
Heim >Datenbank >MySQL-Tutorial >Was ist MySQL-Master-Slave-Synchronisation?
Was ist MySQL-Master-Slave-Synchronisation?

- 青灯夜游Original
- 2020-10-05 14:39:415410Durchsuche
MySQL-Master-Slave-Synchronisation bedeutet Backup. Die Master-Bibliothek (Master) synchronisiert die Schreibvorgänge in ihrer eigenen Slave-Bibliothek (Slave). Da es auch eine Kopie der Daten in der Slave-Datenbank gibt, können die Daten schnell wiederhergestellt werden, ohne dass es zu Datenverlusten kommt oder diese verringert werden.

Was ist MySQL-Master-Slave-Synchronisation?
Wenn sich die Daten in der Master-Datenbank ändern, werden die Änderungen in Echtzeit mit der Slave-Datenbank synchronisiert.
Daten sind ein wesentlicher Bestandteil einer Anwendung. In Bezug auf den Zweck hat die Master-Slave-Synchronisierung eine gewisse Backup-Bedeutung. Die Master-Bibliothek (Master) synchronisiert die Schreibvorgänge in ihrer eigenen Bibliothek gleichzeitig mit ihrer Slave-Bibliothek (Slave). Wenn der gesamte Server nicht mehr verfügbar ist, können die Daten schnell wiederhergestellt werden, ohne dass ein Datenverlust verursacht oder verringert wird, da auch eine Kopie der Daten in der Slave-Datenbank vorhanden ist.
Natürlich ist dies nur die erste Ebene. Wenn die Rolle der Master-Slave-Bibliothek darauf beschränkt ist, besteht meiner Meinung nach keine Notwendigkeit, sie in zwei Datenbanken aufzuteilen. Sie müssen die Datenbank nur regelmäßig senden Inhalte als Snapshot auf einen anderen Server zu übertragen, oder wäre es nicht schön, die geschriebenen Inhalte bei jedem Schreiben in Echtzeit an einen anderen Server zu senden? Das spart nicht nur Ressourcen, sondern dient auch dem Zweck der Notfallwiederherstellung und -sicherung.Natürlich kann die Rolle der Master-Slave-Synchronisation nicht darauf beschränkt werden. Sobald wir die Master-Slave-Struktur konfiguriert haben, lassen wir den Slave-Knoten normalerweise nicht nur als Backup-Datenbank dienen Trennung entsprechend(Sie können MyCat oder eine andere Middleware verwenden und selbst etwas darüber lernen. Ich werde darüber in meinem nächsten Blog über MyCat sprechen. Es kann etwas lang sein, also werde ich noch einen schreiben.)
In der tatsächlichen Umgebung ist die Anzahl der Lesevorgänge in der Datenbank viel größer als die Anzahl der Schreibvorgänge in der Datenbank. Daher können wir den Master nur die Schreibfunktion bereitstellen lassen und dann alle Lesevorgänge in die Slave-Datenbank verschieben . Das ist es, was wir normalerweise sagen: Die Trennung von Lesen und Schreiben kann nicht nur den Druck auf den Master verringern, sondern auch eine Notfallwiederherstellung ermöglichen und zwei Fliegen mit einer Klappe schlagen.Was sind die Vorteile der Master-Slave-Synchronisation?
Erweitern Sie horizontal die Ladekapazität der Datenbank.- Fehlertoleranz, hohe Verfügbarkeit. Failover/Hochverfügbarkeit
- Datensicherung.
- Das Prinzip der MySQL-Master-Slave-Synchronisation
- I/0-Thread:
- Dieser Thread ist mit dem Master-Computer verknüpft. Wenn das Binlog des Master-Computers an den Slave gesendet wird, schreibt der E/A-Thread den Protokollinhalt in das lokale Relay-Protokoll (Relay-Protokoll). .
- Dieser Thread liest den Inhalt im Relay-Protokoll und führt entsprechende Vorgänge in der Slave-Datenbank basierend auf dem Inhalt im Relay-Protokoll aus.
- Wenn viele Schreibanfragen vorliegen, sind die Slave-Daten und die Master-Daten möglicherweise inkonsistent. Dies liegt an einer kurzen Verzögerung im Protokollübertragungsprozess oder an zu vielen Schreibbefehlen. und das System wird durch Geschwindigkeitsunterschiede verursacht.
Das ist ungefähr das Prinzip der MySQL-Master-Slave-Synchronisation. Was dabei wirklich eine Rolle spielt, sind tatsächlich diese beiden Protokolldateien, Binlog und Relay-Log.
