
Heim >Backend-Entwicklung >Python-Tutorial >Detaillierte Erläuterung der Methode zum Crawlen von 51cto-Daten in Python und zum Speichern dieser in MySQL
Detaillierte Erläuterung der Methode zum Crawlen von 51cto-Daten in Python und zum Speichern dieser in MySQL

- coldplay.xixinach vorne
- 2020-08-25 16:29:172384Durchsuche
?? Installieren Sie die Umgebung und Module
 Bitte beachten Sie https://www.jb51.net/article/194104.htm
Bitte beachten Sie https://www.jb51.net/article/194104.htm
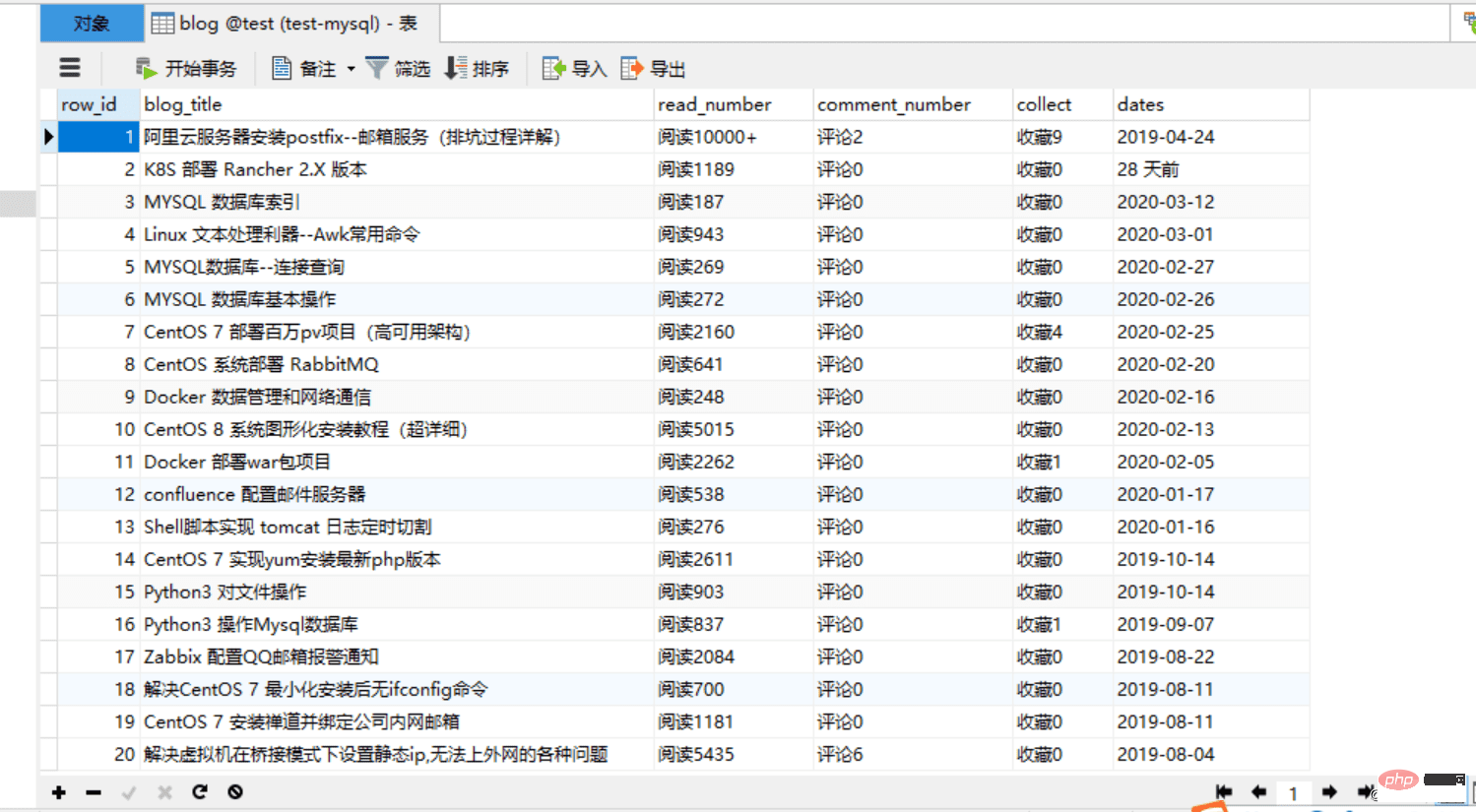
4 und sehen Sie sich den Effekt an:
Verbesserte Version:
1. Einige Felder in der Datenbank können nur Zahlen speichern
2 Standardmäßig besteht der gecrawlte Inhalt aus Zeichenfolgen, in denen einige gespeichert sind Felder der Datenbank. Es ist am besten, sie in einen Ganzzahltyp zu ändern.1 Der Code lautet wie folgt:  rrree
rrree
 Um es Anfängern zu erleichtern Mit diesem Programm können Sie dieses Projekt in eine Datei im Exe-Format packen, sodass andere den Code auf einem Computer ausführen können, was sehr praktisch ist!
Um es Anfängern zu erleichtern Mit diesem Programm können Sie dieses Projekt in eine Datei im Exe-Format packen, sodass andere den Code auf einem Computer ausführen können, was sehr praktisch ist!
1. Verbessern Sie den Code:
rrree2. Installieren Sie das Paketierungsmodul pyinstaller
5. Führen Sie das Exe-Paket aus und überprüfen Sie die Wirkung. Überprüfen Sie die Datenbank. Verwandte Lernempfehlungen:
MySQL-Tutorial
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Methode zum Crawlen von 51cto-Daten in Python und zum Speichern dieser in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So legen Sie die Proxy-IP für den Python-Crawler fest
- Das Python-TQMD-Modul implementiert die Methode zur Anzeige des Fortschrittsbalkens
- Python + Selenium implementiert eine einfache automatische Check-in-Funktion für Epidemieinformationen
- So verarbeiten Sie Ordner im Matroschka-Stil stapelweise über Python