
Heim >Backend-Entwicklung >Python-Tutorial >Effiziente Datenverarbeitung in Python ist einen Blick wert
Effiziente Datenverarbeitung in Python ist einen Blick wert
- 烟雨青岚nach vorne
- 2020-06-16 17:31:592720Durchsuche

Sehenswerte effiziente Datenverarbeitung in Python
Pandas ist ein sehr häufig verwendetes Datenverarbeitungstool in Python und sehr benutzerfreundlich. Es basiert auf der NumPy-Array-Struktur, daher werden viele seiner Operationen über die mit NumPy oder Pandas gelieferten Erweiterungsmodule geschrieben. Diese Module werden in Cython geschrieben und in C kompiliert und auf C ausgeführt, wodurch die Verarbeitungsgeschwindigkeit sichergestellt wird.
Heute werden wir seine Kraft erleben.
1. Daten erstellen
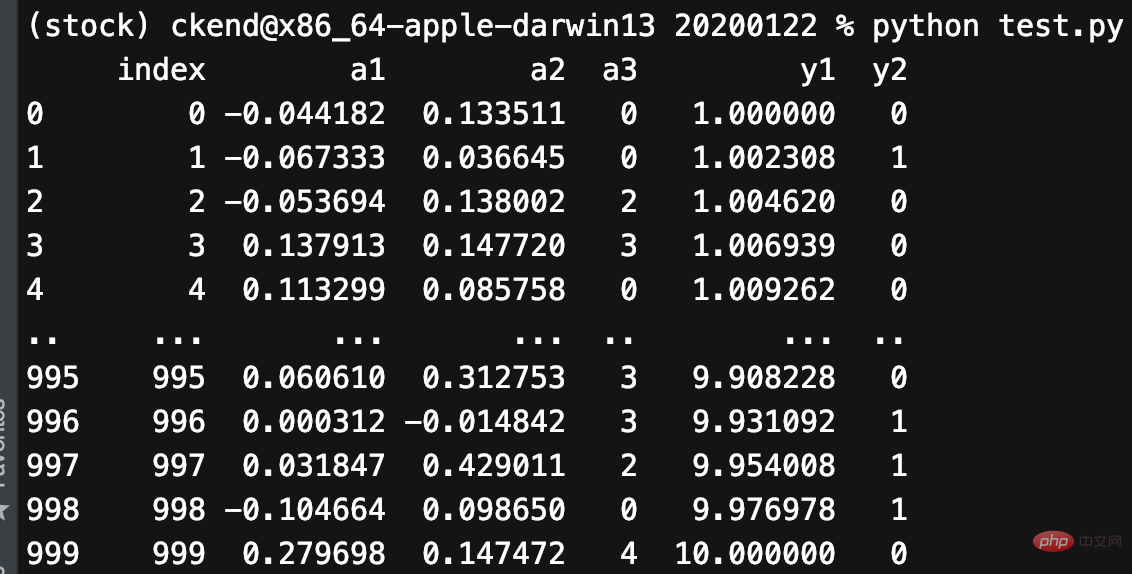
Mit Pandas können wir jetzt ganz einfach einen Pandas-DataFrame mit 5 Spalten und 1000 Zeilen erstellen:
mu1, sigma1 = 0, 0.1
mu2, sigma2 = 0.2, 0.2
n = 1000df = pd.DataFrame(
{
"a1": pd.np.random.normal(mu1, sigma1, n),
"a2": pd.np.random.normal(mu2, sigma2, n),
"a3": pd.np.random.randint(0, 5, n),
"y1": pd.np.logspace(0, 1, num=n),
"y2": pd.np.random.randint(0, 2, n),
}
)
- a1 und a2: Zufallsstichproben aus einer Normalverteilung (Gaußverteilung).
- a3: Zufällige Ganzzahl von 0 bis 4.
- y1: gleichmäßig verteilt auf einer logarithmischen Skala von 0 bis 1.
- y2: Zufällige Ganzzahl von 0 bis 1.
generiert Daten wie unten gezeigt:
2. Zeichnen Sie das Bild
Pandas-Plotfunktion Gibt eine Matplotlib-Koordinatenachse (Achsen) zurück, sodass wir darauf individuell zeichnen können, was wir brauchen. Zeichnen Sie beispielsweise eine vertikale Linie und eine parallele Linie. Das wird für uns von großem Nutzen sein:
1. Zeichnen Sie die Durchschnittslinie
2. Markieren Sie die wichtigsten Punkte
rrree
Wir können auch anpassen, wie viele Tabellen in einem Diagramm angezeigt werden:
import matplotlib.pyplot as plt ax = df.y1.plot() ax.axhline(6, color="red", linestyle="--") ax.axvline(775, color="red", linestyle="--") plt.show()

