
Heim >häufiges Problem >Was ist der Hauptengpass des Clusters?
Was ist der Hauptengpass des Clusters?

- 青灯夜游Original
- 2020-08-20 16:01:5815350Durchsuche
Der Hauptengpass des Clusters ist: Festplatte. Wenn wir vor einer Schwarmoperation stehen, wollen wir sie sofort lesen. Angesichts von Big Data erfordert das Lesen von Daten jedoch Festplatten-IO. Hier kann IO als Wasserleitung verstanden werden. Je größer und stärker die Pipeline ist, desto schneller können wir T-Level-Daten lesen. Daher wirkt sich die Qualität von IO direkt auf die Datenverarbeitung des Clusters aus.

Es gibt viele Meinungen zum Engpass des Clusters, wobei Netzwerk- und Festplatten-Io umstrittener sind. Hier muss erklärt werden, dass das Netzwerk eine knappe Ressource und kein Engpass ist.
Für Festplatten-E/A: (Festplatten-E/A: Festplattenausgabe)Wenn wir mit Cluster-Vorgängen konfrontiert werden, wollen wir sofortige Lesbarkeit. Angesichts von Big Data erfordert das Lesen von Daten jedoch IO. Hier kann IO als Wasserleitung verstanden werden. Je größer und stärker die Pipeline ist, desto schneller können wir T-Level-Daten lesen. Daher wirkt sich die Qualität von IO direkt auf die Datenverarbeitung des Clusters aus.
Hier sind ein paar Beispiele als Referenz.
Fall 1Seit der Verwendung von Alibaba Cloud sind drei Fehler aufgetreten (eins, zwei und drei). Diese drei Fehler hängen alle mit hoher Festplatten-E/A zusammen.
Der erste Fehler trat in der Cloud auf, in der der Indexierungsdienst zzk.cnblogs.com ausgeführt wurde Auf dem Server die Avg.Disk-Lesewarteschlange Die Länge beträgt mehr als 200.
Der zweite Fehler trat auf dem Cloud-Server auf, auf dem die statischen Dateien von images.cnblogs.com ausgeführt wurden Die Warteschlangenlänge beträgt etwa 2 (spätere Analyse, für Anwendungen wie Bildseiten, die Dateien direkt lesen und antworten, Disk Read Queue). Das Erreichen dieses Werts wirkt sich erheblich auf die Antwortgeschwindigkeit aus.
Der dritte Fehler trat auf dem Cloud-Server auf, auf dem der Datenbankdienst ausgeführt wurde Die Länge erreicht 4 bis 5, was dazu führt, dass bei vielen Datenbankschreibvorgängen eine Zeitüberschreitung auftritt.
(Hier erwähnen wir sowohl „Festplatte“ als auch „Festplatte“. Wir definieren es so: Die im Cloud-Server sichtbare Festplatte wird als Festplatte [virtuelle Festplatte] bezeichnet, und die physische Festplatte im Cluster wird als Festplatte bezeichnet Eine Festplatte)
Diese drei hohen Festplatten-IOs wurden nicht durch die Anwendungen in unserem Cloud-Server verursacht. Der direkteste Beweis ist, dass das Problem nach der Migration des Cloud-Dienstes auf einen anderen Cluster sofort gelöst wurde. Mit anderen Worten, der Festplatten-IO des Cloud-Servers ist hoch, weil Die Festplatten-IO des Clusters, in dem sie sich befindet, ist hoch.
Die Festplatten-IO des Clusters ist die Summe der Festplatten-IO aller Cloud-Server im Cluster. Die hohe Festplatten-IO des Clusters ist darauf zurückzuführen, dass die Festplatten-IO einiger Cloud-Server im Cluster zu hoch ist. Und wir seitdem Die von den Anwendungen auf unserem Cloud-Server generierten Festplatten-IOs liegen im normalen Bereich. Das Problem besteht darin, dass die Cloud-Server anderer Benutzer zu viele Festplatten-IOs generieren, was dazu führt, dass die gesamten Festplatten-IOs des Clusters hoch sind und sich somit auf uns auswirken.
