
Heim >Backend-Entwicklung >Python-Tutorial >Datenverarbeitungsreihe mit Pandas
Datenverarbeitungsreihe mit Pandas

- coldplay.xixinach vorne
- 2020-09-15 16:10:372444Durchsuche

Verwandte Lernempfehlungen: Python-Tutorial
In Python beginnen wir heute mit der Einführung einer neuen, häufig verwendeten Berechnungstool-Bibliothek, der berühmten Pandas.
Der vollständige Name von Pandas ist Python Data Analysis Library, ein wissenschaftliches Rechentool basierend auf Numpy. Sein größtes Merkmal besteht darin, dass es strukturierte Daten genau wie Tabellen in einer Datenbank verarbeiten kann, sodass es viele komplexe und erweiterte Vorgänge unterstützt und als erweiterte Version von Numpy betrachtet werden kann. Es kann problemlos vollständige Daten aus einer CSV- oder Excel-Tabelle erstellen und unterstützt viele Schnittstellen zur Batch-Datenberechnung auf Tabellenebene.
Wie fast alle Python-Pakete können auch Pandas über pip installiert werden. Wenn Sie die Anaconda-Suite installiert haben, wurden Bibliotheken wie Numpy und Pandas automatisch installiert. Wenn Sie sie nicht installiert haben, spielt es keine Rolle, dass wir die Installation mit einer Befehlszeile abschließen können.
pip install pandas复制代码
Wie Numpy geben wir ihm normalerweise einen Alias, wenn wir Pandas verwenden. Der Alias von Pandas ist pd. Die Konvention für die Verwendung von Pandas lautet also:
import pandas as pd复制代码
Wenn Sie diese Zeile ohne Fehler ausführen, bedeutet dies, dass Ihre Pandas installiert wurden. Es gibt zwei weitere Pakete, die im Allgemeinen zusammen mit Pandas verwendet werden. Eines davon ist ebenfalls ein wissenschaftliches Computerpaket namens Scipy und das andere ist ein Toolpaket zur Visualisierung von Daten, genannt Matplotlib. Wir können pip auch verwenden, um diese beiden Pakete zusammen zu installieren. In den folgenden Artikeln wird ihre Verwendung kurz vorgestellt.
pip install scipy matplotlib复制代码
Es gibt zwei am häufigsten verwendete Datenstrukturen in Pandas, eine ist Series und die andere ist DataFrame. Darunter ist
Serie eine eindimensionale Datenstruktur, die einfach als eindimensionales Array oder eindimensionaler Vektor verstanden werden kann. DataFrame ist natürlich eine zweidimensionale Datenstruktur, die als Tabelle oder zweidimensionales Array verstanden werden kann. Werfen wir zunächst einen Blick auf Serien. Es gibt zwei Haupttypen von Daten, die in Serien gespeichert sind. Der eine ist ein Array, das aus einem Datensatz besteht, und der andere ist der Index oder die Bezeichnung dieses Datensatzes. Wir erstellen einfach eine Serie und drucken sie aus, um sie zu verstehen.
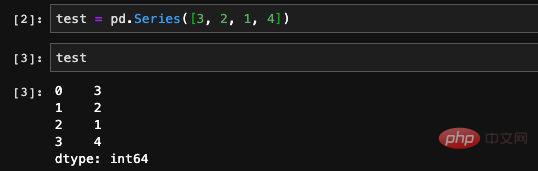 Hier haben wir zufällig eine Serie mit vier Elementen erstellt und diese dann ausgedruckt. Sie können sehen, dass die gedruckten Daten zwei Spalten enthalten. Die zweite Spalte sind die Daten, die wir gerade eingegeben haben. Die erste Spalte ist der Index. Da wir bei der Erstellung keinen Index angegeben haben, erstellt Pandas automatisch einen Zeilennummernindex für uns. Wir können die in der Serie gespeicherten Daten und Indizes über die Werte und Indexattribute im Serientyp anzeigen:
Hier haben wir zufällig eine Serie mit vier Elementen erstellt und diese dann ausgedruckt. Sie können sehen, dass die gedruckten Daten zwei Spalten enthalten. Die zweite Spalte sind die Daten, die wir gerade eingegeben haben. Die erste Spalte ist der Index. Da wir bei der Erstellung keinen Index angegeben haben, erstellt Pandas automatisch einen Zeilennummernindex für uns. Wir können die in der Serie gespeicherten Daten und Indizes über die Werte und Indexattribute im Serientyp anzeigen: 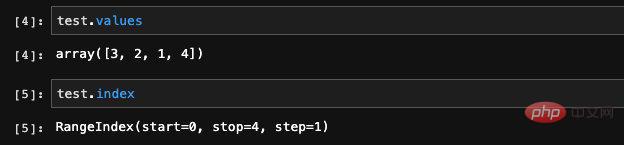
Die Werte-Ausgabe hier ist ein Numpy-Array Dies ist nicht überraschend, da Pandas, wie bereits erwähnt, eine auf Numpy basierende wissenschaftliche Computerbibliothek ist und Numpy die unterste Ebene ist. Anhand der gedruckten Indexinformationen können wir erkennen, dass es sich um einen Index vom Typ „Range“ handelt, sowie dessen Bereich und Schrittgröße.