Zeichnen Sie ein Histogramm
Pandas ermöglicht uns den Formvergleich zweier Figuren auf sehr einfache Weise:
fig, ax = plt.subplots(2, 2, figsize=(14,7)) df.plot(x="index", y="y1", ax=ax[0, 0]) df.plot.scatter(x="index", y="y2", ax=ax[0, 1]) df.plot.scatter(x="index", y="a3", ax=ax[1, 0]) df.plot(x="index", y="a1", ax=ax[1, 1]) plt.show()

Es ermöglicht auch das Zeichnen mehrerer Figuren:
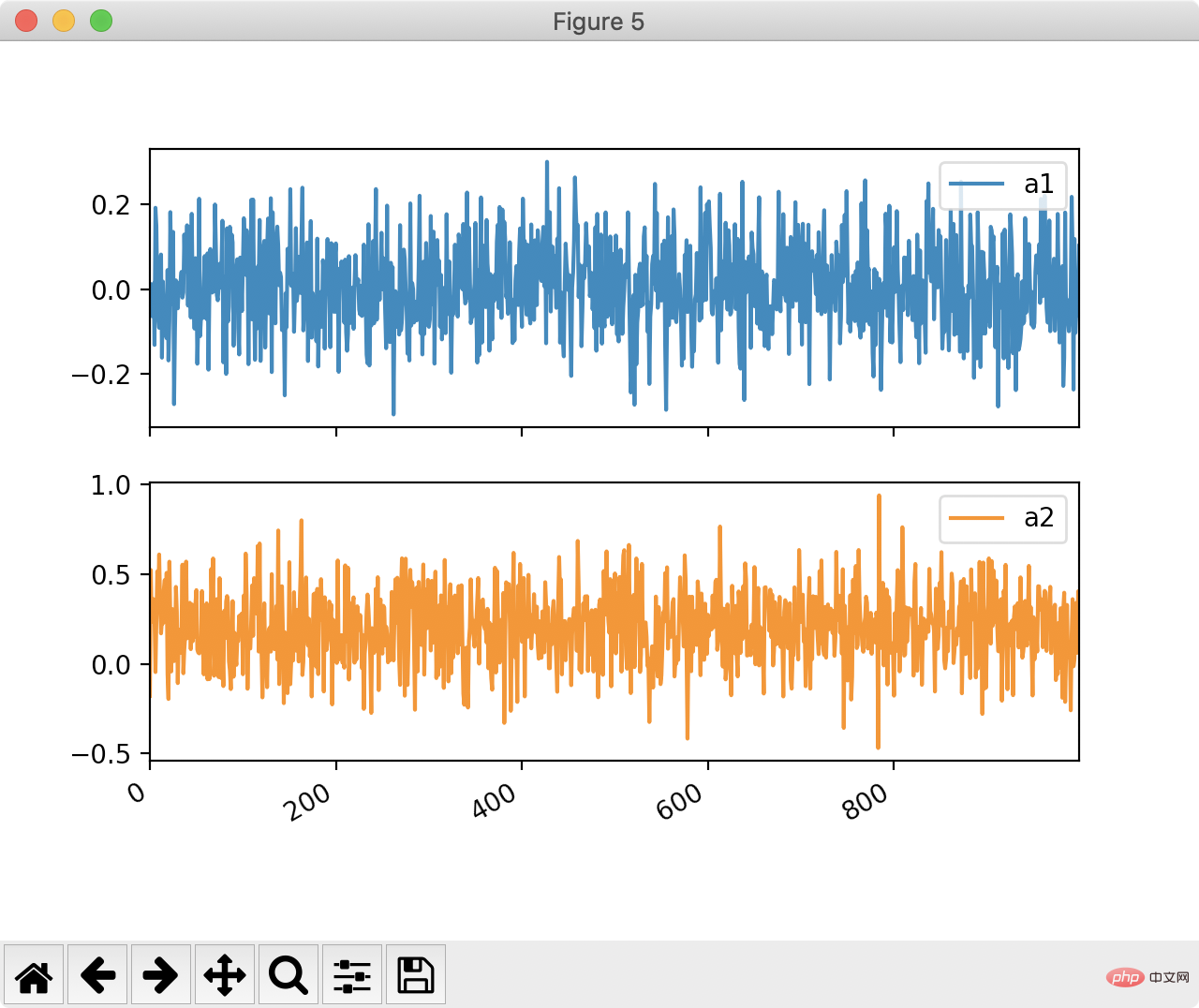
df[["a1", "a2"]].plot(bins=30, kind="hist") plt.show()