Warum wirken sich Festplatten-IO-Probleme, die durch andere Cloud-Server verursacht werden, auf uns aus? Die Ursache des Problems liegt darin, dass die Festplatten-E/A des Clusters von allen Cloud-Servern im Cluster gemeinsam genutzt wird und diese gemeinsame Nutzung nicht wirksam eingeschränkt oder eingeschränkt wird Aufgrund der effektiven Isolation konkurrieren alle um diese Ressource. Wenn zu viele Personen gleichzeitig um diese Ressource konkurrieren, kommt es zu langen Warteschlangen.
Und für jeden Cloud-Server weiß ich nicht, wie viele Cloud-Server um ihn konkurrieren. Aus Sicht der Cloud-Server-Benutzer. An diesem Wettbewerb führt kein Weg vorbei; genau wie bei der Weltausstellung gilt: Egal wie früh man aufsteht, um sich in die Warteschlange zu stellen, man muss trotzdem in einer extrem langen Warteschlange warten.
Wenn die von jedem Cloud-Server verwendeten Festplatten-IO-Ressourcen eingeschränkt oder isoliert sind, werden andere Cloud-Server zusätzliche Ressourcen generieren Übermäßige Festplatten-IOs wirken sich nicht auf unsere Cloud-Server aus. Wenn Sie alleine ein Haus mieten, hat dies keine Auswirkungen, selbst wenn 100 Personen in einem anderen Haus wohnen.
Sie können
CPU, Arbeitsspeicher, Bandbreite und Festplattenspeicher kaufen, aber Sie können keine Festplatten-IO kaufen, die Ihnen voll und ganz dient Dies ist ein wichtiger Punkt, der bei der Entwicklung des aktuellen Alibaba nicht berücksichtigt wurde Cloud-Virtualisierungsplattform. Nach der Kommunikation mit den technischen Mitarbeitern von Alibaba Cloud erfuhr ich, dass sie sich dieses Problems bewusst sind und hoffen, dass dieses Problem so schnell wie möglich gelöst werden kann.
---------------------------------------------------------------- -------------------------------------------------- ------------------------------------
Fall 2
Zunächst möchte ich mich bei allen entschuldigen. Dieser Cloud-Server-Fehler wurde gegen 17:30 Uhr entdeckt und normalisierte sich wieder. Er hat allen Ärger bereitet . Bitte verzeihen Sie mir!
Die Ursache des Fehlers war, dass die Clusterlast des Cloud-Servers zu hoch war und die Schreibleistung auf die Festplatte stark abfiel, was dazu führte, dass bei vielen Datenbank-Schreibvorgängen eine Zeitüberschreitung auftrat. Die Lösung, die sich später wieder normalisierte, bestand darin, den Cloud-Server auf einen anderen Cluster zu migrieren.
Das Folgende ist der Hauptprozess des Fehlers:
Heute Morgen gegen 9:15 Uhr meldete ein Gärtner per E-Mail, dass beim Zugriff auf den Garten ein 502 Bad Gateway-Fehler aufgetreten sei.
Dies ist ein Fehler, der von Alibaba zurückgegeben wurde Cloud Load Balancer ist ein von Alibaba entwickelter Open-Source-Webserver. Wir spekulieren, dass der von Alibaba Cloud bereitgestellte Lastausgleichsdienst möglicherweise über den Tegine-Reverse-Proxy implementiert wird.
Diese Fehlerseite weist darauf hin, dass der Load Balancer festgestellt hat, dass der Cloud-Server im Load Balancing eine ungültige Antwort zurückgegeben hat, z. B. einen Fehler der 500er-Serie.
Wir haben diese Situation durch einen Arbeitsauftrag an Alibaba Cloud gemeldet und die Rückmeldung, die wir erhalten haben, war, sie weiterhin zu beobachten. Dies kann durch ein vorübergehendes Problem mit der Netzwerkleitung des Benutzers verursacht werden.
