachten, dass MyISAM nur Indexdateien und keine Datendateien zwischenspeichert. 🎜🎜🎜Zu den von MyISAM unterstützten Indextypen gehören Global Index (Full-Text), B-Tree Index, R-Tree Index Code >🎜🎜Volltextindex: Er scheint das Problem der geringen Effizienz der Fuzzy-Abfrage für Text zu lösen. 🎜🎜B-Baum-Index: Alle Indexknoten werden gemäß der Datenstruktur eines ausgeglichenen Baums gespeichert, und alle Indexdatenknoten befinden sich in Blattknoten. 🎜🎜R-Baum-Index: Die Speichermethode unterscheidet sich etwas vom B-Baum-Index Es ist hauptsächlich für die Indizierung von Feldern konzipiert, die räumliche und mehrdimensionale Daten speichern. Der Vorteil von RTREE ist die Bereichssuche. 🎜🎜🎜Wenn der Host, auf dem sich die Datenbank befindet, ausfällt, werden MyISAM-Datendateien leicht beschädigt und lassen sich nur schwer wiederherstellen. 🎜🎜🎜Hinzufügen, Löschen, Ändern und Abfrageleistung: SELECT bietet eine höhere Leistung und eignet sich für Situationen mit vielen Abfragen🎜<h4 class="heading" data-id="heading-4">InnoDB🎜🎜Seit MySQL 5.1 ist die InnoDB-Speicher-Engine zur Standard-Speicher-Engine geworden. Im Vergleich zu MyISAM hat die InnoDB-Speicher-Engine große Änderungen erfahren: Sie unterstützt Transaktionsvorgänge und verfügt über Transaktions-ACID Isolation. Die Standardisolationsstufe ist <code>repetable-read, implementiert durch MVCC (Concurrent Version Control). Es kann die Probleme von Dirty Read und non-repeatable Read lösen. 🎜InnoDB unterstützt Fremdschlüsseloperationen. 🎜InnoDBs standardmäßige Sperrgranularität ist Sperre auf Zeilenebene, was eine bessere Parallelitätsleistung bietet, aber es kann zu Deadlocks kommen. 🎜Wie MyISAM verfügt auch die InnoDB-Speicher-Engine über eine .frm-Dateispeichertabellenstruktur-Definition, der Unterschied besteht jedoch darin, dass die Tabellendaten und Indexdaten von InnoDB zusammen gespeichert werden, beide in Auf dem Blatt Knoten der B+-Nummer, die Tabellendaten und Indexdaten von MyISAM werden getrennt. 🎜InnoDB verfügt über eine sichere Protokolldatei. Diese Protokolldatei wird verwendet, um Datenverluste zu beheben, die durch einen Datenbankabsturz oder andere Situationen verursacht wurden, und um die Datenkonsistenz sicherzustellen. 🎜InnoDB und MyISAM unterstützen die gleichen Indextypen, aber die spezifische Implementierung ist aufgrund unterschiedlicher Dateistrukturen sehr unterschiedlich. 🎜In Bezug auf die Leistung beim Hinzufügen, Löschen, Ändern und Abfragen wird empfohlen, die InnoDB-Speicher-Engine zu verwenden, wenn eine große Anzahl von Vorgängen zum Hinzufügen, Löschen und Ändern ausgeführt wird. Sie löscht Zeilen während Löschvorgängen und baut die Tabelle nicht neu auf. MEMORY🎜🎜MEMORY-Speicher-Engine verwendet im Speicher gespeicherte Inhalte, um Tabellen zu erstellen. Jede MEMORY-Tabelle entspricht tatsächlich nur einer Festplattendatei und das Format ist .frm. Auf Tabellen vom Typ MEMORY wird sehr schnell zugegriffen, da ihre Daten im Speicher gespeichert sind. Standardmäßig wird HASH-Index verwendet. 🎜MERGE🎜🎜MERGE-Speicher-Engine ist eine Kombination aus einer Reihe von MyISAM-Tabellen. Die MERGE-Tabelle selbst enthält keine Daten. Sie kann MERGE abfragen, aktualisieren und löschen Typtabellen. Die Operation wird tatsächlich für die interne MyISAM-Tabelle ausgeführt. Die MERGE-Tabelle speichert zwei Dateien auf der Festplatte, eine ist die Datei .frm, die die Tabellendefinition speichert, und die andere ist die Datei .MRG, die die Zusammensetzung der Tabelle speichert MERGE-Tabelle. 🎜🎜Wählen Sie die geeignete Speicher-Engine aus.🎜🎜Im eigentlichen Entwicklungsprozess wählen wir häufig die geeignete Speicher-Engine basierend auf den Anwendungseigenschaften aus. 🎜
- MyISAM: Wenn die Anwendung normalerweise abruforientiert ist, nur wenige Einfüge-, Aktualisierungs- und Löschvorgänge aufweist und die Integrität und Parallelität der Dinge nicht sehr hoch ist, wird normalerweise empfohlen, die MyISAM-Speicher-Engine zu wählen.
