
Heim >häufiges Problem >Die neueste Version von 2023 68 Redis-Interviewfragen (Sammlung)
Die neueste Version von 2023 68 Redis-Interviewfragen (Sammlung)

- coldplay.xixiOriginal
- 2020-08-05 15:49:0911462Durchsuche
Der Artikel ist zu lang, es wird empfohlen, ihn zuerst zu speichern und langsam zu lesen!
Redis (Remote Dictionary Server) ist eine Open-Source-(BSD-lizenzierte) leistungsstarke, nicht-relationale (NoSQL) Schlüsselwertdatenbank, die in der Sprache C geschrieben ist.

Redis kann Zuordnungen zwischen Schlüsseln und fünf verschiedenen Arten von Werten speichern. Der Schlüsseltyp kann nur eine Zeichenfolge sein und es werden nur fünf Datentypen unterstützt: Zeichenfolge, Liste, Menge, Hash-Tabelle und geordnete Menge.
Anders als bei herkömmlichen Datenbanken werden Redis-Daten im Speicher gespeichert, sodass die Lese- und Schreibgeschwindigkeit sehr hoch ist. Daher wird Redis häufig in Cache-Richtung verwendet und kann mehr als 100.000 Lese- und Schreibvorgänge verarbeiten pro Sekunde. Dies ist die schnellste bekannte Schlüsselwert-Datenbank. Darüber hinaus wird Redis häufig für verteilte Sperren verwendet. Darüber hinaus unterstützt Redis Transaktionen, Persistenz, LUA-Skripte, LRU-gesteuerte Ereignisse und verschiedene Clusterlösungen.

Lassen Sie uns heute über Redis-Interviewfragen sprechen, um uns auf das Interview nach der Wiederaufnahme der Arbeit vorzubereiten.
1. Übersicht
1. Was sind die Vor- und Nachteile von Redis
Vorteile
Lese- und Schreibleistung: Hervorragend, Redis kann mit einer Geschwindigkeit von 110.000 Mal/s lesen und mit einer Geschwindigkeit von 81.000 Mal/s schreiben.
Unterstützt Datenpersistenz und unterstützt zwei Persistenzmethoden: AOF und RDB.
Unterstützt Transaktionen von Redis. Gleichzeitig unterstützt Redis auch die atomare Ausführung nach der Zusammenführung mehrerer Vorgänge.
Reichhaltige Datenstrukturen, zusätzlich zur Unterstützung von Zeichenfolgentypwerten werden auch Hash-, Set-, Zset-, Listen- und andere Datenstrukturen unterstützt.
Unterstützt die Master-Slave-Replikation. Der Host synchronisiert die Daten automatisch mit dem Slave und ermöglicht so eine Lese- und Schreibtrennung.
Nachteile
Die Datenbankkapazität ist durch den physischen Speicher begrenzt und kann nicht zum leistungsstarken Lesen und Schreiben großer Datenmengen verwendet werden hauptsächlich auf kleinere Datenmengen beschränkt. Hochleistungsoperationen und Berechnungen.
Redis verfügt nicht über automatische Fehlertoleranz- und Wiederherstellungsfunktionen. Die Ausfallzeit der Host- und Slave-Maschinen führt dazu, dass einige Front-End-Lese- und Schreibanforderungen fehlschlagen. Sie müssen warten, bis die Maschine neu gestartet oder manuell umgeschaltet wird die wiederherzustellende Front-End-IP.
Einige Daten konnten nicht rechtzeitig mit dem Slave-Computer synchronisiert werden, bevor der Computer ausfiel. Nach dem Wechsel der IP kommt es zu Dateninkonsistenzen, die die Verfügbarkeit des Systems verringern.
Redis unterstützt die Online-Erweiterung nur schwer. Wenn die Clusterkapazität die Obergrenze erreicht, wird die Online-Erweiterung sehr kompliziert. Um dieses Problem zu vermeiden, muss das Betriebs- und Wartungspersonal sicherstellen, dass genügend Platz vorhanden ist, wenn das System online geht, was zu einer großen Ressourcenverschwendung führt.
2. Warum Redis verwenden/Warum Cache verwenden?
Wir betrachten dieses Problem hauptsächlich unter den beiden Gesichtspunkten „hohe Leistung“ und „hohe Parallelität“.
Hohe Leistung:
Wenn der Benutzer zum ersten Mal auf einige Daten in der Datenbank zugreift. Dieser Vorgang ist langsamer, da er von der Festplatte gelesen wird. Speichern Sie die Daten, auf die der Benutzer zugreift, im Cache, sodass die Daten beim nächsten Zugriff direkt aus dem Cache abgerufen werden können. Der Operationscache dient dazu, den Speicher direkt zu betreiben, sodass die Geschwindigkeit recht hoch ist. Wenn sich die entsprechenden Daten in der Datenbank ändern, ändern Sie einfach synchron die entsprechenden Daten im Cache!
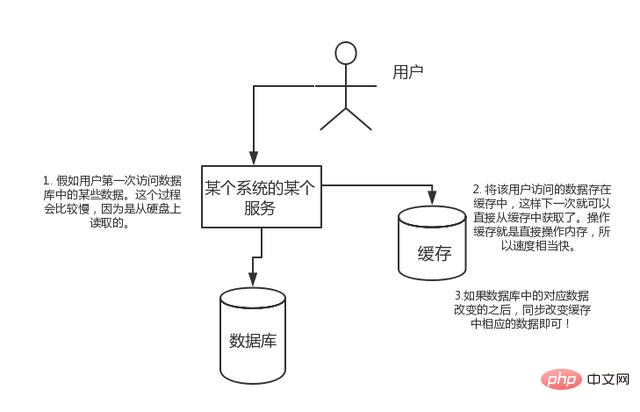
Hohe Parallelität:
Die Anforderungen, denen der Direktoperationscache standhalten kann, sind weitaus größer als der direkte Zugriff darauf die Datenbank, also Wir können erwägen, einige Daten in der Datenbank in den Cache zu übertragen, sodass einige Benutzeranforderungen direkt in den Cache gelangen, ohne die Datenbank zu durchlaufen.
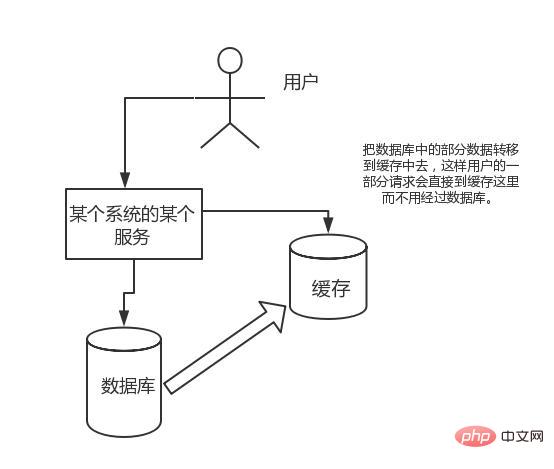
3. Warum Redis anstelle von Map/Guava zum Caching verwenden?
Der Cache ist in lokalen Cache und verteilten Cache unterteilt. Am Beispiel von Java wird lokales Caching mithilfe der integrierten Karte oder Guave implementiert. Die Hauptfunktionen sind leichtgewichtig und schnell. Der Lebenszyklus endet mit der Zerstörung der JVM und im Fall mehrerer Instanzen jeder Instanz muss gespeichert werden und der Cache ist nicht konsistent.
Die Verwendung von Redis oder Memcached wird als verteilter Cache bezeichnet. Bei mehreren Instanzen teilt sich jede Instanz einen Datencache und der Cache ist konsistent. Der Nachteil besteht darin, dass der Redis- oder Memcached-Dienst hochverfügbar gehalten werden muss und die gesamte Programmarchitektur relativ komplex ist.
4. Warum ist Redis so schnell?
1) Die meisten Anfragen basieren vollständig auf dem Speicher und sind sehr schnell. Die Daten werden im Speicher gespeichert, ähnlich wie bei HashMap. Der Vorteil von HashMap besteht darin, dass die Zeitkomplexität der Suche und Operation O(1) ist. Die Datenstruktur ist einfach und die Datenoperation auch einfach. Die Datenstruktur in Redis ist speziell entwickelt
3) Durch die Verwendung eines einzelnen Threads werden unnötige Kontextwechsel und Konkurrenzbedingungen vermieden, und es gibt keinen durch mehrere Prozesse oder Threads verursachten Wechsel, der die CPU verbraucht. Es besteht keine Notwendigkeit, verschiedene Sperrprobleme zu berücksichtigen, und es gibt keinen Sperr- oder Freigabevorgang . Es gibt keinen Leistungsverbrauch aufgrund möglicher Deadlocks.
4) Verwenden Sie ein Mehrkanal-I/O-Multiplex-Modell, nicht blockierendes IO Client Die Kommunikationsanwendungsprotokolle sind unterschiedlich, denn wenn das allgemeine System Systemfunktionen aufruft, verschwendet es eine gewisse Zeit zum Verschieben und Anfordern von Datentypen Gibt es in Redis Datentypen?