Index ist ein Standardparameter in der Serienkonstruktionsfunktion. Wenn wir ihn nicht ausfüllen, wird standardmäßig ein Bereichsindex für uns generiert, der tatsächlich die Zeilennummer der Daten ist. Wir können den Index der Daten auch selbst angeben. Wenn wir beispielsweise gerade den Indexparameter zum Code hinzufügen, können wir den Index selbst angeben.

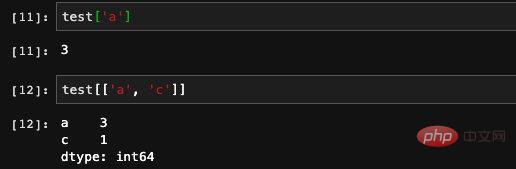
Wenn wir den Index des Zeichentyps angeben, ist das vom Index zurückgegebene Ergebnis nicht mehr RangeIndex, sondern Index. Beachten Sie, dass Pandas intern zwischen numerischen Indizes und Zeichenindizes unterscheidet.
Mit dem Index wird er natürlich zum Auffinden von Elementen verwendet. Wir können den Index direkt als Index des Arrays verwenden, und die Wirkung beider ist die gleiche. Darüber hinaus sind auch Indexarrays akzeptabel, und wir können die Werte mehrerer Indizes direkt abfragen.
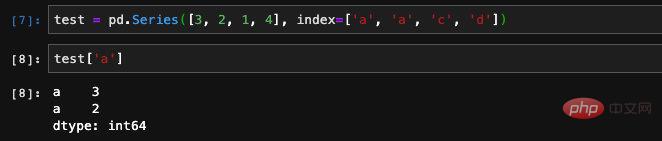
 Darüber hinaus sind beim Erstellen einer Serie auch
Darüber hinaus sind beim Erstellen einer Serie auch . Wenn wir Indexabfragen verwenden, erhalten wir ebenfalls mehrere Ergebnisse.
 Darüber hinaus werden Bool-Indizes wie Numpy weiterhin unterstützt:
Darüber hinaus werden Bool-Indizes wie Numpy weiterhin unterstützt: 
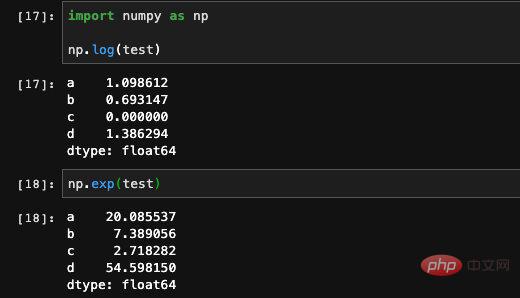
Series unterstützt viele Arten von Berechnungen direkt. Verwenden Sie
: Sie können auch die Operationsfunktion in Numpy verwenden, um einige komplexe mathematische Operationen auszuführen, aber das Ergebnis dieser Berechnung ist ein Numpy-Array. Da es einen Index in der Serie gibt, können wir auch die dict-Methode verwenden, um zu bestimmen, ob der Index in der Serie ist: den Index beim Erstellen angeben Wir können seine Reihenfolge kontrollieren. Natürlich gibt es in Series auch eine isnull-Funktion, die wir auch aufrufen können. Serien in Pandas sind im Wesentlichen eine Kapselungsschicht auf dem eindimensionalen Numpy-Array, wobei einige verwandte Funktionen wie die Indizierung hinzugefügt wurden. Wir können uns also vorstellen, dass DataFrame tatsächlich eine Kapselung eines Series-Arrays ist, dem weitere datenverarbeitungsbezogene Funktionen hinzugefügt wurden. Sobald wir die Kernstruktur verstanden haben, ist es viel nützlicher, die gesamte Funktion von Pandas zu verstehen, als sich diese APIs