Da dieses Problem in diesem Zeitraum nicht aufgetreten ist und kein anderer Benutzer dieses Problem gemeldet hat, haben wir auch die Vorgehensweise zur weiteren Beobachtung genehmigt.
(Nach unserer späteren Analyse kann der 502 Bad Gateway-Fehler durch eine vorübergehende hohe Auslastung des Clusters verursacht werden)
Gegen 17:20 Uhr nachmittags stießen auch wir selbst auf einen 502 Bad Gateway-Fehler, der lange anhielt ca. 1-2 Minuten. Siehe das Bild unten: 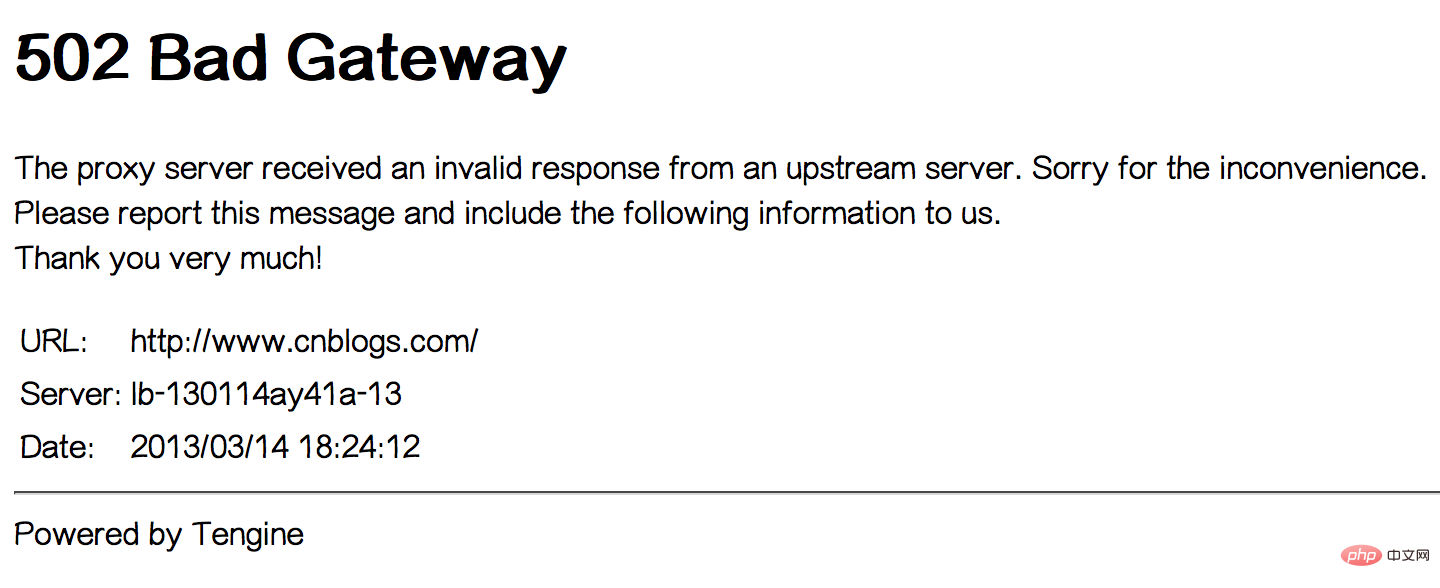
Während des Problems haben wir uns schnell bei den beiden Cloud-Servern angemeldet, um die Situation zu überprüfen, und festgestellt, dass die Anzahl gleichzeitiger IIS-Verbindungen auf mehr als das 30-fache und Bytes angestiegen ist
Send/sec ist 0 und die Situation ist auf beiden Cloud-Servern gleich. Wir kamen damals zu dem Schluss, dass es kein Problem mit den beiden Cloud-Servern selbst geben sollte. Das Problem könnte in der Netzwerkkommunikation zwischen ihnen und dem Datenbankserver liegen.