Zähler
: Sie können Inkrementierungs- und Dekrementierungsoperationen für String ausführen, um die Zählerfunktion zu realisieren. Redis, eine In-Memory-Datenbank, verfügt über eine sehr hohe Lese- und Schreibleistung und eignet sich sehr gut zum Speichern häufiger Lese- und Schreibzahlen.Cache
: Legen Sie Hotspot-Daten im Speicher ab, legen Sie die maximale Speichernutzung und Eliminierungsstrategie fest, um die Cache-Trefferquote sicherzustellen.Sitzungscache : Redis kann verwendet werden, um Sitzungsinformationen mehrerer Anwendungsserver einheitlich zu speichern. Wenn der Anwendungsserver die Sitzungsinformationen des Benutzers nicht mehr speichert, hat er keinen Status mehr. Ein Benutzer kann einen beliebigen Anwendungsserver anfordern, wodurch eine hohe Verfügbarkeit und Skalierbarkeit einfacher erreicht wird.
: Redis kann verwendet werden, um Sitzungsinformationen mehrerer Anwendungsserver einheitlich zu speichern. Wenn der Anwendungsserver die Sitzungsinformationen des Benutzers nicht mehr speichert, hat er keinen Status mehr. Ein Benutzer kann einen beliebigen Anwendungsserver anfordern, wodurch eine hohe Verfügbarkeit und Skalierbarkeit einfacher erreicht wird.
Full Page Cache (FPC): Zusätzlich zu den grundlegenden Sitzungstoken bietet Redis auch eine sehr einfache FPC-Plattform. Am Beispiel von Magento stellt Magento ein Plugin zur Verfügung, um Redis als Full-Page-Cache-Backend zu nutzen. Darüber hinaus verfügt Pantheon für WordPress-Benutzer über ein sehr gutes Plug-in wp-redis, das Ihnen dabei helfen kann, die von Ihnen durchsuchten Seiten so schnell wie möglich zu laden.
Nachschlagetabelle: Beispielsweise eignen sich DNS-Einträge für die Speicherung mit Redis. Die Nachschlagetabelle ähnelt dem Cache und nutzt außerdem die schnelle Nachschlagefunktion von Redis. Der Inhalt der Nachschlagetabelle kann jedoch nicht ungültig gemacht werden, während der Inhalt des Caches nicht ungültig gemacht werden kann, da der Cache nicht als zuverlässige Datenquelle dient.
Nachrichtenwarteschlange (Veröffentlichungs-/Abonnementfunktion): Liste ist eine doppelt verknüpfte Liste, die Nachrichten über lpush und rpop schreiben und lesen kann. Am besten verwenden Sie jedoch Messaging-Middleware wie Kafka und RabbitMQ.
Verteilte Sperrenimplementierung: In einem verteilten Szenario können Sperren in einer eigenständigen Umgebung nicht zum Synchronisieren von Prozessen auf mehreren Knoten verwendet werden. Sie können den mit Redis gelieferten SETNX-Befehl verwenden, um verteilte Sperren zu implementieren. Darüber hinaus können Sie auch die offiziell bereitgestellte RedLock-Implementierung für verteilte Sperren verwenden.
Sonstiges: Set kann Operationen wie Schnittmenge und Vereinigung implementieren und so Funktionen wie gemeinsame Freunde realisieren. ZSet kann geordnete Operationen implementieren, um Funktionen wie Rankings zu erreichen.
Zusammenfassung 2
Im Vergleich zu anderen Caches hat Redis einen sehr großen Vorteil, nämlich die Unterstützung mehrerer Datentypen. Datentypbeschreibungszeichenfolge Zeichenfolge, das einfachste k-v-Speicher-Hashhash-Format, Wert ist Feld und Wert, geeignet für Szenarien wie ID-Detail. Liste ist eine einfache Liste, eine sequentielle Liste, unterstützt das Einfügen von Daten am Anfang oder am Ende des Satzes, eine ungeordnete Liste, schnelle Suchgeschwindigkeit, geeignet für die Verarbeitung von Schnittmengen, Vereinigungen und Differenzsätzen. Sortierter Satz geordneter Satz
Tatsächlich durch Eigenschaften der oben genannten Datentypen. Grundsätzlich können Sie sich geeignete Anwendungsszenarien vorstellen. string – geeignet für den einfachsten k-v-Speicher, ähnlich der zwischengespeicherten Speicherstruktur, SMS-Bestätigungscode, Konfigurationsinformationen usw., verwenden Sie diesen Typ zum Speichern.
Hash – Im Allgemeinen ist der Schlüssel eine ID oder eine eindeutige Kennung, und der Wert entspricht den Details. Zum Beispiel Produktdetails, persönliche Daten, Nachrichtendetails usw.
Liste – Da die Liste geordnet ist, eignet sie sich besser zum Speichern einiger geordneter und relativ fester Daten. Wie Provinz- und Stadttabellen, Wörterbuchtabellen usw. Da die Liste geordnet ist, kann sie nach der Schreibzeit sortiert werden, z. B. nach dem neuesten ***, der Nachrichtenwarteschlange usw.
Set – Es kann einfach als ID-Listen-Modell verstanden werden, z. B. welche Freunde eine Person auf Weibo hat. Das Beste an Set ist, dass es Schnitt-, Vereinigungs- und Differenzoperationen für zwei Sets bereitstellen kann. Zum Beispiel: Finden Sie gemeinsame Freunde zwischen zwei Personen usw.
Sorted Set– ist eine erweiterte Version von Set, die einen Score-Parameter hinzufügt, der automatisch nach dem Score-Wert sortiert. Es eignet sich besser für Daten wie die Top 10, die nicht nach der Einfügezeit sortiert sind.
Wie oben erwähnt, ist Redis zwar keine so komplexe Datenstruktur wie eine relationale Datenbank, kann aber auch für viele Szenarien geeignet sein, einschließlich mehr als nur allgemeiner Cache-Datenstrukturen. Das Verständnis der für jede Datenstruktur geeigneten Geschäftsszenarien trägt nicht nur dazu bei, die Entwicklungseffizienz zu verbessern, sondern auch die Leistung von Redis effektiv zu nutzen.
3. Persistenz
7. Was ist Redis-Persistenz?
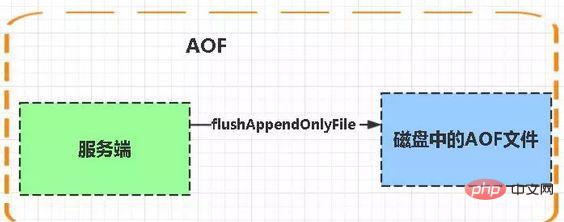
Persistenz besteht darin, die Speicherdaten auf die Festplatte zu schreiben, um zu verhindern, dass die Speicherdaten verloren gehen, wenn der Dienst ausfällt. 8. Was ist der Persistenzmechanismus von Redis? Was sind die Vor- und Nachteile jedes einzelnen? Redis bietet zwei Persistenzmechanismen, RDB (Standard) und AOF-Mechanismus: RDB: ist die Abkürzung Snapshot von Redis DataBase. RDB ist die Standardpersistenzmethode von Redis. Die Speicherdaten werden nach einem bestimmten Zeitraum in Form eines Snapshots auf der Festplatte gespeichert und die entsprechende generierte Datendatei heißt dump.rdb. Der Snapshot-Zeitraum wird über den Speicherparameter in der Konfigurationsdatei definiert. Vorteile: 1 Es gibt nur eine Datei dump.rdb, was für die Persistenz praktisch ist. 2. Gute Katastrophentoleranz, eine Datei kann auf einer sicheren Festplatte gespeichert werden. 3. Um die Leistung zu maximieren, verzweigen Sie den untergeordneten Prozess, um den Schreibvorgang abzuschließen, und lassen Sie den Hauptprozess weiterhin Befehle verarbeiten, sodass die E/A maximiert wird. Verwenden Sie einen separaten Unterprozess für die Persistenz, und der Hauptprozess führt keine E/A-Vorgänge aus, um die hohe Leistung von Redis sicherzustellen. 4 Wenn der Datensatz groß ist, ist die Starteffizienz höher als bei AOF. Nachteile: 1. Geringe Datensicherheit. RDB wird in bestimmten Abständen beibehalten, wenn Redis zwischen der Persistenz fehlschlägt. Daher ist diese Methode besser geeignet, wenn die Datenanforderungen nicht streng sind als Aof-Dokument gespeichert. Die AOF-Persistenz (d. h. Append Only File Persistence) zeichnet jeden von Redis ausgeführten Schreibbefehl in einer separaten Protokolldatei auf. Wenn Redis neu gestartet wird, werden die persistenten Daten aus Dateien neu aufgezeichnet. Wenn beide Methoden gleichzeitig aktiviert sind, räumt Redis bei der Datenwiederherstellung der AOF-Wiederherstellung Vorrang ein. 1. Datensicherheit, AOF-Persistenz kann mit dem appendfsync-Attribut konfiguriert werden, wobei jede Befehlsoperation immer in der AOF-Datei aufgezeichnet wird. 2. Schreiben Sie Dateien im Anhängemodus. Selbst wenn der Server mittendrin ausfällt, können Sie das Datenkonsistenzproblem mit dem Redis-Check-Aof-Tool lösen. 