- InnoDB: Wenn Fremdschlüssel verwendet werden, ein hohes Maß an Parallelität erforderlich ist und die Anforderungen an die Datenkonsistenz hoch sind, wird normalerweise die InnoDB-Engine gewählt. Im Allgemeinen haben große Internetunternehmen höhere Anforderungen an Parallelität und Datenintegrität Verwenden Sie die InnoDB-Speicher-Engine.
- MEMORY: Die MEMORY-Speicher-Engine speichert alle Daten im Speicher und kann einen extrem schnellen Zugriff ermöglichen, wenn ein schneller Standort erforderlich ist. MEMORY wird typischerweise für kleine Tabellen verwendet, die seltener aktualisiert werden, und für den schnellen Zugriff auf Ergebnisse.
- MERGE: MERGE verwendet MyISAM-Tabellen intern. Der Vorteil der MERGE-Tabelle besteht darin, dass sie die Größenbeschränkung einer einzelnen MyISAM-Tabelle durchbrechen kann und durch die Verteilung verschiedener Tabellen auf mehrere Festplatten die Zugriffseffizienz der MERGE-Tabelle erhöht werden kann effektiv verbessert werden.
Wählen Sie den geeigneten Datentyp
.frm, die die Tabellendefinition speichert, und die andere ist die Datei .MRG, die die Zusammensetzung der Tabelle speichert MERGE-Tabelle. 🎜🎜Wählen Sie die geeignete Speicher-Engine aus.🎜🎜Im eigentlichen Entwicklungsprozess wählen wir häufig die geeignete Speicher-Engine basierend auf den Anwendungseigenschaften aus. 🎜- MyISAM: Wenn die Anwendung normalerweise abruforientiert ist, nur wenige Einfüge-, Aktualisierungs- und Löschvorgänge aufweist und die Integrität und Parallelität der Dinge nicht sehr hoch ist, wird normalerweise empfohlen, die MyISAM-Speicher-Engine zu wählen.
- InnoDB: Wenn Fremdschlüssel verwendet werden, ein hohes Maß an Parallelität erforderlich ist und die Anforderungen an die Datenkonsistenz hoch sind, wird normalerweise die InnoDB-Engine gewählt. Im Allgemeinen haben große Internetunternehmen höhere Anforderungen an Parallelität und Datenintegrität Verwenden Sie die InnoDB-Speicher-Engine.
- MEMORY: Die MEMORY-Speicher-Engine speichert alle Daten im Speicher und kann einen extrem schnellen Zugriff ermöglichen, wenn ein schneller Standort erforderlich ist. MEMORY wird typischerweise für kleine Tabellen verwendet, die seltener aktualisiert werden, und für den schnellen Zugriff auf Ergebnisse.
- MERGE: MERGE verwendet MyISAM-Tabellen intern. Der Vorteil der MERGE-Tabelle besteht darin, dass sie die Größenbeschränkung einer einzelnen MyISAM-Tabelle durchbrechen kann und durch die Verteilung verschiedener Tabellen auf mehrere Festplatten die Zugriffseffizienz der MERGE-Tabelle erhöht werden kann effektiv verbessert werden.
Wählen Sie den geeigneten Datentyp
Ein Problem, auf das wir beim Erstellen einer Tabelle häufig stoßen, ist die Auswahl des geeigneten Datentyps. Im Allgemeinen kann die Auswahl des geeigneten Datentyps die Leistung verbessern und unnötige Probleme reduzieren wie man den geeigneten Datentyp auswählt.