MySQL-Master-Slave-Synchronisation manuell erstellen 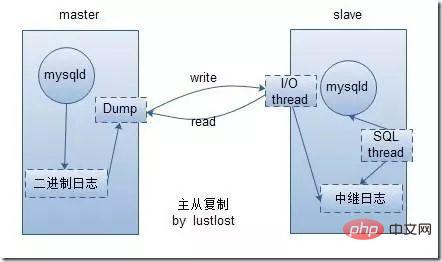
Master:IP :192.168.43.201 Port:3306
Slave1:IP:192.168.43.202 Port:3306
Slave2:IP:192.168.43.203 Port:3306
Beginnen Sie mit dem ErstellenÄndern Sie die KonfigurationsdateiNachdem wir MySQL installiert haben, befindet sich eine my.cnf-Datei im Verzeichnis /etc/. Öffnen Sie die Datei und fügen Sie den folgenden Inhalt hinzu (vergessen Sie nicht, ein Backup zu erstellen vor dem Ändern): x#该配置为Master的配置 server-id=201 #Server id 每台MySQL的必须不同 log-bin=/var/lib/mysql/mysql-bin.log #代表开启binlog日志 expire_logs_days=10 #日志过期时间 max_binlog_size=200M #日志最大容量 binlog_ignore_db=mysql #忽略mysql库,表示不同步此库y
#该配置为Slave的配置,第二台Slave也是这么配置,不过要修改一下server-id server-id=202 expire_logs_days=10 #日志的缓存时间 max_binlog_size=200M #日志的最大大小 replicate_ignore_db=mysql #忽略同步的数据库Slave-Benutzer hinzufügenÖffnen Sie den Client des Master-Knotens, mysql -u root -p PasswortBenutzer erstellen
Benutzer erstellen 'Slave'@'%' identifiziert durch '123456 ';Neu erstellte Benutzer gewähren: Replikations-Slave auf '*.*' zu 'Slave'@'%' gewähren;create user 'Slave'@'%' identified by '123456';
给新创建的用户赋权:grant replication slave on '*.*' to 'Slave'@'%';Master-Knotenstatus anzeigen
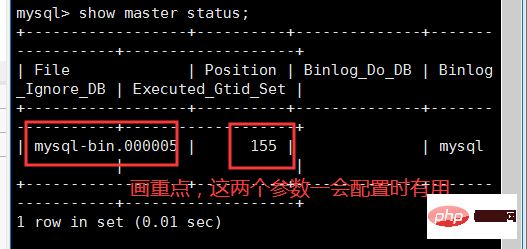
oben Nachdem es keine Probleme mit dem Vorgang gibt, geben wir im Client show master status ein, um das Binlog-Protokoll des Masters anzuzeigen.
配置两个Slave节点
打开两个Slave节点客户端,在我们的另外两个Slave节点中输入如下命令:
change master to master_user='Slave',master_password='123456',master_host='192.168.43.201',master_log_file='mysql-bin.000005',master_log_pos=155,get_master_public_key=1; #注意,这里的master_log_file,就是binlog的文件名,输入上图中的mysql-bin.000005,每个人的都可能不一样。 #注意,这里的master_log_pos是binlog偏移量,输入上图中的155,每个人的都可能不一样。
配置完成后,输入start slave;开启从节点,然后输入show slave status\G;查看从节点状态