3. Rewrite-Modus des AOF-Mechanismus. Bevor die AOF-Datei neu geschrieben wird (Befehle werden zusammengeführt und neu geschrieben, wenn die Datei zu groß ist), können Sie einige der Befehle löschen (z. B. „flushall“). 1 als RDB-Dateien. Größe und langsame Wiederherstellung. 2. Wenn der Datensatz groß ist, ist die Starteffizienz geringer als bei RDB. AOF-Dateien werden häufiger aktualisiert als RDB. Verwenden Sie daher zuerst AOF, um Daten wiederherzustellen. AOF ist sicherer und größer als RDB. RDB-Leistung ist besser als AOF. Wenn beide konfiguriert sind, wird AOF zuerst geladen Um eine mit PostgreSQL vergleichbare Datensicherheit zu erreichen, sollten Sie beide Persistenzfunktionen nutzen. In diesem Fall wird beim Neustart von Redis zuerst die AOF-Datei geladen, um die Originaldaten wiederherzustellen, da unter normalen Umständen der von der AOF-Datei gespeicherte Datensatz vollständiger ist als der von der RDB-Datei gespeicherte Datensatz. Wenn Ihnen Ihre Daten am Herzen liegen, Sie sich aber einen Datenverlust innerhalb weniger Minuten leisten können, können Sie einfach RDB-Persistenz verwenden. Es gibt viele Benutzer, die nur AOF-Persistenz verwenden. Diese Methode wird jedoch nicht empfohlen, da die regelmäßige Generierung von RDB-Snapshots für die Datenbanksicherung sehr praktisch ist und RDB Datensätze schneller wiederherstellt als AOF. Darüber hinaus können durch die Verwendung von RDB auch Fehler vermieden werden AOF-Programme. Wenn Sie möchten, dass Ihre Daten nur dann vorhanden sind, wenn der Server läuft, können Sie auch keine Persistenzmethode verwenden. Wenn Redis als Cache verwendet wird, verwenden Sie konsistentes Hashing, um eine dynamische Erweiterung und Kontraktion zu erreichen. Wenn Redis als persistenter Speicher verwendet wird, muss eine feste Schlüssel-zu-Knoten-Zuordnungsbeziehung verwendet werden, und die Anzahl der Knoten kann nach ihrer Festlegung nicht mehr geändert werden. Andernfalls (d. h. wenn sich Redis-Knoten dynamisch ändern müssen) muss ein System verwendet werden, das Daten zur Laufzeit neu ausgleichen kann, und derzeit ist dies nur für Redis-Cluster möglich. 4. Speicherbezogen Wenn die Größe des Redis-Speicherdatensatzes auf eine bestimmte Größe ansteigt, wird die Dateneliminierungsstrategie implementiert. Die Speichereliminierungsstrategie von Redis bezieht sich auf den Umgang mit Daten, die neu geschrieben werden müssen und zusätzlichen Speicherplatz erfordern, wenn der Speicher von Redis für das Caching nicht ausreicht. noeviction : Wenn der Speicher nicht ausreicht, um die neu geschriebenen Daten aufzunehmen, meldet der neue Schreibvorgang einen Fehler. allkeys-lru: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, entfernen Sie im Schlüsselbereich den zuletzt verwendeten Schlüssel. (Dies wird am häufigsten verwendet) allkeys-random: Wenn der Speicher nicht ausreicht, um die neu geschriebenen Daten aufzunehmen, wird ein Schlüssel zufällig aus dem Schlüsselraum entfernt. Selektive Entfernung des Schlüsselraums mit festgelegter Ablaufzeit volatile-lru: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, entfernen Sie im Schlüsselraum mit festgelegter Ablaufzeit den zuletzt verwendeten Schlüssel. volatil-zufällig: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, wird ein Schlüssel nach dem Zufallsprinzip aus dem Schlüsselraum mit festgelegter Ablaufzeit entfernt. volatile-ttl: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, werden im Schlüsselraum mit festgelegter Ablaufzeit zuerst Schlüssel mit einer früheren Ablaufzeit entfernt. Zusammenfassung Die Auswahl der Speichereliminierungsstrategie von Redis hat keinen Einfluss auf die Verarbeitung abgelaufener Schlüssel. Die Speichereliminierungsrichtlinie wird verwendet, um Daten zu verarbeiten, die zusätzlichen Speicherplatz benötigen, wenn der Speicher nicht ausreicht. Die Ablaufrichtlinie wird verwendet, um abgelaufene zwischengespeicherte Daten zu verarbeiten. 16. Welche physischen Ressourcen verbraucht Redis hauptsächlich? Speicher. 17. Was passiert, wenn Redis nicht mehr genügend Speicher hat? Wenn die festgelegte Obergrenze erreicht ist, gibt der Redis-Schreibbefehl eine Fehlermeldung zurück (der Lesebefehl kann jedoch weiterhin normal zurückkehren). Oder Sie können den Speicherbeseitigungsmechanismus konfigurieren, und wenn Redis die obere Speichergrenze erreicht, wird der Alte Inhalte werden gelöscht. 18. Wie optimiert Redis den Speicher? Sie können Sammlungstypdaten wie Hash, Liste, sortierter Satz, Satz usw. gut nutzen, da normalerweise viele kleine Schlüsselwerte kompakter zusammen gespeichert werden können. Verwenden Sie so viele Hashes wie möglich (d. h. die in einer Hash-Tabelle gespeicherte Anzahl ist gering) und beanspruchen sehr wenig Speicher. Daher sollten Sie Ihr Datenmodell so weit wie möglich in eine Hash-Tabelle abstrahieren. Wenn Sie beispielsweise ein Benutzerobjekt in Ihrem Websystem haben, legen Sie keinen separaten Schlüssel für den Namen, den Nachnamen, die E-Mail-Adresse und das Passwort des Benutzers fest. Speichern Sie stattdessen alle Informationen des Benutzers in einer Hash-Tabelle. 5. Threading-Modell Redis hat einen Netzwerk-Ereignisprozessor entwickelt, der auf dem Reactor-Modell basiert. Seine Struktur besteht aus 4 Teilen: mehreren Sockets, IO-Multiplexer, Dateiereignis-Dispatcher und Ereignisprozessor. Da der Verbrauch der Dateiereignis-Dispatcher-Warteschlange Single-Threaded ist, wird Redis als Single-Threaded-Modell bezeichnet. Redis hat einen Netzwerk-Ereignisprozessor entwickelt, der auf dem Reactor-Modell basiert. Seine Struktur besteht aus 4 Teilen: mehreren Sockets, IO-Multiplexer, Dateiereignis-Dispatcher und Ereignisprozessor. Da der Verbrauch der Dateiereignis-Dispatcher-Warteschlange Single-Threaded ist, wird Redis als Single-Threaded-Modell bezeichnet. Der Dateiereignishandler verwendet ein E/A-Multiplexing-Programm (Multiplexing), um mehrere Sockets gleichzeitig abzuhören, und ordnet dem Socket je nach der aktuell vom Socket ausgeführten Aufgabe unterschiedliche Ereignishandler zu. Wenn der überwachte Socket bereit ist, Vorgänge wie Verbindungsantwort (Akzeptieren), Lesen (Lesen), Schreiben (Schreiben), Schließen (Schließen) usw. auszuführen, wird das dem Vorgang entsprechende Dateiereignis generiert Zu diesem Zeitpunkt ruft der Datei-Ereignishandler den zuvor dem Socket zugeordneten Ereignishandler auf, um diese Ereignisse zu verarbeiten. Obwohl der Dateiereignishandler im Single-Thread-Modus ausgeführt wird, implementiert der Dateiereignishandler durch die Verwendung eines E/A-Multiplexers zum Abhören mehrerer Sockets sowohl ein leistungsstarkes Netzwerkkommunikationsmodell als auch eine gute Verbindung andere Module im Redis-Server, die ebenfalls im Single-Thread-Modus ausgeführt werden, wodurch die Einfachheit des Single-Thread-Designs in Redis erhalten bleibt. 