Brief. Wir werden diese Situation weiterhin über Arbeitsaufträge an Alibaba Cloud melden.
Sobald wir den Arbeitsauftrag ausgefüllt hatten, erhielten wir einen Anruf von einem Gärtner, der uns mitteilte, dass das Blog-Backend keine Artikel veröffentlichen könne. Sobald wir es getestet hatten, sei es tatsächlich unmöglich, es zu veröffentlichen, und es wurde ein Datenbank-Timeout-Fehler gemeldet , wie im Bild unten gezeigt: 
Aber Öffnen Sie den vorhandenen Artikel. Die Geschwindigkeit des Artikels ist sehr hoch, was bedeutet, dass er normal gelesen werden kann, es jedoch Probleme beim Schreiben gibt. Melden Sie sich schnell beim Datenbankserver an und überprüfen Sie den Festplatten-IO-Status über den Leistungsmonitor. Tatsächlich liegt ein Problem mit der Festplatten-Schreibleistung vor, wie im Bild unten gezeigt: 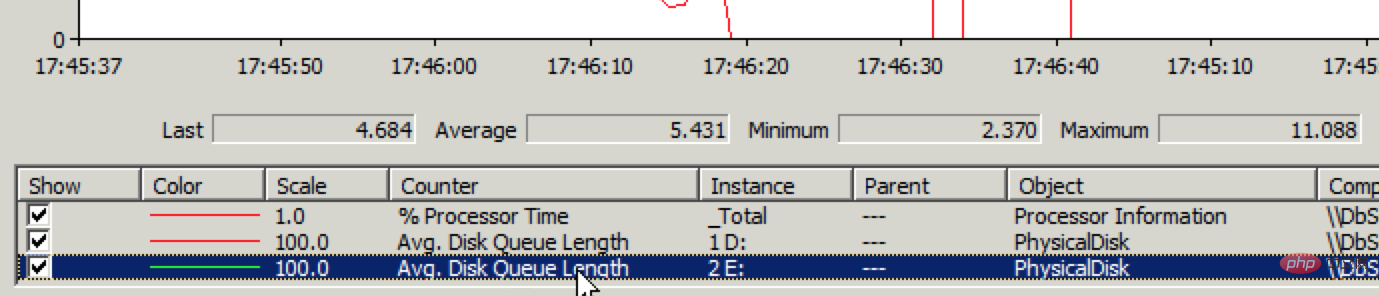

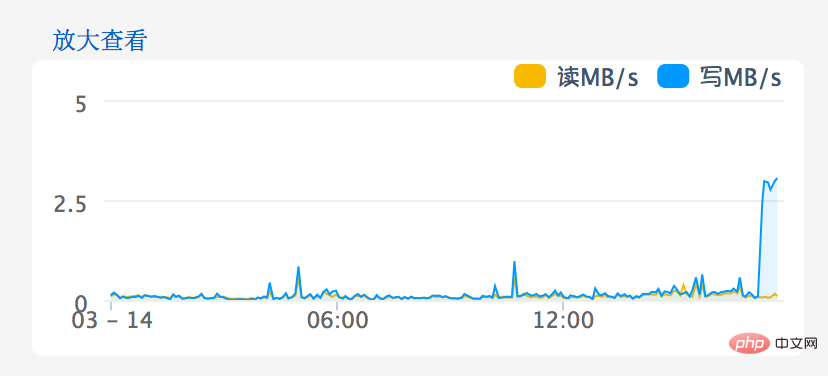
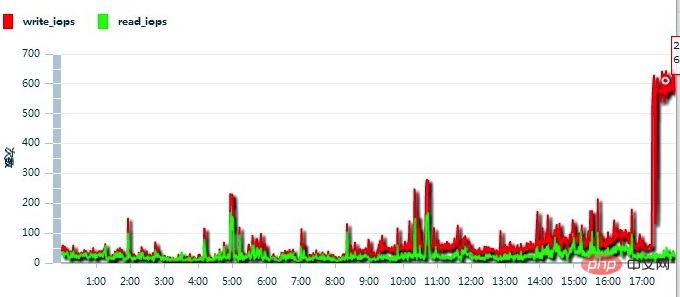
---------------------------------------------------------------- -------------------------------------------------- ---------------------------------------
Fall 3

Dies ist ein Datenbankschreibvorgang Timeout. Fehler, diese Fehlermeldung ist uns noch in Erinnerung. Dies ist mir schon zweimal aufgefallen (am 14. März und am 2. April), beides wurde durch Festplatten-E/A-Probleme auf dem Cloud-Server verursacht, auf dem sich der Datenbankserver befindet.
