
Heim >Backend-Entwicklung >Python-Tutorial >Pandas ausführlichstes Tutorial
Pandas ausführlichstes Tutorial

- coldplay.xixinach vorne
- 2020-09-18 16:51:566375Durchsuche

Verwandte Lernempfehlungen: Python-Tutorial
Python ist Open Source, was großartig ist, aber es kann einige inhärente Probleme von Open Source nicht vermeiden: Viele Pakete tun (oder versuchen) das Gleiche. Wenn Sie neu bei Python sind, ist es schwierig zu wissen, welches Paket für eine bestimmte Aufgabe das beste ist. Sie brauchen jemanden mit Erfahrung, der es Ihnen sagt. Es gibt ein Paket für Data Science, das ein absolutes Muss ist: Pandas.
Das Interessanteste an Pandas ist, dass darin viele Taschen versteckt sind. Es handelt sich um ein Kernpaket mit vielen Funktionen anderer Pakete. Das ist großartig, weil Sie einfach Pandas verwenden und die Arbeit erledigen können.
pandas entspricht Excel in Python: Es verwendet Tabellen (d. h. Datenrahmen) und kann verschiedene Transformationen an Daten durchführen, hat aber auch viele andere Funktionen.
Wenn Sie bereits mit der Verwendung von Python vertraut sind, können Sie direkt zum dritten Absatz springen.
Lass uns anfangen:
import pandas as pd复制代码
Fragen Sie nicht, warum „pd“ statt „p“, das ist alles. Benutze es einfach :)
Die grundlegendste Funktion von Pandas
Daten lesen
data = pd.read_csv( my_file.csv ) data = pd.read_csv( my_file.csv , sep= ; , encoding= latin-1 , nrows=1000, skiprows=[2,5])复制代码
sep stellt das Trennzeichen dar. Wenn Sie französische Daten verwenden, ist das CSV-Trennzeichen in Excel „;“, daher müssen Sie es explizit angeben. Die Kodierung ist auf Latin-1 eingestellt, um französische Zeichen zu lesen. nrows=1000 bedeutet, dass die ersten 1000 Datenzeilen gelesen werden. skiprows=[2,5] bedeutet, dass Sie beim Lesen der Datei die Zeilen 2 und 5 entfernen.
Die am häufigsten verwendeten Funktionen: read_csv, read_excel
Einige andere tolle Funktionen: read_clipboard, read_sql
Daten schreiben
data.to_csv( my_new_file.csv , index=None)复制代码
index=Keine bedeutet, dass die Daten so geschrieben werden, wie sie sind. Wenn Sie index=None nicht schreiben, erhalten Sie eine zusätzliche erste Spalte mit den Inhalten 1, 2, 3, ... bis zur letzten Zeile.
Normalerweise verwende ich keine anderen Funktionen wie .to_excel, .to_json, .to_pickle usw., da .to_csv diese Aufgabe sehr gut erfüllen kann und CSV die am häufigsten verwendete Methode zum Speichern von Tabellen ist.
Überprüfen Sie die Daten.

Gives (#rows, #columns)复制代码
Angesichts der Anzahl der Zeilen und Spalten.
data.describe()复制代码. Ebenso entspricht .tail() der letzten Datenzeile.
data.head(3)复制代码Drucken Sie die achte Zeile
data.loc[8]复制代码Drucken Sie die Spalte mit dem Namen „column_1“ in der achten Zeile
data.loc[8, column_1 ]复制代码Die Datenteilmenge der vierten bis sechsten Zeile (links geschlossen, rechts offen)Grundfunktionen von Pandas
Logisch Operationen
data.loc[range(4,6)]复制代码Verwenden Sie logische Operationen, um Daten zu unterteilen. Um & (AND), ~ (NOT) und | (OR) zu verwenden, müssen Sie „und“ vor und nach der logischen Operation hinzufügen.
data[data[ column_1 ]== french ]
data[(data[ column_1 ]== french ) & (data[ year_born ]==1990)]
data[(data[ column_1 ]== french ) & (data[ year_born ]==1990) & ~(data[ city ]== London )]复制代码
Zusätzlich zur Verwendung mehrerer ORs in derselben Spalte können Sie auch die Funktion .isin() verwenden. Grundlegendes Plotten
Das Matplotlib-Paket macht dies möglich. Wie wir in der Einleitung sagten, kann es direkt in Pandas verwendet werden.data[data[ column_1 ].isin([ french , english ])]复制代码
().plot() Beispiel für die Ausgabe
data[ column_numerical ].plot()复制代码
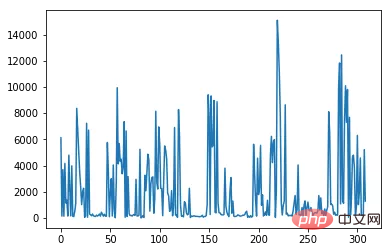
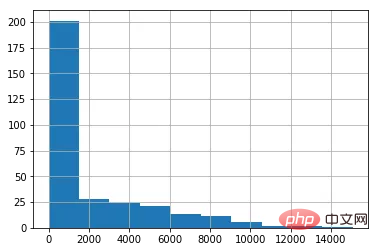
.hist() Beispiel für die Ausgabe
data[ column_numerical ].hist()复制代码
%matplotlib inline复制代码
data.loc[8, column_1 ] = english 将第八行名为 column_1 的列替换为「english」复制代码Ändern Sie die Werte mehrerer Spalten in einer CodezeileOkay, jetzt können Sie etwas tun, das in Excel leicht zugänglich ist. Lassen Sie uns auf einige erstaunliche Dinge eingehen, die Sie in Excel nicht tun können.
Zwischenfunktion
Zählen Sie die Anzahl der Vorkommendata.loc[data[ column_1 ]== french , column_1 ] = French复制代码
Beispiel für die Ausgabe der Funktion „value_counts()“
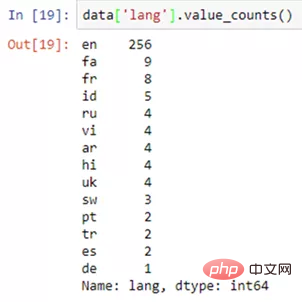 Bearbeiten Sie alle Zeilen, Spalten oder die gesamten Daten
Bearbeiten Sie alle Zeilen, Spalten oder die gesamten Datendata[ column_1 ].value_counts()复制代码
data[ column_1 ].map(len)复制代码Eine tolle Funktion von Pandas ist die Kettenmethode (tomaugspurger.github.io/ method-chai… und .plot ()).
data[ column_1 ].map(len).map(lambda x: x/100).plot()复制代码.apply() wendet eine Funktion auf eine Spalte an. .applymap() wendet eine Funktion auf alle Zellen in der Tabelle (DataFrame) an.
tqdm, der Einzige
在处理大规模数据集时,pandas 会花费一些时间来进行.map()、.apply()、.applymap() 等操作。tqdm 是一个可以用来帮助预测这些操作的执行何时完成的包(是的,我说谎了,我之前说我们只会使用到 pandas)。
from tqdm import tqdm_notebook tqdm_notebook().pandas()复制代码
用 pandas 设置 tqdm
data[ column_1 ].progress_map(lambda x: x.count( e ))复制代码
用 .progress_map() 代替.map()、.apply() 和.applymap() 也是类似的。