7. Affären Eine Transaktion ist ein einzelner isolierter Vorgang: Alle Befehle in der Transaktion werden serialisiert und der Reihe nach ausgeführt. Während der Ausführung der Transaktion wird diese nicht durch Befehlsanfragen anderer Clients unterbrochen. Eine Transaktion ist eine atomare Operation: Entweder werden alle Befehle in der Transaktion ausgeführt, oder keiner von ihnen wird ausgeführt. Die Essenz von Redis-Transaktionen ist eine Sammlung von Befehlen wie MULTI, EXEC und WATCH. Transaktionen unterstützen die gleichzeitige Ausführung mehrerer Befehle und alle Befehle in einer Transaktion werden serialisiert. Während des Transaktionsausführungsprozesses werden die Befehle in der Warteschlange der Reihe nach ausgeführt, und von anderen Clients übermittelte Befehlsanforderungen werden nicht in die Befehlssequenz zur Transaktionsausführung eingefügt. Zusammenfassend: Eine Redis-Transaktion ist eine einmalige, sequentielle und exklusive Ausführung einer Reihe von Befehlen in einer Warteschlange. 22. Drei Phasen der Redis-Transaktion MULTI wird in die Warteschlange gestellt. 23. Befehle für Redis-Transaktionen Die Redis-Transaktionsfunktion wird durch die vier Grundelemente MULTI, EXEC, DISCARD und WATCH implementiert. Redis serialisiert alle Befehle in einer Transaktion und führt sie dann der Reihe nach aus. 1)redis unterstützt kein Rollback, „Redis führt kein Rollback durch, wenn eine Transaktion fehlschlägt, sondern führt die verbleibenden Befehle weiterhin aus“, sodass die Interna von Redis einfach und schnell bleiben können. 2)Wenn bei einem Befehl in einer Transaktion ein Fehler auftritt, werden nicht alle Befehle ausgeführt. Wenn bei einer Transaktion ein Fehler auftritt, wird der richtige Befehl ausgeführt. Der WATCH-Befehl ist eine optimistische Sperre, die Check-and-Set-Verhalten (CAS) für Redis-Transaktionen bereitstellt. Ein oder mehrere Schlüssel können überwacht werden. Sobald einer der Schlüssel geändert (oder gelöscht) wird, werden nachfolgende Transaktionen nicht ausgeführt und die Überwachung wird bis zum EXEC-Befehl fortgesetzt. Der Befehl MULTI wird zum Starten einer Transaktion verwendet und gibt immer OK zurück. Nachdem MULTI ausgeführt wurde, kann der Client weiterhin beliebig viele Befehle an den Server senden. Diese Befehle werden nicht sofort ausgeführt, sondern in eine Warteschlange gestellt. Beim Aufruf des EXEC-Befehls werden alle Befehle in der Warteschlange ausgeführt . EXEC: Befehle in allen Transaktionsblöcken ausführen. Gibt die Rückgabewerte aller Befehle innerhalb des Transaktionsblocks zurück, geordnet in der Reihenfolge der Befehlsausführung. Wenn der Vorgang unterbrochen wird, wird der leere Wert Null zurückgegeben. Durch Aufrufen von DISCARD kann der Client die Transaktionswarteschlange leeren und die Ausführung der Transaktion aufgeben, und der Client verlässt den Transaktionsstatus. Der Befehl UNWATCH kann die Überwachung aller Tasten durch die Uhr abbrechen. 24. Überblick über das Transaktionsmanagement (ACID) Atomizität: Atomizität bedeutet, dass eine Transaktion eine unteilbare Arbeitseinheit ist und alle Vorgänge in einer Transaktion stattfinden. Die Integrität der Daten vor und nach einer Transaktion muss konsistent bleiben. Wenn mehrere Transaktionen gleichzeitig ausgeführt werden, sollte die Ausführung einer Transaktion keinen Einfluss auf die Ausführung anderer Transaktionen haben. Persistenz bedeutet, dass die Änderungen an den Daten in der Datenbank dauerhaft sind, sobald eine Transaktion festgeschrieben wurde, und selbst wenn die Datenbank ausfällt, sollte dies keine Auswirkungen darauf haben. Andere Funktionen werden nicht unterstützt. Transaktionen sind auch dauerhaft, wenn der Server im AOF-Persistenzmodus ausgeführt wird und der Wert der Option appendfsync immer ist. Redis ist ein Einzelprozessprogramm und garantiert, dass die Transaktion beim Ausführen der Transaktion nicht unterbrochen wird. Die Transaktion kann ausgeführt werden, bis alle Befehle in der Transaktionswarteschlange ausgeführt sind. Daher sind Redis-Transaktionen immer isoliert. 26. Garantiert die Redis-Transaktion Atomizität und unterstützt sie Rollback? In Redis wird ein einzelner Befehl atomar ausgeführt, es ist jedoch nicht garantiert, dass Transaktionen atomar sind und es gibt kein Rollback. Wenn ein Befehl in der Transaktion nicht ausgeführt werden kann, werden die verbleibenden Befehle trotzdem ausgeführt. Basierend auf Lua-Skripten kann Redis sicherstellen, dass die Befehle im Skript einmal und nacheinander ausgeführt werden. Es bietet auch kein Rollback von Transaktionsfehlern Während des Ausführungsfehlers werden die verbleibenden Befehle bis zum Abschluss weiter ausgeführt Basierend auf der Zwischenmarkierungsvariablen wird eine weitere Markierungsvariable verwendet, um zu identifizieren, ob die Transaktion abgeschlossen ist. Beim Lesen von Daten wird zunächst die Markierungsvariable gelesen, um festzustellen, ob die Transaktion abgeschlossen ist Die Transaktion ist abgeschlossen. Dafür muss jedoch zusätzlicher Code implementiert werden, was umständlicher ist. 8. Cluster-Lösung
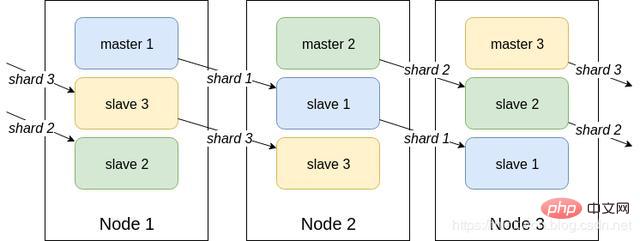
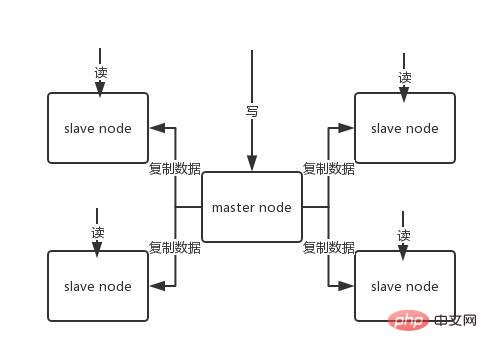
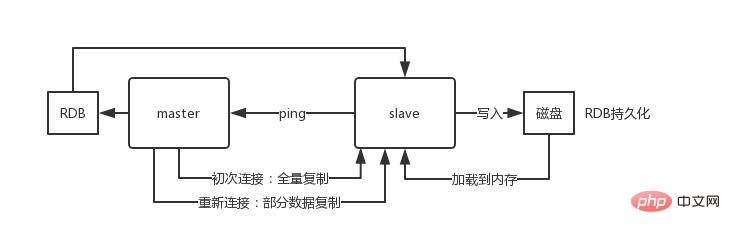
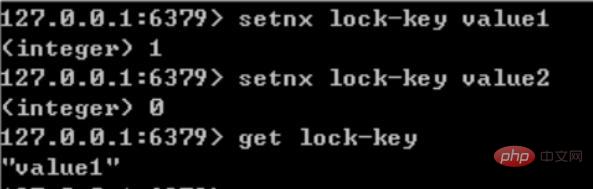
Einführung in Sentinel: Clusterüberwachung Nachrichtenbenachrichtigung: Wenn eine Redis-Instanz ausfällt, ist Sentinel dafür verantwortlich, Nachrichten als Alarmbenachrichtigungen an den Administrator zu senden. Failover Konfigurationscenter: Wenn ein Failover auftritt, benachrichtigen Sie den Client über die neue Master-Adresse. Sentinel wird verwendet, um eine hohe Verfügbarkeit des Redis-Clusters zu erreichen. Er wird auch als Sentinel-Cluster verteilt und arbeitet zusammen. Kernkenntnisse von Sentinel 29. Offizielle Redis-Cluster-Lösung (serverseitige Routing-Abfrage) Einführung Daten behalten keine Konsistenz zwischen mehreren Knoten im selben Shard bei Interner Kommunikationsmechanismus zwischen Knoten Verteilter Adressierungsalgorithmus Hash-Algorithmus (Massen-Cache-Rekonstruktion) Vorteile Hoch Leistung: Der Client ist direkt mit dem Redis-Dienst verbunden, wodurch der Verlust des Proxy-Agenten vermieden wird Unterstützt keine Batch-Operationen (Pipeline-Pipeline-Betrieb) Verteilte Logik und Speichermodulkopplung usw. Einführung Einführung Der Client sendet eine Anfrage an eine Proxy-Komponente, der Proxy analysiert die Daten des Clients, leitet die Anfrage an den richtigen Knoten weiter und antwortet schließlich mit dem Ergebnis an den Client Funktionen Transparent Zugriff, das Geschäftsprogramm muss sich nicht um die Back-End-Redis-Instanz kümmern und die Wechselkosten sind niedrig Proxy-Logik und Speicherlogik sind isoliert Die Proxy-Schicht verfügt über eine weitere Weiterleitung und die Leistung geht verloren Branchen-Open-Source-Lösung Twtter ist Open-Source-Twemproxy Wandoujia Open-Source-Codis 32, Redis-Master-Slave-Architektur Das eigenständige Redis kann QPS im Bereich von Zehntausenden bis Zehntausenden übertragen. Für Caches werden sie im Allgemeinen verwendet, um eine hohe Lesegleichzeitigkeit zu unterstützen. Daher wird die Architektur in eine Master-Slave-Architektur umgewandelt, mit einem Master und mehreren Slaves. Der Master ist für das Schreiben und Kopieren von Daten auf andere Slave-Knoten verantwortlich, und die Slave-Knoten sind für das Lesen verantwortlich. Alle