14:19, wir haben einen Arbeitsauftrag an Alibaba Cloud übermittelt und im Titel ausdrücklich „dringend“ hinzugefügt
14:23, der Alibaba Cloud-Kundendienst hat geantwortet, dass er das von uns eingereichte Problem überprüft; 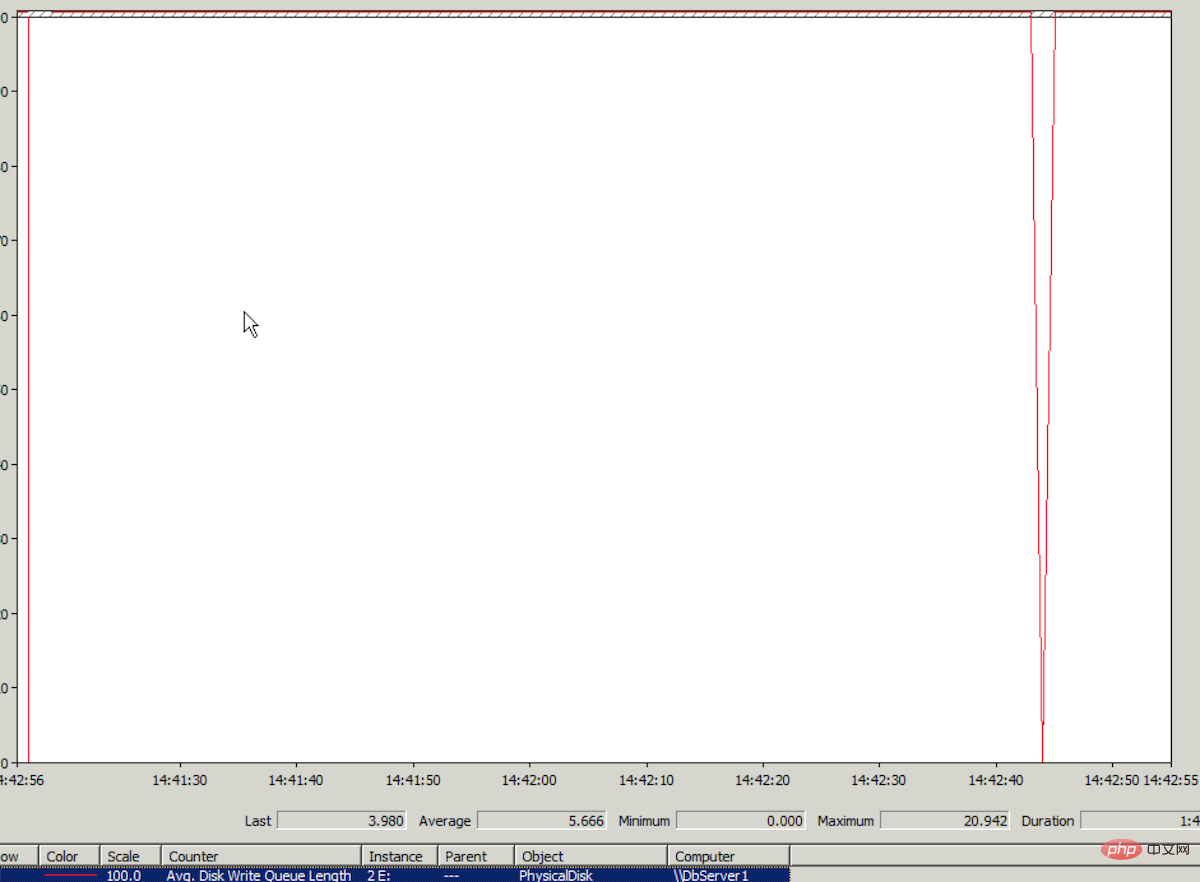
Um 14:42 Uhr gab es keine weiteren Neuigkeiten vom Alibaba Cloud-Kundendienst, daher antworteten wir: „Wenn das Problem nicht in kurzer Zeit gelöst werden kann, hoffen wir, die Cluster-Migration so schnell wie möglich durchführen zu können“ (Dieses Problem wurde durch Cluster gelöst Migration am 14. März, technisches Personal von Alibaba Cloud. Es wurde auch gesagt, dass die einzige Lösung für Festplatten-E/A-Probleme, die durch eine hohe Clusterlast verursacht werden, derzeit die Clustermigration ist wird bearbeitet;
14:59, immer noch keine Neuigkeiten, wir sind besorgt (40 Minuten sind vergangen und es gab keine Erklärung: „Können wir zuerst den Cluster migrieren?“;
Dann, Ich erhielt einen Anruf vom Alibaba Cloud-Kundendienst, in dem mir mitgeteilt wurde, dass die von anderen Cloud-Servern im Cluster belegten Festplatten von der hohen E/A betroffen waren und dass sie sich damit befassen. . .
Nach einer Weile rief der Alibaba Cloud-Kundendienst erneut an und sagte, dass es möglicherweise das System oder die Anwendung in unserem Cloud-Server sei, die dazu geführt habe, dass das Schreiben auf die Serverfestplatte hängengeblieben sei. Lassen Sie uns den Cloud-Server neu starten. (Diese Überlegung kann darauf zurückzuführen sein, dass die Clusterlast zu diesem Zeitpunkt gesunken ist, aber die E/A der Festplatte unseres Cloud-Servers immer noch hoch ist.)
Gegen 15:23 haben wir den Datenbankserver neu gestartet, aber das Problem blieb bestehen.
15:30 Uhr, der Kundenservice von Alibaba Cloud hat sich schließlich für die Clustermigration entschieden (es dauerte 1 Stunde und 10 Minuten von der Übermittlung des Arbeitsauftrags bis zur Entscheidung über die Clustermigration).
