
Heim >häufiges Problem >Was ist nötig, um ein in einer Hochsprache geschriebenes Quellprogramm in ein ausführbares Programm umzuwandeln?
Was ist nötig, um ein in einer Hochsprache geschriebenes Quellprogramm in ein ausführbares Programm umzuwandeln?

- 青灯夜游Original
- 2020-08-31 15:44:1652804Durchsuche
Die Konvertierung eines in einer Hochsprache geschriebenen Quellprogramms in ein ausführbares Programm erfordert „Kompilierung und Verknüpfung“. In Hochsprachen geschriebene Quellprogramme können nicht direkt auf der Maschine ausgeführt werden und müssen kompiliert und verknüpft werden.

Damit ein Programm ausgeführt werden kann, muss es vier Schritte durchlaufen: Vorverarbeitung, Kompilierung, Assemblierung und Verknüpfung. Als nächstes erklären wir diese Prozesse anhand einiger einfacher Beispiele im Detail.
Zu den oben verwendeten Optionen bedarf es einiger Erläuterungen.
Wenn Sie den Befehl gcc ohne Optionen verwenden, wird der gesamte Prozess der Vorverarbeitung, Kompilierung, Assemblierung und Verknüpfung standardmäßig ausgeführt. Wenn das Programm korrekt ist, erhalten Sie eine ausführbare Datei
-E-Option: Fordert den Compiler auf, nach der Vorverarbeitung anzuhalten, und die nachfolgende Kompilierung, Assemblierung und Verknüpfung wird nicht ausgeführt. -S-Option: Fordert den Compiler auf, nach der Kompilierung anzuhalten und keine Assemblierung und Verknüpfung durchzuführen. -c-Option: fordert den Compiler auf, nach der Ausführung der Assembly anzuhalten. Diese drei Optionen entsprechen also der Begrenzung der Stoppzeit des Compiler-Ausführungsvorgangs, anstatt einen bestimmten Schritt separat zur Ausführung herauszunehmen.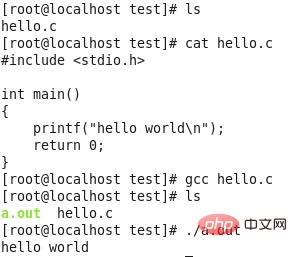
1. Vorverarbeitung:
Verwenden Sie die Option -E, was bedeutet, dass nur eine Vorkompilierung durchgeführt wird und entsprechend eine .i-Datei generiert wird. Vorgänge, die während des Vorverarbeitungsprozesses ausgeführt werden:- Alle „#define“ löschen und alle Makrodefinitionen erweitern
- Alle bedingten Kompilierungsanweisungen verarbeiten, z. B. „#if“, „#ifdef“, „#elif““, „ #else“, „#endif“
- Verarbeiten Sie die Vorkompilierungsanweisung „#include“ und fügen Sie die enthaltene Header-Datei am Speicherort der Kompilierungsanweisung ein. (Dieser Vorgang ist rekursiv, da die eingebundene Datei auch andere Dateien enthalten kann)
- Entfernen Sie alle Kommentare „//“ und „/* */“.
- Fügen Sie Zeilennummern und Dateinamenbezeichner hinzu, damit der Compiler Zeilennummern zum späteren Debuggen während der Kompilierung generieren und Zeilennummern anzeigen kann, wenn während der Kompilierung Kompilierungsfehler oder Warnungen auftreten.
- Behalten Sie alle #pragma-Pragmas bei, da der Compiler sie benötigt.