Leseanfragen gehen an Slave-Knoten. Dadurch kann auch problemlos eine horizontale Erweiterung erreicht und eine hohe Leseparallelität unterstützt werden. Redis verwendet den asynchronen Modus zum Kopieren von Daten Ab Redis2.8 bestätigt der Slave-Knoten jedoch jedes Mal die Menge der kopierten Daten. Ein Master-Knoten kann mit mehreren Slave-Knoten konfiguriert werden Knoten; Slave Wenn der Knoten repliziert, blockiert er nicht die normale Arbeit des Masterknotens. Wenn der Slave-Knoten repliziert, blockiert er nicht seine eigenen Abfragevorgänge, sondern verwendet den alten Datensatz, um Dienste bereitzustellen. Aber die Replikation ist abgeschlossen. Manchmal müssen Sie den alten Datensatz löschen und den neuen Datensatz laden. Der Slave-Knoten wird hauptsächlich für die horizontale Erweiterung und Trennung von Lesen und Schreiben verwendet Der erweiterte Slave-Knoten kann den Lesedurchsatz verbessern. Beachten Sie, dass bei Verwendung einer Master-Slave-Architektur empfohlen wird, die Persistenz des Master-Knotens zu aktivieren. Es wird nicht empfohlen, den Slave-Knoten als Daten-Hot-Backup des Master-Knotens zu verwenden Wenn Sie in diesem Fall die Persistenz des Masters deaktivieren, kann der Master-Knoten beschädigt werden. Wenn die Maschine abstürzt und neu startet, sind die Daten leer und die Daten des Slave-Knotens gehen möglicherweise verloren, sobald sie repliziert werden. Darüber hinaus müssen auch verschiedene Backup-Pläne für den Master erstellt werden. Falls alle lokalen Dateien verloren gehen, wählen Sie eine RDB aus der Sicherung aus, um den Master wiederherzustellen. Dadurch wird sichergestellt, dass beim Start Daten vorhanden sind. Auch wenn der später erläuterte Hochverfügbarkeitsmechanismus übernommen wird, kann der Slave-Knoten automatisch den Master übernehmen .Knoten, aber es ist auch möglich, dass der Master-Knoten automatisch neu gestartet wurde, bevor Sentinel den Master-Fehler erkennt, oder dass alle oben genannten Slave-Knotendaten gelöscht werden. Wenn ein Slave-Knoten gestartet wird, sendet er einen PSYNC-Befehl an den Master-Knoten. Wenn dies das erste Mal ist, dass der Slave-Knoten eine Verbindung zum Master-Knoten herstellt, wird eine vollständige Neusynchronisierung und vollständige Kopie ausgelöst. Zu diesem Zeitpunkt startet der Master einen Hintergrundthread und beginnt mit der Generierung einer RDB-Snapshot-Datei. Gleichzeitig werden alle neu empfangenen Schreibbefehle vom Client-Client im Speicher zwischengespeichert. Nachdem die RDB-Datei generiert wurde, sendet der Master die RDB an den Slave. Der Slave schreibt sie zunächst auf die lokale Festplatte und lädt sie dann von der lokalen Festplatte in den Speicher. Wenn ein Netzwerkfehler zwischen dem Slave-Knoten und dem Master-Knoten auftritt und die Verbindung getrennt wird, wird die Verbindung automatisch wiederhergestellt. Nach dem Herstellen der Verbindung kopiert der Master-Knoten nur die fehlenden Daten auf den Slave. Wenn die Slave-Datenbank und die Master-Datenbank die MS-Beziehung herstellen, wird ein SYNC-Befehl an die Master-Datenbank gesendet. Nach Erhalt des SYNC-Befehls beginnt die Master-Datenbank mit dem Speichern Schnappschüsse im Hintergrund erstellen (RDB-Persistenzprozess) und die während des Zeitraums empfangenen Schreibbefehle zwischenspeichern Wenn der Schnappschuss abgeschlossen ist, sendet der Master-Redis die Snapshot-Datei und alle zwischengespeicherten Schreibbefehle an den Slave-Redis Nachdem er sie empfangen hat Redis lädt die Snapshot-Datei und führt die Sammlung aus. Nach dem Empfang des zwischengespeicherten Befehls Nachteile 33 Was ist das Master-Slave-Replikationsmodell? des Redis-Clusters? 34 In einer Produktionsumgebung Wird Redis bereitgestellt? Redis-Cluster, 10 Maschinen, 5 Maschinen werden mit Redis-Master-Instanzen bereitgestellt, und die anderen 5 Maschinen werden mit Redis-Slave-Instanzen bereitgestellt, und 5 Knoten stellen externe Lese- und Schreibdienste bereit Lese- und Schreib-QPS können 50.000 pro Sekunde erreichen, und die maximale Anzahl von 5 Maschinen beträgt 250.000 Lese- und Schreibanforderungen/s. Wie ist die Konfiguration der Maschine? 32G Speicher + 8-Kern-CPU + 1T-Festplatte, aber der dem Redis-Prozess zugewiesene Speicher beträgt 10 g. In allgemeinen Online-Produktionsumgebungen sollte der Speicher von Redis 10 g nicht überschreiten. 5 Maschinen ermöglichen externes Lesen und Schreiben mit insgesamt 50 g Speicher. Da jede Master-Instanz über eine Slave-Instanz verfügt, ist sie hochverfügbar. Wenn eine Master-Instanz ausfällt, erfolgt automatisch ein Failover und die Redis-Slave-Instanz wird automatisch zur Master-Instanz und stellt weiterhin Lese- und Schreibdienste bereit. Welche Daten schreibst du in den Speicher? Wie groß ist jedes Datenelement? Produktdaten, jedes Datenelement ist 10 KB groß. 100 Daten sind 1 MB und 100.000 Daten sind 1 g. Im Speicher befinden sich 2 Millionen Produktdaten, und der belegte Speicher beträgt 20 g, was nur weniger als 50 % des gesamten Speichers ausmacht. Die aktuelle Spitzenzeit liegt bei etwa 3.500 Anfragen pro Sekunde. Tatsächlich verfügen große Unternehmen über ein Infrastrukturteam, das für den Betrieb und die Wartung des Cache-Clusters verantwortlich ist. 35. Sprechen Sie über das Konzept des Redis-Hash-Slots? Der Redis-Cluster verwendet kein konsistentes Hashing, sondern führt das Konzept der Hash-Slots ein. Jeder Schlüssel besteht die CRC16-Prüfung und Modulo 16384, um zu bestimmen, für welchen Slot der Cluster verantwortlich ist Teil der Hash-Slots. 36. Gehen Schreibvorgänge im Redis-Cluster verloren? Warum? Redis garantiert keine starke Datenkonsistenz, was bedeutet, dass der Cluster in der Praxis unter bestimmten Bedingungen Schreibvorgänge verlieren kann. 37. Wie werden Redis-Cluster repliziert? Asynchrone Replikation 38. Was ist die maximale Anzahl von Knoten in einem Redis-Cluster? 16384 39. Wie wähle ich eine Datenbank für den Redis-Cluster aus? Der Redis-Cluster kann derzeit keine Datenbank auswählen und ist standardmäßig auf Datenbank 0 eingestellt. 9. Partition 40. Wie kann die Auslastung der Multi-Core-CPU verbessert werden? Sie können mehrere Instanzen von Redis auf demselben Server bereitstellen und diese als unterschiedliche Server verwenden. Irgendwann reicht ein Server ohnehin nicht aus. Wenn Sie also mehrere CPUs verwenden möchten, können Sie Sharding in Betracht ziehen. 41. Warum müssen wir Redis partitionieren? Partitionierung ermöglicht es Redis, größeren Speicher zu verwalten, und Redis kann den Speicher aller Maschinen nutzen. Ohne Partitionen können Sie nur den Arbeitsspeicher einer Maschine nutzen. Durch die Partitionierung kann die Rechenleistung von Redis durch einfaches Hinzufügen von Computern verdoppelt werden, und auch die Netzwerkbandbreite von Redis wird durch das Hinzufügen von Computern und Netzwerkkarten exponentiell ansteigen. 