15:45 Uhr, die Clustermigration wurde abgeschlossen (die letzte Die Migration dauerte weniger als 5 Minuten, dieses Mal dauerte es 15 Minuten, was laut Alibaba Cloud-Kundendienst auch die längste Zeit ist, die für die Clustermigration erforderlich ist.
Nach der Migration war ich verblüfft Länge) ist immer noch so hoch!
Warum kann diese Cluster-Migration das Problem nicht sofort lösen wie beim letzten Mal? Wir gehen davon aus, dass es zwei mögliche Gründe gibt:
1. Die E/A-Last der Cluster-Festplatte ist nach der Migration immer noch hoch
2. Die Partition mit hoher Festplatten-E/A auf dem Cloud-Server enthält Datenbankprotokolldateien. Es ist möglich, dass Protokollschreibvorgänge in diesem Zeitraum häufiger als üblich stattfinden (ein Anstieg ist jedoch nahezu unmöglich) und alle Protokolldateien sich in derselben Partition befinden. Bereich, der eine bestimmte Grenze der Festplatten-E/A des Cloud-Servers überschreitet, was zu einem starken Rückgang der Festplatten-E/A-Leistung führt (die Wahrscheinlichkeit ist relativ hoch, basierend auf dem Weg zum Cloud Computing - Nach dem Eintritt in die Alibaba Cloud: Lösen Sie images.cnblogs.com Seltsames Problem mit langsamer Reaktionsgeschwindigkeit. Obwohl bei der vorherigen Verwendung eines physischen Servers die Protokolldateien in derselben Partition abgelegt wurden und dieses Problem nie auftrat, kann die Festplatten-IO-Fähigkeit des Cloud-Servers jetzt nicht mehr mit der des physischen Servers verglichen werden. Verhältnis, und die Festplatten-E/A wird von anderen Cloud-Servern im Cluster konkurriert (Einzelheiten finden Sie unter „Der Weg zum Cloud Computing“ – nach dem Wechsel zu Alibaba Cloud: Die Wurzel des Problems besteht darin, ihr „Menschen“ zu kaufen, aber nicht ihr „Herz“) " ).
