
Heim >Backend-Entwicklung >PHP-Problem >Lösen Sie das Problem der gleichen PHP-Strings, aber unterschiedlicher Länge
Lösen Sie das Problem der gleichen PHP-Strings, aber unterschiedlicher Länge

- 藏色散人Original
- 2020-07-18 09:06:242994Durchsuche
Die Methode zur Lösung der ungleichen Länge von PHP-Strings: Überprüfen Sie zunächst die Codierungsmethode der beiden Strings mithilfe der Funktion „mb_detect_encoding()“ und entfernen Sie schließlich die nichtchinesischen Zeichen.

Frage:
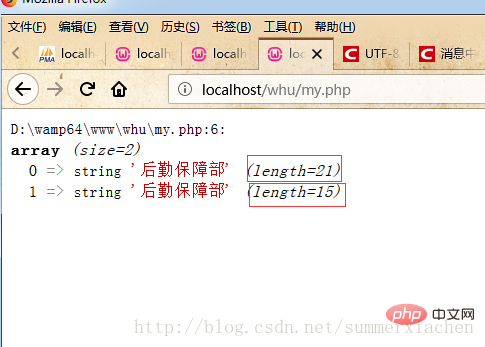
Wie im Bild gezeigt, gibt es zwei Auf einen Blick Die gleiche chinesische Zeichenfolge „Logistics Support Department“, aber eine hat eine Länge von 21 und die andere hat eine Länge von 15.
Zuallererst denken Sie vielleicht intuitiv, dass es durch unterschiedliche Codierungsmethoden verursacht wird.
Sehen Sie sich die Codierungsmethode von zwei Zeichenfolgen über die Funktion mb_detect_encoding() an. Der Code lautet wie folgt:
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));echo "str1='".$str1."'"." 编码:".$encode1."</br>";echo "str2='".$str2."'"." 编码:".$encode2."</br>";?>aber die Ausgabeergebnisse sind alle UTF -8
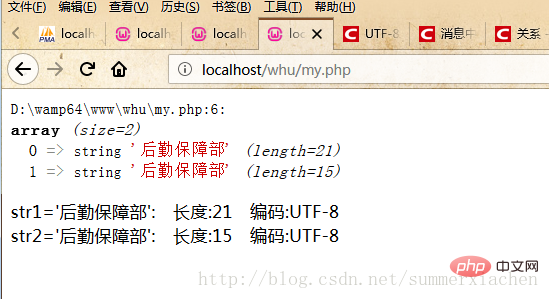
Was ist also der Grund?
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";?>Die Ausgabe Das Ergebnis lautet wie folgt:
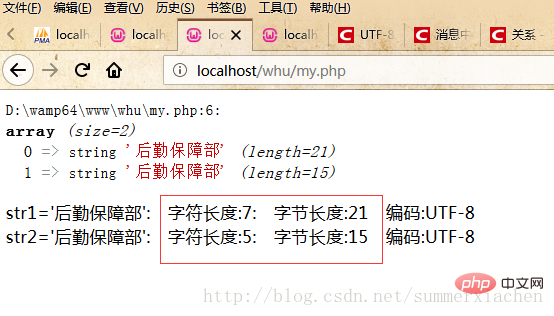
Es wurde festgestellt, dass die Zeichenfolge str1 7 chinesische Zeichen enthält, aber nur 5 tatsächlich angezeigt werden, nämlich die „Logistics Support Department“
Anzeige durch Abfangen der letzten beiden Zeichen von str1
//截取str1后面两个未显示字符$res=mb_substr($str1, 5,2);echo "最后两字符:".$res."</br>";echo mb_strlen($res);
Kann nicht per Echo angezeigt werden, belegt aber zwei Zeichen
Wenn die Zeichenfolgen, die gleich aussehen, tatsächlich gleich sein müssen , sie müssen verarbeitet werden, um nicht-chinesische Zeichen zu entfernen:
//剔除str1字串中未显示的字符(非中文字符)preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);Der endgültige Code lautet wie folgt
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";//截取str1后面两个未显示字符echo "</br>------------------截取str1后面两个未显示字符---------------------</br>";$res=mb_substr($str1, 5,2);echo "str1最后两字符: ".$res."</br>";echo "str1长度: ".mb_strlen($res)."</br>";//比较echo "</br>--------------------------相等比较----------------------------------</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";echo "str2 与 str2比较: ";echo strcomp($str2,$str2)."</br>";//剔除str1字串中非中文preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);echo "</br>---------------------剔除str1字串中非中文后----------------------</br>";echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";function strcomp($str1,$str2){
if($str1 == $str2){
return "相等";
}else{
return "不等";
}
}
?>Laufende Ergebnisse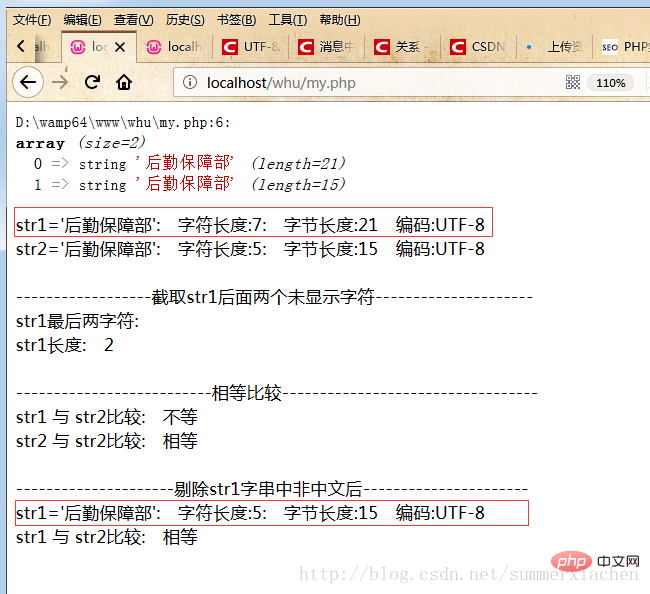
Hinweis:
Kopieren Sie den 21-Byte-str1 in das SQL-Eingabefeld von phpmyadmin. Die Anzeige lautet wie folgt
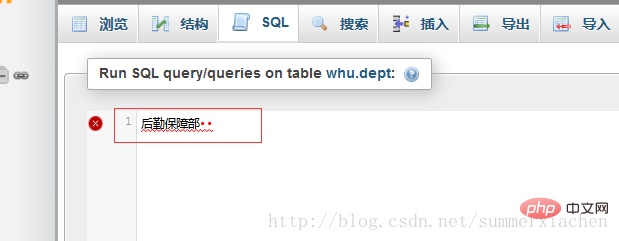
Nun , es sind nur die zwei zusätzlichen Zeichen
Weitere Informationen zu diesem Thema finden Sie auf der PHP-Chinese-Website!
Das obige ist der detaillierte Inhalt vonLösen Sie das Problem der gleichen PHP-Strings, aber unterschiedlicher Länge. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!