42. Wissen Sie, welche Redis-Partitionsimplementierungslösungen verfügbar sind? Clientseitige Partitionierung bedeutet, dass der Client bereits entschieden hat, in welchem Redis-Knoten die Daten gespeichert oder von diesem gelesen werden. Die meisten Clients implementieren bereits eine clientseitige Partitionierung. Proxy-Partitionierung bedeutet, dass der Client die Anfrage an den Proxy sendet und der Proxy dann entscheidet, auf welchen Knoten Daten geschrieben oder gelesen werden sollen. Der Agent entscheidet anhand der Partitionsregeln, welche Redis-Instanzen angefordert werden sollen, und gibt sie dann basierend auf den Redis-Antwortergebnissen an den Client zurück. Eine Proxy-Implementierung von Redis und Memcached ist Twemproxy Query Routing, was bedeutet, dass der Client zufällig eine beliebige Redis-Instanz anfordert und Redis die Anfrage dann an den richtigen Redis-Knoten weiterleitet. Redis Cluster implementiert eine Hybridform des Abfrageroutings, aber anstatt Anfragen direkt von einem Redis-Knoten an einen anderen weiterzuleiten, leitet es mit Hilfe des Clients direkt an den richtigen Redis-Knoten weiter. 43. Was sind die Nachteile der Redis-Partition? Vorgänge mit mehreren Schlüsseln werden normalerweise nicht unterstützt. Beispielsweise können Sie zwei Sammlungen nicht überschneiden, da sie möglicherweise in verschiedenen Redis-Instanzen gespeichert sind (eigentlich gibt es für diese Situation eine Möglichkeit, aber der Schnittbefehl kann nicht direkt verwendet werden). Wenn Sie mehrere Schlüssel gleichzeitig betreiben, können Sie keine Redis-Transaktionen verwenden. Die Partitionierungsgranularität ist der Schlüssel, sodass es nicht möglich ist, einen Datensatz mit einem einzigen großen Schlüssel wie einem sehr großen sortierten Satz zu teilen.) Bei Verwendung Partitionierung wird die Datenverarbeitung sehr kompliziert sein, zum Beispiel müssen Sie für Backups gleichzeitig RDB/AOF-Dateien von verschiedenen Redis-Instanzen und Hosts sammeln. Dynamische Expansion oder Kontraktion beim Partitionieren kann sehr kompliziert sein. Der Redis-Cluster fügt zur Laufzeit Redis-Knoten hinzu oder löscht sie, wodurch eine für Benutzer weitgehend transparente Datenverteilung erreicht werden kann. Einige andere Client-Partitionierungs- oder Proxy-Partitionierungsmethoden unterstützen diese Funktion jedoch nicht. Allerdings gibt es eine Pre-Sharding-Technologie, die dieses Problem ebenfalls besser lösen kann. 10. Verteilte Probleme Wenn und nur wenn der Schlüssel nicht vorhanden ist, setzen Sie den Wert des Schlüssels auf „Wert“. Wenn der angegebene Schlüssel bereits vorhanden ist, führt SETNX keine Aktion aus. SETNX ist die Abkürzung für „SET if Not eXists“ (wenn es nicht existiert, dann SET). Rückgabewert: Erfolgreich gesetzt, Rückgabe 1. Das Setup schlägt fehl und gibt 0 zurück. Der Prozess und die Angelegenheiten bei der Verwendung von SETNX zum Abschließen der Synchronisationssperre sind wie folgt: Verwenden Sie den SETNX-Befehl, um die Sperre zu erhalten (Schlüssel bereits vorhanden, Sperre bereits vorhanden), die Erfassung schlägt fehl, andernfalls ist die Erfassung erfolgreich. Um Ausnahmen im Programm nach dem Erwerb der Sperre zu verhindern, die dazu führen, dass andere Threads/Prozesse beim Aufruf des SETNX-Befehls immer 0 zurückgeben und in einen Deadlock-Zustand gelangen, muss eine „angemessene“ Ablaufzeit für den Schlüssel festgelegt werden. Entfernen Sie die Sperre und löschen Sie die Sperrdaten mit dem Befehl DEL. 45. So lösen Sie das Problem der gleichzeitigen Konkurrenz um Schlüssel in Redis Das sogenannte Problem der gleichzeitigen Konkurrenz um Schlüssel in Redis besteht darin, dass mehrere Systeme gleichzeitig auf einem Schlüssel arbeiten, aber die endgültige Ausführungsreihenfolge unterscheidet sich von der erwarteten Reihenfolge. Dies führt auch zu anderen Ergebnissen! Empfehlen Sie eine Lösung: verteilte Sperre (sowohl Zookeeper als auch Redis können verteilte Sperren implementieren). (Wenn es in Redis keine gleichzeitige Konkurrenz für Key gibt, verwenden Sie keine verteilten Sperren, da dies die Leistung beeinträchtigt.) Verteilte Sperren basierend auf den vorübergehend geordneten Knoten des Zookeepers. Die allgemeine Idee ist: Wenn jeder Client eine bestimmte Methode sperrt, wird im Verzeichnis des angegebenen Knotens, der der Methode auf zookeeper entspricht, ein eindeutiger, sofort geordneter Knoten generiert. Der Weg, um zu bestimmen, ob eine Sperre erworben werden soll, ist sehr einfach. Sie müssen nur die kleinste Sequenznummer unter den geordneten Knoten bestimmen. Wenn die Sperre aufgehoben wird, löschen Sie einfach den Übergangsknoten. Gleichzeitig können Deadlock-Probleme vermieden werden, die durch Sperren verursacht werden, die aufgrund von Dienstausfallzeiten nicht freigegeben werden können. Löschen Sie nach Abschluss des Geschäftsprozesses den entsprechenden untergeordneten Knoten, um die Sperre aufzuheben. In der Praxis steht natürlich die Zuverlässigkeit im Vordergrund. Daher wird zunächst Zookeeper empfohlen. 46. Sollte verteiltes Redis in der frühen Phase oder in der späteren Phase durchgeführt werden, wenn der Umfang erhöht wird? Warum? Da Redis so leichtgewichtig ist (eine einzelne Instanz benötigt nur 1 MB Speicher), besteht der beste Weg, zukünftige Erweiterungen zu verhindern, darin, am Anfang weitere Instanzen zu starten. Selbst wenn Sie nur einen Server haben, können Sie Redis von Anfang an verteilt ausführen und dabei Partitionen verwenden, um mehrere Instanzen auf demselben Server zu starten. Richten Sie zu Beginn ein paar weitere Redis-Instanzen ein, beispielsweise 32 oder 64 Instanzen. Dies mag für die meisten Benutzer umständlich sein, aber auf lange Sicht lohnt es sich. In diesem Fall, wenn Ihre Daten weiter wachsen und Sie mehr Redis-Server benötigen, müssen Sie lediglich die Redis-Instanz von einem Dienst auf einen anderen Server migrieren (ohne das Problem der Neupartitionierung zu berücksichtigen). Sobald Sie einen weiteren Server hinzufügen, müssen Sie die Hälfte Ihrer Redis-Instanzen von der ersten Maschine auf die zweite Maschine migrieren. 47. Was ist RedLock? Die offizielle Redis-Website hat eine autoritative Methode zur Implementierung verteilter Sperren basierend auf Redlock vorgeschlagen. Diese Methode ist sicherer als die ursprüngliche Einzelknotenmethode. Es kann die folgenden Funktionen garantieren: Sicherheitsfunktionen: Deadlock vermeiden Fehlertoleranz 48 Cache-Lawine Lösung: Wenn die Parallelität nicht besonders groß ist, ist die am häufigsten verwendete Lösung das Sperren und Einreihen. 49. Cache-Penetration Lösung: 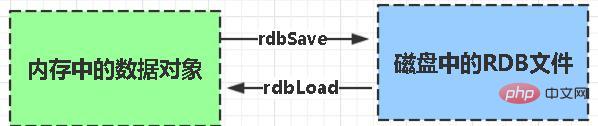
 : Wenn der Master-Knoten hängt, wird er automatisch auf den Slave-Knoten übertragen.
: Wenn der Master-Knoten hängt, wird er automatisch auf den Slave-Knoten übertragen. 
Zusätzlich:
Die ultimative Raumnutzung ist Bitmap und Bloom Filter.
Bitmap: Normalerweise handelt es sich um eine Hash-Tabelle. Der Nachteil besteht darin, dass Bitmap nur 1 Bit an Informationen für jedes Element aufzeichnen kann. Wenn Sie zusätzliche Funktionen ausführen möchten, können Sie dies leider nur tun, indem Sie mehr Platz opfern und Zeit.
Bloom-Filter (empfohlen)führt k(k>1)k(k>1) unabhängige Hash-Funktionen ein, um sicherzustellen, dass die Elemente innerhalb eines bestimmten Raums und einer bestimmten Fehleinschätzungsrate abgeschlossen sind. Der Prozess der Beurteilung.
Sein Vorteil besteht darin, dass die Speicherplatzeffizienz und die Abfragezeit weitaus höher sind als bei herkömmlichen Algorithmen. Der Nachteil besteht darin, dass es eine gewisse Fehlerkennungsrate und Schwierigkeiten beim Löschen gibt.