einzeln zu merken. Pandas ist ein großartiges Tool für die Python-Datenverarbeitung Als qualifizierter Algorithmus-Ingenieur ist es für uns fast notwendig, es zu wissen. Es ist auch die Grundlage für die Verwendung von Python für maschinelles Lernen und Deep Learning. Laut Umfragedaten werden 70 % der täglichen Arbeit von Algorithmeningenieuren in die Datenverarbeitung investiert, und weniger als 30 % werden tatsächlich für die Implementierung und das Training von Modellen verwendet. Daher können wir die Bedeutung der Datenverarbeitung erkennen. Wenn Sie sich in der Branche weiterentwickeln möchten, reicht es nicht aus, das Modell zu erlernen. Dieser Artikel verwendet mdnice für den Schriftsatz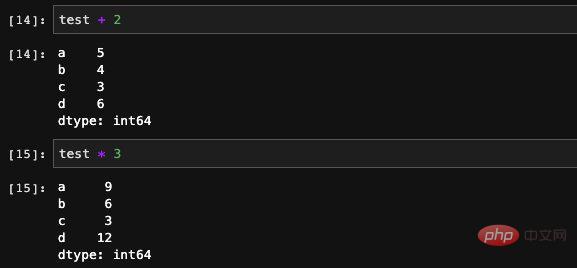
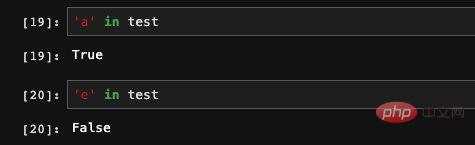
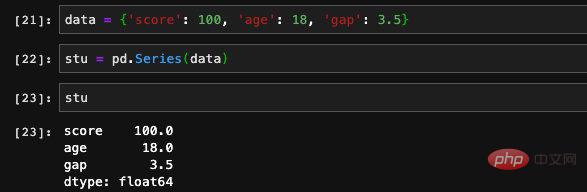
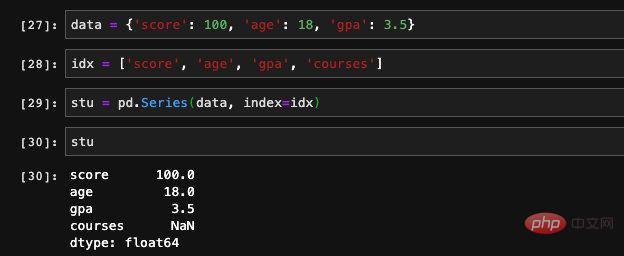 Bei der Angabe des Index übergeben wir einen zusätzlichen Schlüssel, der nicht im Diktat vorkommt. Da der entsprechende Wert im Diktat nicht gefunden werden kann, zeichnet Series ihn als NAN (keine Zahl) auf. Es kann als „ungültiger Wert“ oder „Nullwert“ verstanden werden. Wenn wir Features oder Trainingsdaten verarbeiten, stoßen wir häufig auf Situationen, in denen ein bestimmtes Feature der Daten mit einigen Einträgen leer ist. Wir können die Funktionen isnull und notnull verwenden Überprüfen Sie die Verfügbarkeit von Stellenangeboten.
Bei der Angabe des Index übergeben wir einen zusätzlichen Schlüssel, der nicht im Diktat vorkommt. Da der entsprechende Wert im Diktat nicht gefunden werden kann, zeichnet Series ihn als NAN (keine Zahl) auf. Es kann als „ungültiger Wert“ oder „Nullwert“ verstanden werden. Wenn wir Features oder Trainingsdaten verarbeiten, stoßen wir häufig auf Situationen, in denen ein bestimmtes Feature der Daten mit einigen Einträgen leer ist. Wir können die Funktionen isnull und notnull verwenden Überprüfen Sie die Verfügbarkeit von Stellenangeboten. 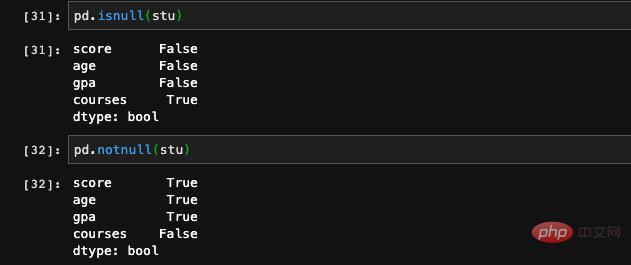
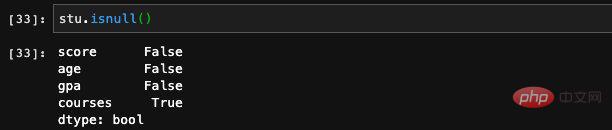 , wir können ihm direkt einen neuen Wert zuweisen:
, wir können ihm direkt einen neuen Wert zuweisen: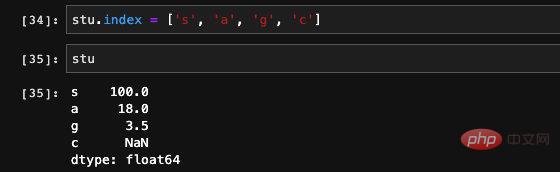
Zusammenfassung
Das obige ist der detaillierte Inhalt vonDatenverarbeitungsreihe mit Pandas. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!