Das Erstellen eines Liniendiagramms ist natürlich nicht in der Zeichnung enthalten:
df[["a1", "a2"]].plot(bins=30, kind="hist", subplots=True) plt.show()
4. Lineare Anpassung
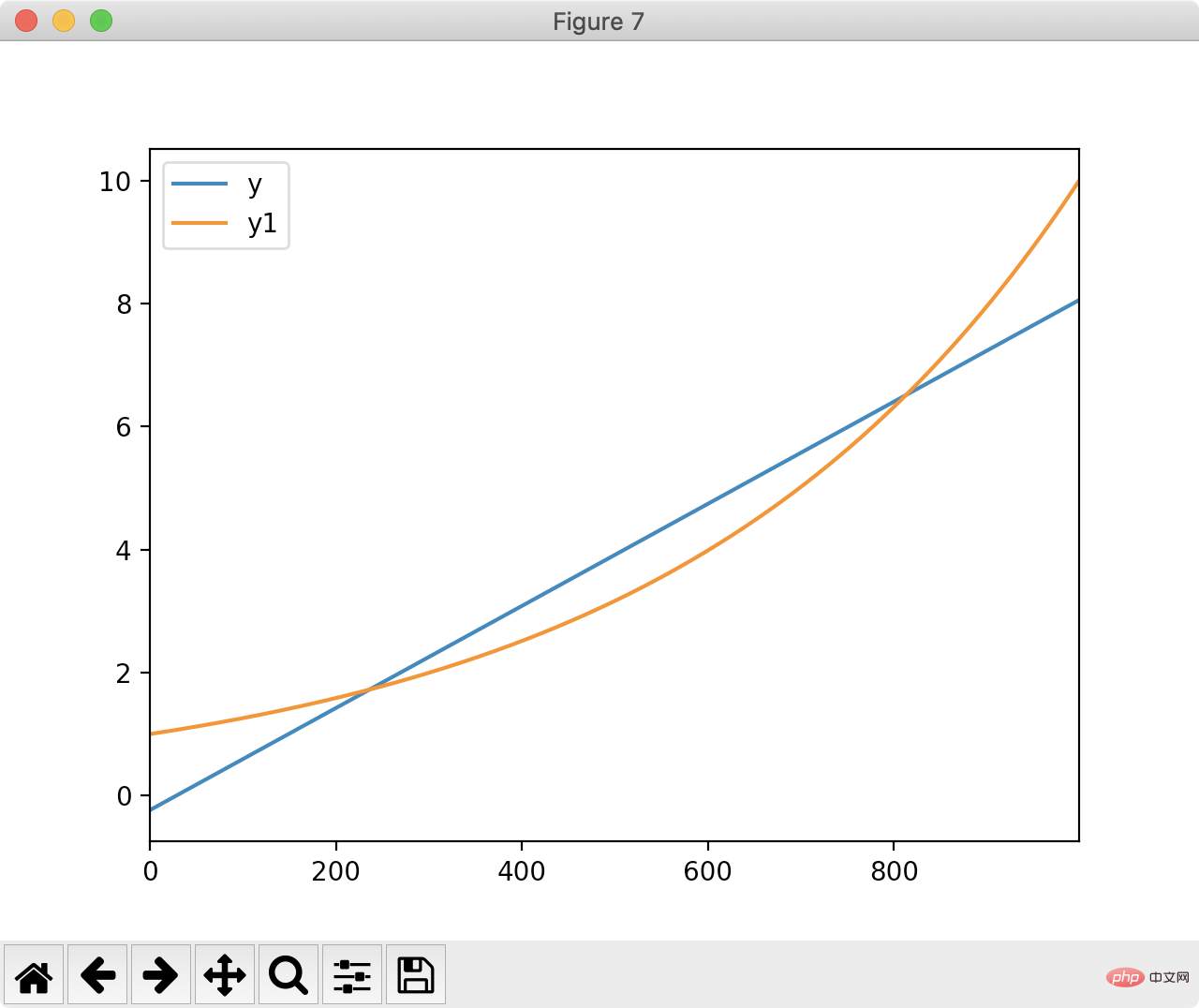
Pandas können auch zur Anpassung verwendet werden, um eine gerade Linie zu finden, die der folgenden Figur am nächsten kommt:

Die Die Methode der kleinsten Quadrate berechnet die kürzeste gerade Linie Entfernung:
df[['a1', 'a2']].plot(by=df.y2, subplots=True) plt.show()
Zeichnen Sie y und die angepasste gerade Linie basierend auf dem Ergebnis der kleinsten Quadrate:
df['ones'] = pd.np.ones(len(df)) m, c = pd.np.linalg.lstsq(df[['index', 'ones']], df['y1'], rcond=None)[0]
Vielen Dank für Beim Lesen hoffe ich, dass Sie viel davon profitieren werden.
Dieser Artikel ist reproduziert von: https://blog.csdn.net/u010751000/article/details/106735872
Empfohlenes Tutorial: „Python-Tutorial“
Das obige ist der detaillierte Inhalt vonEffiziente Datenverarbeitung in Python ist einen Blick wert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!