Die Kernidee des Bloom-Filter-Algorithmus besteht darin, mehrere verschiedene Hash-Funktionen zu verwenden, um „Konflikte“ zu lösen.
Hash hat ein Konfliktproblem (Kollisionsproblem), und die Werte zweier URLs, die unter Verwendung desselben Hashs erhalten werden, können gleich sein. Um Konflikte zu reduzieren, können wir mehrere weitere Hash-Werte einführen. Wenn wir aus einem der Hash-Werte schließen, dass ein Element nicht in der Menge ist, dann ist das Element definitiv nicht in der Menge. Nur wenn alle Hash-Funktionen uns mitteilen, dass das Element in der Menge vorhanden ist, können wir sicher sein, dass das Element in der Menge vorhanden ist. Dies ist die Grundidee von Bloom-Filter.
Bloom-Filter wird im Allgemeinen verwendet, um festzustellen, ob ein Element in einem großen Datensatz vorhanden ist.
50. Cache-AufschlüsselungCache-Aufschlüsselung
bezieht sich auf die Daten, die sich nicht im Cache, sondern in der Datenbank befinden (normalerweise ist die Cache-Zeit aufgrund der großen Anzahl gleichzeitiger Benutzer abgelaufen). Der gleichzeitige Lesecache liest keine Daten und ruft gleichzeitig die Daten in der Datenbank ab, wodurch der Druck auf die Datenbank sofort zunimmt und übermäßiger Druck entsteht. Im Gegensatz zur Cache-Lawine bezieht sich die Cache-Aufschlüsselung auf die gleichzeitige Abfrage derselben Daten. Cache-Lawine bedeutet, dass unterschiedliche Daten abgelaufen sind und viele Daten nicht gefunden werden können, sodass die Datenbank durchsucht wird.
LösungHotspot-Daten so einstellen, dass sie niemals ablaufen.
Mutex-Sperre, Mutex-Sperre hinzufügen
51, Cache-VorwärmungDie Cache-Vorwärmung dient dazu, relevante Cache-Daten direkt in das Cache-System zu laden, nachdem das System online gegangen ist. Auf diese Weise können Sie das Problem vermeiden, zuerst die Datenbank abzufragen und dann die Daten zwischenzuspeichern, wenn der Benutzer sie anfordert! Benutzer fragen direkt zwischengespeicherte Daten ab, die vorgewärmt wurden!
Lösung:Schreiben Sie direkt eine Cache-Aktualisierungsseite und führen Sie dies manuell aus, wenn Sie online gehen.
Die Datenmenge ist nicht groß und kann beim Start des Projekts automatisch geladen werden.
52, Cache-Verschlechterung
Wenn der Datenverkehr stark ansteigt, der Dienst Probleme hat (z. B. langsame Reaktionszeit oder keine Antwort) oder nicht zum Kerngeschäft gehörende Dienste die Leistung des Kernprozesses beeinträchtigen, muss dennoch sichergestellt werden, dass der Der Dienst ist weiterhin verfügbar, auch wenn der Dienst beeinträchtigt ist. Das System kann basierend auf einigen Schlüsseldaten automatisch ein Downgrade durchführen oder Switches konfigurieren, um ein manuelles Downgrade durchzuführen. ,
Das ultimative Ziel des Cache-Downgradesbesteht darin, sicherzustellen, dass Kerndienste verfügbar sind, auch wenn sie verlustbehaftet sind. Und einige Dienste können nicht herabgestuft werden (z. B. Hinzufügen zum Warenkorb, Bezahlen).
Vor dem Herabstufen müssen Sie das System sortieren, um zu sehen, ob das System Soldaten verlieren und Kommandeure behalten kann. Dabei können Sie herausfinden, was bis zum Tod geschützt werden muss und was herabgestuft werden kann Einstellungsplan: Allgemein: Einige Dienste können aufgrund von Netzwerk-Jitter oder Online-Zeitüberschreitung gelegentlich automatisch herabgestuft werden;
Warnung: Einige Dienste weisen innerhalb eines bestimmten Zeitraums schwankende Erfolgsraten auf (z zwischen 95 und 100 % und kann automatisch oder manuell herabgestuft werden. Senden Sie einen Alarm Die Anzahl der Besuche steigt plötzlich auf den maximalen Schwellenwert, den das System ertragen kann.
Schwerwiegender Fehler: Zum Beispiel, wenn die Daten aufgrund von Besonderheiten falsch sind Aus diesen Gründen ist ein manuelles Notfall-Downgrade erforderlich.
Der Zweck des Dienst-Downgrades besteht darin, zu verhindern, dass ein Ausfall des Redis-Dienstes Lawinenprobleme in der Datenbank verursacht. Daher kann für unwichtige zwischengespeicherte Daten eine Service-Downgrade-Strategie angewendet werden. Ein gängiger Ansatz besteht beispielsweise darin, dass bei einem Problem mit Redis die Datenbank nicht abgefragt wird, sondern direkt der Standardwert an den Benutzer zurückgegeben wird.
53. Heiße Daten und kalte DatenHeiße Daten, Cache sind wertvoll.
Bei kalten Daten wurden die meisten Daten möglicherweise vor dem erneuten Zugriff aus dem Speicher verdrängt, was nicht nur Speicher beansprucht, sondern auch wenig Wert hat. Bei häufig geänderten Daten sollten Sie je nach Situation die Verwendung eines Caches in Betracht ziehen.
Bei wichtigen Daten wie einem unserer IM-Produkte, einem Geburtstagsgrußmodul und einer Geburtstagsliste des Tages kann der Cache Hunderttausende Male gelesen werden. Ein weiteres Beispiel: In einem Navigationsprodukt speichern wir Navigationsinformationen zwischen und lesen sie möglicherweise in Zukunft millionenfach. Cache macht nur dann Sinn, wenn die Daten vor der Aktualisierung mindestens zweimal gelesen werden. Dies ist die grundlegendste Strategie, wenn der Cache ausfällt, bevor er wirksam wird.
Was ist mit dem Szenario, in dem der Cache nicht vorhanden ist und die Änderungshäufigkeit sehr hoch ist, aber Caching in Betracht gezogen werden muss? haben! Diese Leseschnittstelle übt beispielsweise großen Druck auf die Datenbank aus, es handelt sich jedoch auch um heiße Daten. Zu diesem Zeitpunkt müssen Caching-Methoden in Betracht gezogen werden, um den Druck auf die Datenbank zu verringern, z. B. die Anzahl der Likes, Sammlungen usw Anteile eines unserer Assistentenprodukte sind sehr typische Hot-Daten, die sich jedoch ständig ändern. Zu diesem Zeitpunkt müssen die Daten synchron im Redis-Cache gespeichert werden, um den Druck auf die Datenbank zu verringern.
54. Cache-Hotspot-Schlüssel
Ein Schlüssel im Cache (z. B. ein Werbeprodukt) läuft zu einem bestimmten Zeitpunkt ab und es gibt zu diesem Zeitpunkt eine große Anzahl gleichzeitiger Anfragen für diesen Schlüssel Gefundene Anforderungen Wenn der Cache abläuft, werden die Daten normalerweise aus der Back-End-Datenbank geladen und in den Cache zurückgesetzt. Zu diesem Zeitpunkt können große gleichzeitige Anforderungen die Back-End-Datenbank sofort überlasten.
Lösung:
Sperren Sie die Cache-Abfrage, sperren Sie sie, überprüfen Sie die Datenbank im Cache und entsperren Sie sie. Wenn andere Prozesse eine Sperre finden, warten Sie und geben Sie die Daten zurück oder geben Sie nach dem Entsperren der DB-Abfrage ein
Gemeinsame Tools
55 Welche Java-Clients werden von Redis unterstützt? Welches wird offiziell empfohlen?
Redisson, Jedis, Salat usw., die offizielle Empfehlung lautet Redisson.
56. Welche Beziehung besteht zwischen Redis und Redisson?
Redisson ist ein erweiterter Redis-Client für die verteilte Koordination, der Benutzern dabei helfen kann, einige Java-Objekte (Bloom-Filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap), Queue, BlockingQueue einfach in einer verteilten Umgebung zu implementieren , Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish/Subscribe, HyperLogLog).
57. Was sind die Vor- und Nachteile von Jedis und Redisson?
Jedis ist ein in Java implementierter Client. Seine API bietet eine relativ umfassende Unterstützung für Redis-Befehle. Im Vergleich zu Jedis sind seine Funktionen einfacher und unterstützen keine Zeichenkettenoperationen Unterstützt keine Redis-Funktionen wie Sortierung, Transaktionen, Pipelines und Partitionen. Der Zweck von Redisson besteht darin, die Trennung der Benutzeranliegen von Redis zu fördern, damit sich Benutzer mehr auf die Verarbeitung der Geschäftslogik konzentrieren können.