在 Jupyter 中使用 tqdm 和 pandas 得到的进度条
相关性和散射矩阵
data.corr() data.corr().applymap(lambda x: int(x*100)/100)复制代码
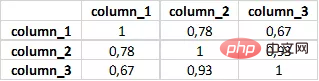
.corr() 会给出相关性矩阵
pd.plotting.scatter_matrix(data, figsize=(12,8))复制代码
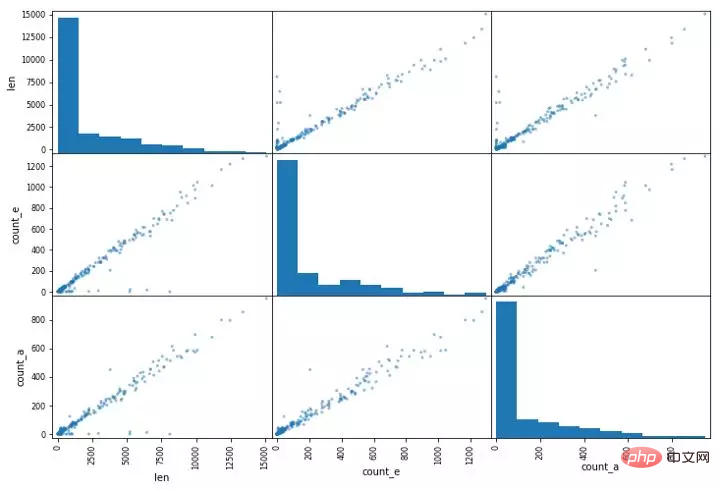
散点矩阵的例子。它在同一幅图中画出了两列的所有组合。
pandas 中的高级操作
The SQL 关联
在 pandas 中实现关联是非常非常简单的
data.merge(other_data, on=[ column_1 , column_2 , column_3 ])复制代码
关联三列只需要一行代码
分组
一开始并不是那么简单,你首先需要掌握语法,然后你会发现你一直在使用这个功能。
data.groupby( column_1 )[ column_2 ].apply(sum).reset_index()复制代码
按一个列分组,选择另一个列来执行一个函数。.reset_index() 会将数据重构成一个表。
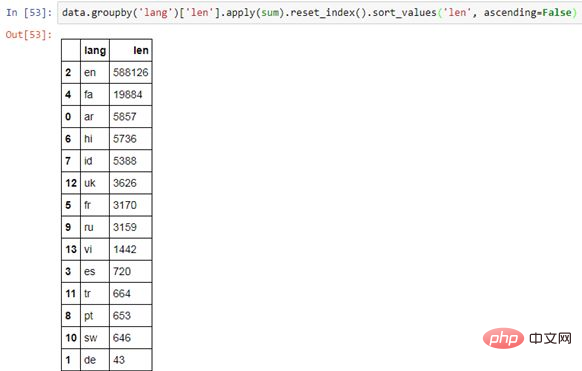
正如前面解释过的,为了优化代码,在一行中将你的函数连接起来。
行迭代
dictionary = {}
for i,row in data.iterrows():
dictionary[row[ column_1 ]] = row[ column_2 ]复制代码.iterrows() 使用两个变量一起循环:行索引和行的数据 (上面的 i 和 row)
总而言之,pandas 是 python 成为出色的编程语言的原因之一
我本可以展示更多有趣的 pandas 功能,但是已经写出来的这些足以让人理解为何数据科学家离不开 pandas。总结一下,pandas 有以下优点:
易用,将所有复杂、抽象的计算都隐藏在背后了;
直观;
快速,即使不是最快的也是非常快的。
它有助于数据科学家快速读取和理解数据,提高其工作效率
Das obige ist der detaillierte Inhalt vonPandas ausführlichstes Tutorial. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Pandas-Tipps zum effizienten Abrufen von Daten durch Indizierung in DataFrame
- Pandas-Tipps: Grundlegende DataFrame-Operationen und Nullwertfüllung
- Pandas-Fähigkeiten: Detaillierte Erläuterung der Apply- und Applymap-Methoden in DataFrame
- Pandas-Fähigkeiten: Methoden zum Sortieren und Zusammenfassen in DataFrame