Auswahl von CHAR und VARCHAR
char und varchar sind zwei Datentypen, die wir häufig zum Speichern von Zeichenfolgen verwenden. char speichert im Allgemeinen Zeichenfolgen fester Länge, wie zum Beispiel die folgenden: Wert
| '' | ||
|---|---|---|
| 'cx' | 'cx ' | |
| 'cxuan' | 'cxuan' | |
| 'cxuan007' | 'cxuan' | |
| Sie können das unabhängig vom Wert sehen, den Sie schreiben, sobald die Länge der Zeichen angegeben ist Wenn die Länge Ihrer Zeichenfolge nicht ausreicht, um die Länge der Zeichen anzugeben, wird sie mit Leerzeichen aufgefüllt. Wenn sie die Länge der Zeichenfolge überschreitet, werden nur die Zeichen der angegebenen Zeichenlänge gespeichert. |
Wenn der Zeichentyp Varchar verwendet wird, schauen wir uns ein Beispiel an: Byte'cx''cx '
严格模式的话,上面表格最后一行是可以存储的。如果 MySQL 使用了严格模式
| 'cxuan' | 'cxuan' | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 'cxuan007' | ' c xuan' | 6 Bytes | |||||||||||||
|
Sie können sehen, dass bei Verwendung von Varchar die gespeicherten Bytes entsprechend dem tatsächlichen Wert gespeichert werden. Sie fragen sich vielleicht, warum die Länge von Varchar 5 beträgt, aber 3 Bytes oder 6 Bytes gespeichert werden müssen. Dies liegt daran, dass bei Verwendung des Varchar-Datentyps standardmäßig am Ende eine Zeichenfolge hinzugefügt wird, die 1 Wort belegt. Abschnitt (zwei Bytes werden verwendet, wenn die Spaltendeklaration länger als 255 ist). Varchar füllt keine leeren Zeichenfolgen. Verwenden Sie im Allgemeinen char, um Zeichenfolgen fester Länge zu speichern, z. B. ID-Kartennummer, Mobiltelefonnummer, E-Mail usw.; verwenden Sie varchar, um Zeichenfolgen variabler Länge zu speichern. Da die Länge von char fest ist, ist seine Verarbeitungsgeschwindigkeit viel schneller als bei VARCHAR, der Nachteil besteht jedoch darin, dass Speicherplatz verschwendet wird. Mit der kontinuierlichen Weiterentwicklung der MySQL-Versionen verbessert sich jedoch auch die Leistung des Datentyps varchar ständig Daher wird es in vielen Anwendungen verwendet. Der Typ VARCHAR wird häufiger verwendet. In MySQL haben verschiedene Speicher-Engines unterschiedliche Nutzungsprinzipien von CHAR und VARCHAR
TEXTMEDIUMTEXT
BLOB 往下细分有
三种,它们最主要的区别就是存储文本长度不同和存储字节不同,用户应该根据实际情况选择满足需求的最小存储类型,下面主要对 BLOB 和 TEXT 存在一些问题进行介绍 TEXT 和 BLOB 在删除数据后会存在一些性能上的问题,为了提高性能,建议使用 也可以使用合成索引来提高文本字段(BLOB 和 TEXT)的查询性能。合成索引就是根据大文本(BLOB 和 TEXT)字段的内容建立一个散列值,把这个值存在对应列中,这样就能够根据散列值查找到对应的数据行。一般使用散列算法比如 md5() 和 SHA1() ,如果散列算法生成的字符串带有尾部空格,就不要把它们存在 CHAR 和 VARCHAR 中,下面我们就来看一下这种使用方式 首先创建一张表,表中记录 blob 字段和 hash 值  向 cxuan005 中插入数据,其中 hash 值作为 info 的散列值。  然后再插入两条数据  插入一条 info 为 cxuan005 的数据  如果想要查询 info 为 cxuan005 的数据,可以通过查询 hash 列来进行查询  这是合成索引的例子,如果要对 BLOB 进行模糊查询的话,就要使用前缀索引。 其他优化 BLOB 和 TEXT 的方式:
浮点数和定点数的选择浮点数指的就是含有小数的值,浮点数插入到指定列中超过指定精度后,浮点数会四舍五入,MySQL 中的浮点数指的就是  MEDIUMBLOB 🎜LONGBLOB🎜🎜🎜 dass die Textlänge unterschiedlich ist und Bytes speichern Anders gesagt, Benutzer sollten den Mindestspeichertyp auswählen, der ihren tatsächlichen Anforderungen entspricht. Im Folgenden werden hauptsächlich einige Probleme mit BLOB und TEXT vorgestellt, und BLOB wird nach dem Löschen von Daten einige Leistungsprobleme haben. Es wird empfohlen, die Funktion TABELLE OPTIMIEREN zu verwenden, um die Tabelle zu defragmentieren. 