58 Der Unterschied zwischen Redis und Memcached. Beide sind nicht relationaler Speicher Schlüsselwertdatenbank, jetzt verwenden Unternehmen im Allgemeinen Redis, um Caching zu implementieren, und Redis selbst wird immer leistungsfähiger! Die Hauptunterschiede zwischen Redis und Memcached sind folgende:
(1) Alle Werte in Memcached sind einfache Zeichenfolgen, und Redis unterstützt als Ersatz umfangreichere Datentypen
(2) Redis ist schneller als Memcached Viel schneller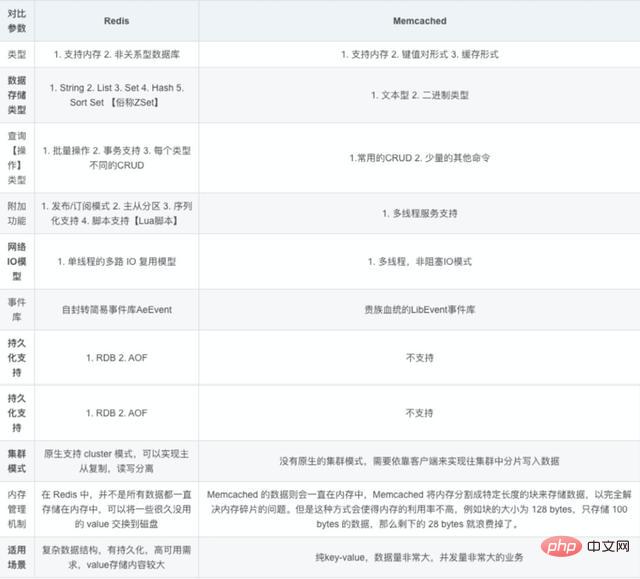
59 Wie kann die Datenkonsistenz sichergestellt werden, wenn der Cache und die Datenbank doppelt geschrieben werden?
Solange Sie den Cache verwenden, kann es zu doppelter Speicherung und doppeltem Schreiben von Cache und Datenbank kommen. Solange Sie doppeltes Schreiben verwenden, wird es definitiv Probleme mit der Datenkonsistenz geben.Wenn Ihr System nicht unbedingt eine Konsistenz des Caches und der Datenbank erfordert, ist es am besten, diese Lösung nicht zu serialisieren In eine Speicherwarteschlange gestellt, um sicherzustellen, dass es nach der Serialisierung nicht zu Inkonsistenzen kommt, wird der Durchsatz des Systems erheblich reduziert und es werden um ein Vielfaches mehr Maschinen verwendet als unter normalen Umständen.
Es gibt eine andere Möglichkeit, vorübergehende Inkonsistenzen zu verursachen, aber die Wahrscheinlichkeit des Auftretens ist sehr gering: Zuerst wird die Datenbank aktualisiert und dann der Cache gelöscht. 60. Häufige Redis-Leistungsprobleme und Lösungen?Master führt am besten keine Persistenzarbeiten durch, einschließlich Speicher-Snapshots und AOF-Protokolldateien, und aktiviert insbesondere keine Speicher-Snapshots für die Persistenz. 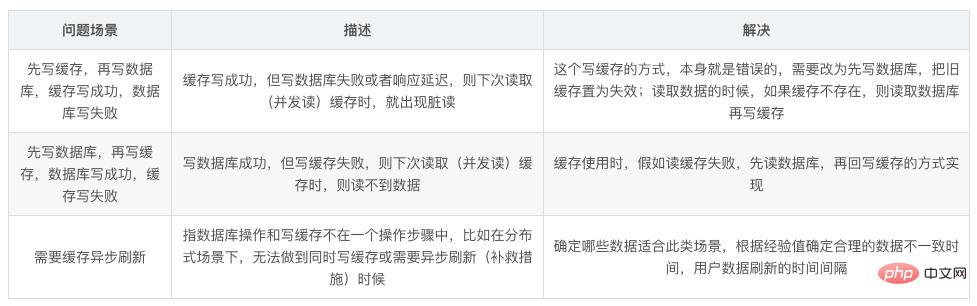
Für die Geschwindigkeit der Master-Slave-Replikation und die Stabilität der Verbindung ist es am besten, wenn sich Slave und Master im selben LAN befinden.
Vermeiden Sie das Hinzufügen von Slave-Bibliotheken zur überlasteten Hauptbibliothek. Der Master ruft BGREWRITEAOF auf, um die AOF-Datei neu zu schreiben. Dies führt zu einer übermäßigen Dienstlast und einer kurzen Dienstunterbrechung. Für die Stabilität des Masters sollte die Master-Slave-Replikation keine Diagrammstruktur verwenden. Es ist stabiler, eine einseitig verknüpfte Listenstruktur zu verwenden, das heißt, die Master-Slave-Beziehung ist: Master61. Warum stellt Redis offiziell keine Windows-Version zur Verfügung?
Da die aktuelle Linux-Version recht stabil ist und eine große Anzahl von Benutzern hat, besteht keine Notwendigkeit, eine Windows-Version zu entwickeln, was zu Kompatibilitäts- und anderen Problemen führen würde.62. Was ist die maximale Kapazität, die ein String-Typ-Wert speichern kann?
512M
63. Wie fügt Redis große Datenmengen ein?
Ab Redis 2.6 unterstützt redis-cli einen neuen Modus namens Pipe-Modus für die Durchführung großer Datenmengen.
64. Wenn es 100 Millionen Schlüssel in Redis gibt und 100.000 davon mit einem festen, bekannten Präfix beginnen, was wäre, wenn Sie sie alle finden würden?
Verwenden Sie den Befehl „keys“, um die Schlüsselliste des angegebenen Musters zu scannen.
Die andere Partei fragte dann: Wenn dieser Redis Dienste für Online-Unternehmen bereitstellt, welche Probleme gibt es dann bei der Verwendung des Tastenbefehls?
Zu diesem Zeitpunkt müssen Sie eine Schlüsselfunktion von Redis beantworten: das Single-Threading von Redis. Die Schlüsselanweisung führt dazu, dass der Thread für einen bestimmten Zeitraum blockiert wird und der Onlinedienst angehalten wird. Der Dienst kann erst wiederhergestellt werden, wenn die Anweisung ausgeführt wird. Zu diesem Zeitpunkt können Sie den Scan-Befehl verwenden, um die Schlüsselliste des angegebenen Modus zu extrahieren, es besteht jedoch eine gewisse Wahrscheinlichkeit einer Duplizierung. Führen Sie dies jedoch nur einmal auf dem Client aus, dies wird jedoch insgesamt der Fall sein länger sein als die direkte Verwendung. Der Tastenbefehl ist lang.
65. Haben Sie Redis jemals zum Erstellen einer asynchronen Warteschlange verwendet?
Verwenden Sie den Listentyp, um Dateninformationen zu speichern. rpush erzeugt Nachrichten und lpop verbraucht Nachrichten. Wenn Sie keine Nachrichten haben, können Sie eine Zeit lang schlafen und dann prüfen, ob Informationen vorhanden sind Wenn Sie schlafen möchten, können Sie blpop verwenden. Wenn keine Informationen vorliegen, wird es blockiert, bis die Informationen eintreffen. Redis kann über das Pub/Sub-Topic-Abonnementmodell einen Produzenten und mehrere Konsumenten implementieren. Natürlich gibt es bestimmte Nachteile, wenn der Konsument offline geht.
66. Wie implementiert Redis die Verzögerungswarteschlange?
Verwenden Sie sortedset, verwenden Sie den Zeitstempel als Bewertung, den Nachrichteninhalt als Schlüssel, rufen Sie zadd auf, um Nachrichten zu erstellen, und der Verbraucher verwendet zrangbyscore, um Daten vor n Sekunden für die Abfrageverarbeitung abzurufen.
67. Wie funktioniert der Redis-Recyclingprozess?
Ein Client hat einen neuen Befehl ausgeführt und neue Daten hinzugefügt.
Redis überprüft die Speichernutzung, wenn sie größer als das Limit von maxmemory ist, wird sie gemäß der festgelegten Strategie recycelt.
Ein neuer Befehl wird ausgeführt usw.
Wir überschreiten also ständig die Grenze der Speichergrenze, indem wir ständig die Grenze erreichen und dann ständig unterhalb der Grenze wieder recyceln.
Wenn das Ergebnis eines Befehls dazu führt, dass viel Speicher beansprucht wird (z. B. das Speichern der Schnittmenge einer großen Menge in einem neuen Schlüssel), dauert es nicht lange, bis das Speicherlimit durch diese Speichernutzung überschritten wird .
68. Welcher Algorithmus wird für das Redis-Recycling verwendet?
LRU-Algorithmus.
Okay, Redis-Interviewfragen werden hier geteilt. Wenn es für Sie hilfreich ist, geben Sie ihm bitte ein „Gefällt mir“, um es zu ermutigen~
Das obige ist der detaillierte Inhalt vonDie neueste Version von 2023 68 Redis-Interviewfragen (Sammlung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!