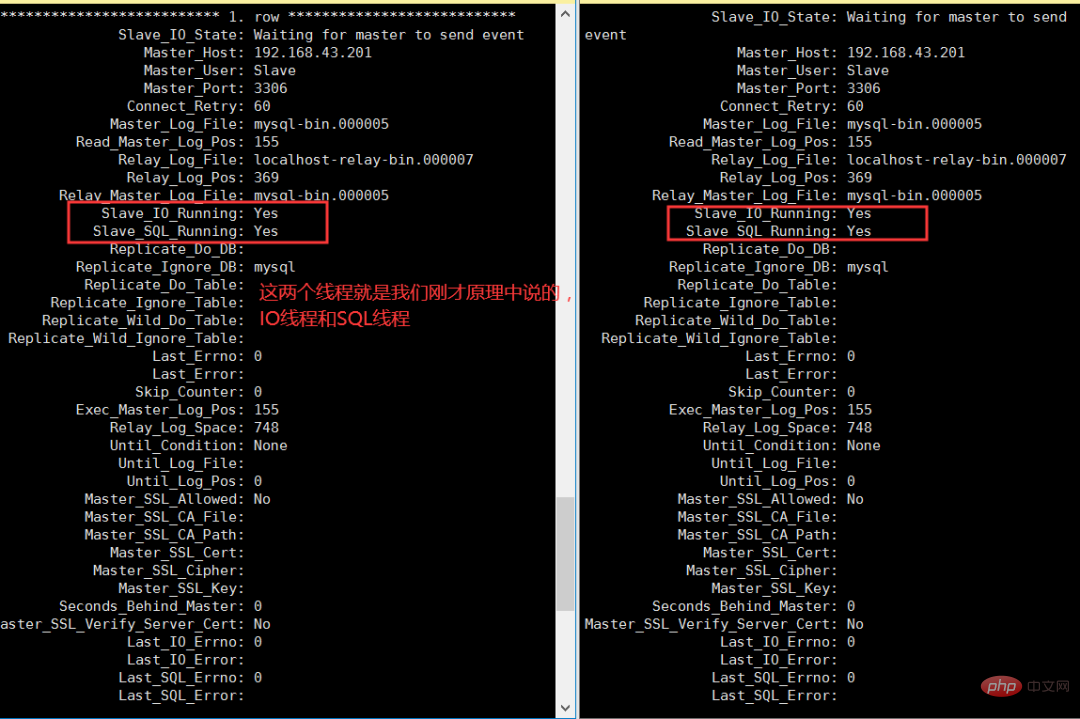
可以看到,在两台Slave的状态中,我们能亲眼看到IO线程和SQL线程的运行状态,这两个线程必须都是yes,才算配置搭建完成。
搭建完成
通过上述步骤,就完成了MySQL主从同步的搭建,相对Redis而言MySQL配置相当简单。下面我们可以进行测试。
先看看三个MySQL的数据库状态:SHOW DATABASES;

可以看到现在数据库都是初始默认状态,没有任何额外的库。
在Master节点中创建一个数据库,库名可以自己设置。
CREATE DATABASE testcluster;
<img alt="" class="has" src="https://img.php.cn/upload/article/000/000/024/fefa55750f9a4ddaec29168c6cc022e9-4.png">
可以看到,在Slave中也出现了Master中创建的数据库,说明我们的配置没有问题,主从搭建成功。这里就不再创建表了,大家可以自己试试,创建表再往表中插入数据,也是没有任何问题的。
注意事项
如果出现IO线程一直在Connecting状态,可以看看是不是三台机器无法相互连接,如果可以相互连接,那么有可能是Slave账号密码写错了,重新关闭Slave然后输入上面的配置命令再打开Slave即可。
如果出现SQL线程为NO状态,那么有可能是从数据库和主数据库的数据不一致造成的,或者事务回滚,如果是后者,先关闭Slave,然后先查看master的binlog和position,然后输入配置命令,再输入set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;,再重新start slave;即可,如通过是前者,那么就排查一下是不是存在哪张表没有被同步,是否存在主库存在而从库不存在的表,自己同步一下再重新配置一遍即可。
结语
在写这篇文章之前自己也被一些计算机领域的“名词”吓到过,相信有不少同学都有一样的体会,碰上某些高大上的名词总是先被吓到,例如像“分布式”、“集群”等等等等,甚至在没接触过nginx之前,连”负载均衡“、”反向代理“这样的词都让人觉得,这么高达上的词,肯定很难吧,但其实自己了解了nginx、ribbon等之后才发现,其实也就那么回事吧,没有想象中的那么难。
所以写这篇文章的初衷是想让大家对集群化或者分布式或者其他的一些技术或者解决方案不要有一种望而却步的感觉(感觉计算机领域的词都有这么一种特点,词汇高大上,但是其实思想是比较好理解的),其实自己手动配置出一个简单的集群并没有那么难。
如果学会docker之后再来配置就更加简单了,但是更希望不要只局限于会配置,配置出来的东西只能说你会配置了,但是在这层配置底下是前人做了相当多的工作,才能使我们通过简单配置就能实现一些功能,应该要深入底层,了解配置下面的工作原理,这个才是最重要的,也是体现一个程序员水平的地方。
推荐教程:mysql视频教程
Das obige ist der detaillierte Inhalt vonWas ist MySQL-Master-Slave-Synchronisation?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie greife ich in PHP auf die MySQL-Datenbank zu?
- Wie stelle ich das MySQL-Codierungsformat in der Befehlszeile ein?
- Wie lade ich das Quellcodepaket von der offiziellen MySQL-Website herunter?
- Wie frage ich alle Felder einer Tabelle in MySQL ab?
- Gehört MySQL zu Oracle?
- Welche Priorität haben MySQL-Abfrageanweisungen?
- Welche Verwaltungssoftware wird für MySQL verwendet?