Egal welcher Grund es ist, es gibt nur einen und letzten Ausweg, um das Problem zu lösen: Reduzieren Sie den E/A-Druck auf der Festplattenpartition, auf der sich die Protokolldatei befindet.
Wie kann man Stress reduzieren? Kaufen Sie gemäß den „Kleinen Rezepten zur Verbesserung der gesamten Festplatten-E/A-Leistung“ im Artikel „Einige Erfahrungen nach dem Umzug in die Alibaba Cloud“ einen weiteren Speicherplatz und schreiben Sie dann die Datenbank CNBlogsText (große Textdaten), in der Blog-Inhalte gespeichert werden führt dazu, dass Festplatten-IO-Protokolldateien (Hochdruck) auf einer separaten Festplattenpartition gespeichert werden.
In SQL Server ist das Verschieben von Datenbankprotokolldateien von einer Festplattenpartition auf eine andere nicht online möglich. Sie müssen zuerst die Datenbank trennen, dann die Protokolldatei auf die Zielpartition kopieren und dann die Datenbank beim Anhängen anhängen und den Speicherort der Protokolldatei in einen neuen Pfad ändern.
Da wir keine andere Wahl hatten, führten wir einen Trennvorgang für die CNBlogsText-Datenbank durch und entschieden uns, die Verbindungen zu trennen. Unerwartet passierte während des Trennvorgangs ein Fehler und der Fehler lautete:
Transaktion (Prozess-ID 124) war bei Sperrressourcen mit einem anderen Prozess blockiert und wurde als Deadlock-Opfer ausgewählt. Führen Sie die Transaktion erneut aus.在 Während des Trennvorgangs kam es zu einem Deadlock, der dann „geopfert“ wurde. Was verwirrend ist, ist die Frage, wie es trotzdem zu einem Deadlock kommen kann, wenn die Verbindungen nicht getrennt werden. Kann fallen Verbindungen finden statt, bevor der Trennvorgang offiziell beginnt. Während des Trennvorgangs wird auch ein Datenbankschreibvorgang ausgeführt. Der Schreibvorgang löst zu diesem Zeitpunkt einen Deadlock aus. Warum Warum sollte die Loslösung geopfert werden? Unverständlich.
Nachdem die Trennung fehlschlägt, befindet sich die CNBlogsText-Datenbank im Einzelbenutzerstatus. Weiter trennen, derselbe Fehler, das gleiche „geopfert“.
Also, den SQL Server-Dienst neu gestartet. Nach dem Neustart ändert sich der Status der CNBlogsText-Datenbank in „In Wiederherstellung“.
Die Zeit ist 16:45 Uhr erreicht.
Ich habe noch nie einen solchen „In Recovery“-Zustand erlebt, ich weiß nicht, wie ich damit umgehen soll, und ich traue mich nicht, vorschnell zu handeln.
Nach einer Weile habe ich die Datenbankliste von SQL Server aktualisiert und die CNBlogsText-Datenbank zeigte ihren vorherigen Einzelbenutzerstatus an. (Es stellt sich heraus, dass SQL Server nach dem Neustart automatisch in den Status „In Wiederherstellung“ und dann in den Status „Einzelbenutzer“ wechselt.)