🎜🎜Synthetische Indizes können auch verwendet werden, um die Abfrageleistung für Textfelder (BLOB und TEXT) zu verbessern. Der synthetische Index besteht darin, einen Hash-Wert basierend auf dem Inhalt des großen Textfelds (BLOB und TEXT) zu erstellen und diesen Wert in der entsprechenden Spalte zu speichern, sodass die entsprechende Datenzeile basierend auf dem Hash-Wert gefunden werden kann. Im Allgemeinen werden Hashing-Algorithmen wie md5() und SHA1() verwendet. Wenn die vom Hashing-Algorithmus generierten Zeichenfolgen nachgestellte Leerzeichen enthalten, sollten Sie diese nicht in CHAR und VARCHAR speichern. Schauen wir uns zunächst diese Verwendungsmethode an Erstellen Sie eine Tabelle, die Blob-Felder und Hash-Werte aufzeichnet. width="1280" data-height="131"/>🎜🎜🎜🎜Fügen Sie Daten in cxuan005 ein, wo der Hash-Wert als Hash-Wert der Informationen verwendet wird. 🎜🎜🎜🎜🎜🎜Dann fügen Sie zwei weitere Datenelemente ein🎜🎜 🎜🎜🎜🎜Fügen Sie ein Datenelement mit den Informationen cxuan005🎜🎜 🎜🎜🎜🎜Fügen Sie ein Datenelement mit den Informationen cxuan005🎜🎜 🎜🎜🎜🎜Wenn Sie die Daten abfragen möchten, deren Informationen sind cxuan005, Sie können es über die Hash-Spalte abfragen, um Daten abzufragen -width="1280" data-height="191"/>🎜🎜🎜🎜Dies ist ein Beispiel für einen synthetischen Index. Wenn Sie eine Fuzzy-Abfrage für BLOB durchführen möchten, müssen Sie einen Präfixindex verwenden. 🎜🎜Andere Möglichkeiten zur Optimierung von BLOB und TEXT: 🎜🎜🎜Rufen Sie BLOB- und TEXT-Indizes nicht ab, es sei denn, dies ist erforderlich. 🎜🎜Trennen Sie BLOB- oder TEXT-Spalten in separate Tabellen. 🎜🎜 🎜🎜🎜🎜Wenn Sie die Daten abfragen möchten, deren Informationen sind cxuan005, Sie können es über die Hash-Spalte abfragen, um Daten abzufragen -width="1280" data-height="191"/>🎜🎜🎜🎜Dies ist ein Beispiel für einen synthetischen Index. Wenn Sie eine Fuzzy-Abfrage für BLOB durchführen möchten, müssen Sie einen Präfixindex verwenden. 🎜🎜Andere Möglichkeiten zur Optimierung von BLOB und TEXT: 🎜🎜🎜Rufen Sie BLOB- und TEXT-Indizes nicht ab, es sei denn, dies ist erforderlich. 🎜🎜Trennen Sie BLOB- oder TEXT-Spalten in separate Tabellen. 🎜🎜Auswahl von Gleitkommazahlen und Festkommazahlen🎜🎜Gleitkommazahlen beziehen sich auf Werte, die Dezimalzahlen enthalten, nachdem Gleitkommazahlen in die angegebene Zahl eingefügt wurden Spalte und überschreiten die angegebene Genauigkeit. Gleitkommazahlen beziehen sich in MySQL auf
|





| Ja | Einzelbyte-8-Bit-Kodierung | |
|---|---|---|
| Doppelbyte-Kodierung | UTF-8 | |
| 1 - 4-Byte-Kodierung | UTF -16 | |
| 2-Byte- oder 4-Byte-Kodierung | UTF-32 | |
| 4-Byte-Kodierung |
























Das obige ist der detaillierte Inhalt von47 Bilder, die Sie durch die Weiterentwicklung von MySQL führen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was soll ich tun, wenn MySQL meldet, dass das Startkennwort falsch ist?
- Wie lösche ich Benutzerberechtigungen in MySQL unter Linux?
- So rufen Sie versehentlich gelöschte Daten in MySQL ab
- So überprüfen Sie die aktuelle Anzahl der Verbindungen in MySQL
- So löschen Sie ein Feld in der Tabelle in MySQL
- MySQL fragt die Tabellenstruktur unter der Datenbank ab?