2. Kompilieren:
Verwenden Sie die Option -S, um anzugeben, dass der Kompilierungsvorgang nach der Ausführung beendet wird. Entsprechend wird eine .s-Datei generiert. Der Kompilierungsprozess besteht darin, eine Reihe von lexikalischen Analysen, Syntaxanalysen und semantischen Analysen durchzuführen Analyse und Optimierung der vorverarbeiteten Datei. Generieren Sie die entsprechende Assembler-Codedatei.- Lexikalische Analyse:
- Grammatikanalyse: Der Grammatikanalysator analysiert die durch die lexikalische Analyse generierte Token-Sequenz gemäß den vom Benutzer angegebenen Grammatikregeln und bildet daraus dann einen Grammatikbaum. Für verschiedene Sprachen unterscheiden sich lediglich ihre grammatikalischen Regeln. Es gibt auch ein fertiges Tool zur Syntaxanalyse namens yacc.
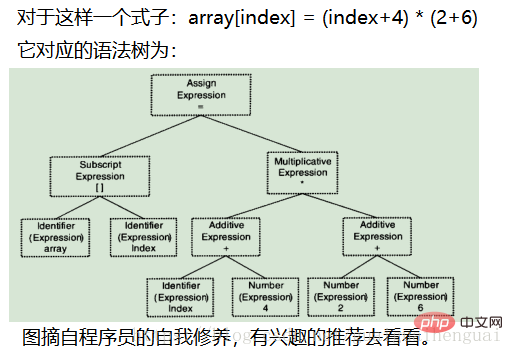
- Semantische Analyse:
Die syntaktische Analyse schließt die Analyse der grammatikalischen Ebene des Ausdrucks ab, versteht jedoch nicht, ob die Aussage wirklich sinnvoll ist. Einige Anweisungen sind grammatikalisch zulässig, haben jedoch keine praktische Bedeutung. Wenn beispielsweise zwei Zeiger multipliziert werden, ist eine semantische Analyse erforderlich. Die einzige Semantik, die der Compiler analysieren kann, ist jedoch.
Statische Semantik: Semantik, die zur Kompilierzeit bestimmt werden kann. Beinhaltet normalerweise Deklaration, Typabgleich und Typkonvertierung. Wenn beispielsweise ein Gleitkommaausdruck einem Ganzzahlausdruck zugewiesen wird, erfolgt implizit eine Konvertierung vom Gleitkommaausdruck in einen Ganzzahlausdruck, und die semantische Analyse muss diese Konvertierung abschließen. Ein weiteres Beispiel ist die Konvertierung eines Gleitkommaausdrucks in einen Ganzzahlausdruck Das Zuweisen eines Ausdrucks zu einem Zeiger ist definitiv nicht möglich. Bei der semantischen Analyse wird festgestellt, dass die beiden Typen nicht übereinstimmen, und der Compiler meldet einen Fehler.
Dynamische Semantik: Semantik, die erst zur Laufzeit ermittelt werden kann. Wenn Sie beispielsweise zwei ganze Zahlen dividieren, gibt es kein Problem mit der Syntax und die Typen stimmen überein. Wenn der Divisor jedoch 0 ist, ist dieses Problem nicht bekannt im Voraus und kann nur während des Betriebs durchgeführt werden. Erst wenn es soweit ist, können wir herausfinden, dass mit ihm etwas nicht stimmt.
- Zwischencodegenerierung
Für einige Werte, die während der Kompilierung ermittelt werden können, werden sie beispielsweise 2+6 während der Kompilierung optimiert Sein Wert ist 8, es ist jedoch schwieriger, die Syntax direkt zu optimieren. In diesem Fall konvertiert der Optimierer zunächst den Syntaxbaum in Zwischencode. Zwischencode ist im Allgemeinen unabhängig von der Zielmaschine und der Betriebsumgebung. (Beinhaltet nicht Datengröße, Variablenadresse, Registernamen usw.). Zwischencodes haben in verschiedenen Compilern unterschiedliche Formen. Die gebräuchlichsten sind Drei-Adressen-Code und P-Code.
Der Zwischencode ermöglicht die Aufteilung des Compilers in Front-End und Back-End. Das Compiler-Front-End ist für die Generierung von maschinenunabhängigem Zwischencode verantwortlich, und das Compiler-Back-End konvertiert den Zwischencode in Maschinencode.
- Zielcodegenerierung und -optimierung
Der Codegenerator wandelt den Zwischencode in Maschinencode um. Dieser Vorgang hängt von der Zielmaschine ab, da verschiedene Maschinen unterschiedliche Wortlängen, Register, Datentypen usw. haben.
Abschließend optimiert der Zielcode-Optimierer den Zielcode, indem er beispielsweise geeignete Adressierungsmethoden auswählt, eindeutige Methoden verwendet, um Multiplikation und Division zu ersetzen, und redundante Anweisungen löscht.
3. Assembler
Der Assembler-Prozess wird durch den Aufruf des Assemblers as abgeschlossen, der dazu dient, den Assembler-Code in Anweisungen umzuwandeln, die die Maschine ausführen kann.
Verwenden Sie den Befehl als hello.s -o hello.o oder verwenden Sie gcc -c hello.s -o hello.o, um ihn bis zum Ende des Montagevorgangs auszuführen. Die entsprechende generierte Datei ist eine .o-Datei.
4. Links
Der Hauptinhalt von Links besteht darin, die Teile, die zwischen Modulen aufeinander verweisen, korrekt zu verbinden. Seine Aufgabe besteht darin, die Verweise einiger Anweisungen auf andere Symboladressen zu korrigieren. Der Verknüpfungsprozess umfasst hauptsächlich die Adress- und Raumzuweisung sowie die Symbolauflösung und -umleitung
Symbolauflösung: Manchmal auch Symbolbindung, Namensbindung, Namensauflösung oder Adressbindung genannt, bezieht sich dies tatsächlich auf die Verwendung von Symbolen zur Identifizierung einer Adresse. A Zum Beispiel int a = 6; ein solcher Code. Verwenden Sie A, um einen Raum mit einer Größe von 4 Bytes im Raum zu identifizieren. Der im Raum gespeicherte Inhalt beträgt 4 Umschreiben.
Die grundlegendste Verknüpfung wird als statische Verknüpfung bezeichnet. Dabei wird die Quellcodedatei jedes Moduls in eine Zieldatei (Linux: .o Windows: .obj) kompiliert und anschließend die Zieldatei und die Bibliothek miteinander verknüpft, um die endgültige Datei zu bilden ausführbare Datei. Eine Bibliothek ist eigentlich ein Paket aus einer Reihe von Zieldateien. Einige der am häufigsten verwendeten Codes werden in Zieldateien umgewandelt und dann gepackt und gespeichert. Die gebräuchlichste Bibliothek ist die Laufzeitbibliothek, eine Sammlung grundlegender Funktionen, die die Programmausführung unterstützen.
Weitere Informationen zu diesem Thema finden Sie auf:
Chinesische PHP-Website!
Das obige ist der detaillierte Inhalt vonWas ist nötig, um ein in einer Hochsprache geschriebenes Quellprogramm in ein ausführbares Programm umzuwandeln?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was kann eine Hochsprache in ein Zielprogramm umwandeln?
- Ist PHP eine Hochsprache?
- Oft werden Programme aufgerufen, die von Benutzern in der Hochsprache eines Computers geschrieben wurden
- Wofür ist Python eine Hochsprache?
- Kann ich Notepad verwenden, um Programmdateien in Hochsprachen zu bearbeiten?
- Der Unterschied zwischen Maschinensprache, Assemblersprache und Hochsprache
- Was sind die Hochsprachen?
- Wie heißt ein Programm, das in Assemblersprache oder Hochsprache geschrieben ist?