Bezüglich des Problems mit dem Status „Einzelbenutzer“ habe ich im Arbeitsauftrag den Alibaba Cloud-Kundendienst konsultiert Der Kundendienst kontaktierte den Datenbankentwickler und erhielt Folgendes: Der Vorschlag besteht darin, diesen Vorgang auszuführen: alter Database $db_name SET multi_user
Führen Sie also diesen SQL-Befehl aus:
exec sp_dboption 'CNBlogsText', N'single', N'false'
Eine Fehlermeldung wird angezeigt:
Database 'CNBlogsText' is already open and can only have one user at a time.
Der Status eines einzelnen Benutzers bleibt gleich. Dieser Fehler kann darauf zurückzuführen sein, dass die Datenbank ständig Eingabevorgänge schreibt und nur die einzige Datenbankverbindung verhindert, die im Einzelbenutzerstatus zulässig ist.
(更新:后来从阿里云DBA那学习到解决这个问题的方法:
select spid from sys.sysprocesses where dbid=DB_ID('dbname'); --得到当前占用数据库的进程id kill [spid] go alter login [username] disable --禁用新的访问 go use cnblogstext go alter database cnblogstext set multi_user with rollback immediate go
)
当时的情形下,我们不够冷静,急着想完成detach操作。觉得屏蔽CNBlogsText数据库的所有写入操作可能需要禁止这台服务器的所有数据库连接,这样会影响整站的正常访问,所以没从这个角度下手。
这时时间已经到了17:08。
我们也准备了最最后一招,假如实在detach不了,假如日志文件也出了问题,我们可以通过数据文件恢复这个数据库。这个场景我们遇到过,也实际成功操作过,详见:SQL Server 2005数据库日志文件损坏的情况下如何恢复数据库。所需的SQL语句如下:
use master alter database dbname set emergency declare @databasename varchar(255) set @databasename='dbname' exec sp_dboption @databasename, N'single', N'true' --将目标数据库置为单用户状态 dbcc checkdb(@databasename,REPAIR_ALLOW_DATA_LOSS) dbcc checkdb(@databasename,REPAIR_REBUILD) exec sp_dboption @databasename, N'single', N'false'--将目标数据库置为多用户状态
即使最最后一招也失败了,我们在另外一台云服务器上有备份,在异地也有备份,都有办法恢复,只不过需要的恢复时间更长一些。
想到这些,内心平静了一些,认识到当前最重要的是抛开内疚、紧张、着急,冷静面对。
我们在工单中继续咨询阿里云客服,阿里云客服联系了数据库工程师,让我们加一下这位工程师的阿里旺旺。
我们的电脑上没装阿里旺旺,于是打算自己再试试,如果还是解决不了,再求助阿里云的数据库工程师。
在网上找了一个方法:SET DEADLOCK_PRIORITY NORMAL(来源),没有效果。
时间已经到了17:38。
这时,我们冷静地分析一下:detach时,因为死锁“被牺牲”;从单用户改为多用户时,提示“Database 'CNBlogsText' is already open and can only have one user at a time.”。可能都是因为程序中不断地对这个数据库有写入操作。试试修改一下程序,看看能不能屏蔽所有对这个数据库的写入操作,然后再将数据库恢复为多 用户状态。
修改好程序,18:00之后进行了更新。没想到更新之后,将单用户改为多用户的SQL就能执行了:
exec sp_dboption 'CNBlogsText', N'single', N'false'
于是,Single User状态消失,CNBlogsText数据库恢复了正常状态,然后尝试detach,一次成功。
接着将日志文件复制到新购的磁盘分区中,以新的日志路径attach数据库。attach成功之后,CNBlogsText数据库恢复正常,博客后台可以正常发布博文,CNBlogsText数据库日志文件所在分区的磁盘IO(单独的磁盘分区)也正常。问题就这么解决了。
当全部恢复正常,如释重负的时候,时间已经到了18:35。
原以为可以用更多的内存弥补云服务器磁盘IO性能低的不足。但万万没想到,云服务器的硬伤不是在磁盘IO性能低,而是在磁盘IO不稳定。
更多相关知识,请访问:PHP中文网!
Das obige ist der detaillierte Inhalt vonWas ist der Hauptengpass des Clusters?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!