
Häufig verwendete Algorithmen: Hash-Algorithmus

- Guanhuinach vorne
- 2020-06-16 17:18:155572Durchsuche

Vorwort
Programmierer sollten mit Hashing-Algorithmen wie dem branchenbekannten MD5, SHA, CRC vertraut sein usw.; in der täglichen Entwicklung verwenden wir häufig eine Karte, um einige Daten mit einer (Schlüssel-, Wert-)Struktur zu laden, und nutzen die Zeitkomplexität des Hash-Algorithmus O(1), um die Effizienz der Programmverarbeitung zu verbessern Kennen Sie weitere Anwendungsszenarien von Hashing-Algorithmen?
1. Was ist ein Hash-Algorithmus?
Bevor wir die Anwendungsszenarien des Hash-Algorithmus verstehen, werfen wir zunächst einen Blick auf die Hash-(Hash-)Idee. Beim Hashing geht es darum, Eingaben beliebiger Länge in Ausgaben fester Länge umzuwandeln. Die Eingabe heißt Schlüssel, die Ausgabe ist ein Hash-Wert, also der Hash-Wert hash(key), und der Hash-Algorithmus ist die Funktion hash() (Hash und Hash sind unterschiedliche Übersetzungen von Hash ) ; Tatsächlich werden diese Hash-Werte in einem Array gespeichert, das als Hash-Tabelle bezeichnet wird, um den wahlfreien Zugriff auf Daten gemäß dem Index zu unterstützen eine Eins-zu-Eins-Zuordnung, wodurch eine O(1)-Zeitkomplexitätsabfrage erreicht wird; >Aktuelle Hash-Algorithmen wie MD5, SHA, CRC usw. können keine Hash-Funktion mit unterschiedlichen Hash-Werten erreichen, die unterschiedlichen Schlüsseln entsprechen. Das heißt, es ist unmöglich, die Situation zu vermeiden, in der unterschiedliche Schlüssel demselben Wert zugeordnet werden. Das heißt,
Hash-Konflikt, und da der Speicherplatz des Arrays begrenzt ist, erhöht sich auch die Wahrscheinlichkeit eines Hash-Konflikts. Wie kann eine Hash-Kollision behoben werden? Es gibt zwei Arten von Hash-Konfliktlösungsmethoden, die wir üblicherweise verwenden: offene Adressierung und Verkettung. 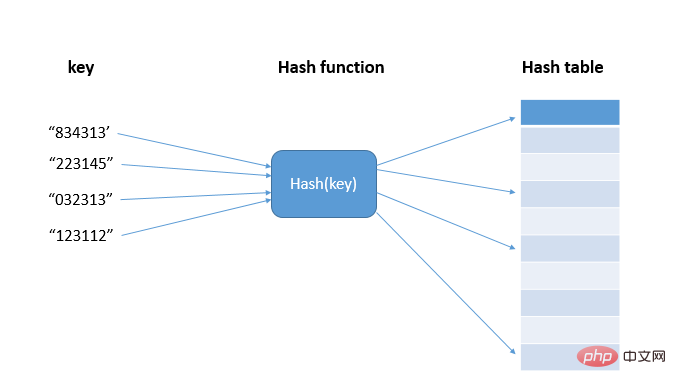
1.1.1 Offene Adressierungsmethode
Suchen Sie die freie Position in der Hash-Tabelle durch lineare Erkennung und schreiben Sie den Hash-Wert:
Wie in der Abbildung gezeigt, wird 834313 an die Position 303432 in der Hash-Tabelle gehasht, und es kommt zu einem Konflikt. Die Hash-Tabelle wird nacheinander durchlaufen, bis eine freie Position gefunden wird, und 834313 wird geschrieben Bei freien Positionen in der Hash-Tabelle wird die Wahrscheinlichkeit eines Hash-Konflikts erheblich erhöht. Unter normalen Umständen werden wir unser Bestes geben, um sicherzustellen, dass in der Hash-Tabelle ein bestimmter Anteil an freien Plätzen vorhanden ist 🎜> Ladefaktor Um die Anzahl der freien Slots darzustellen, lautet die Berechnungsformel: der Ladefaktor der Hash-Tabelle = die Anzahl der in der Tabelle gefüllten Elemente/die Länge der Hash-Tabelle. Je größer der Auslastungsfaktor, desto weniger freie Standorte und mehr Konflikte gibt es, und die Leistung der Hash-Tabelle nimmt ab.
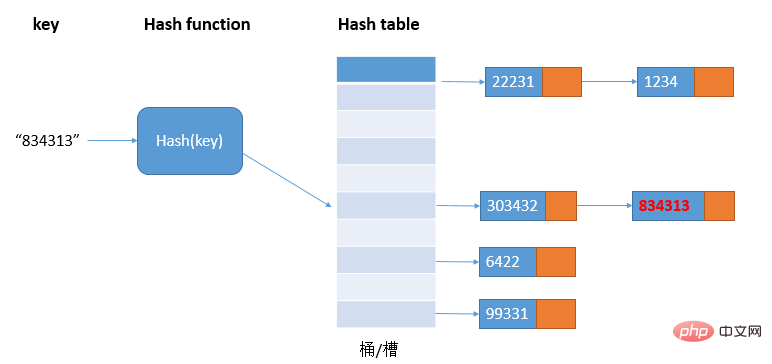
Wenn die Datenmenge relativ klein und der Auslastungsfaktor gering ist, ist die Verwendung der offenen Adressierungsmethode geeignet. Aus diesem Grund verwendet ThreadLocalMap in Java die offene Adressierungsmethode, um Hash-Konflikte zu lösen.1.1.2 Methode der verknüpften Liste 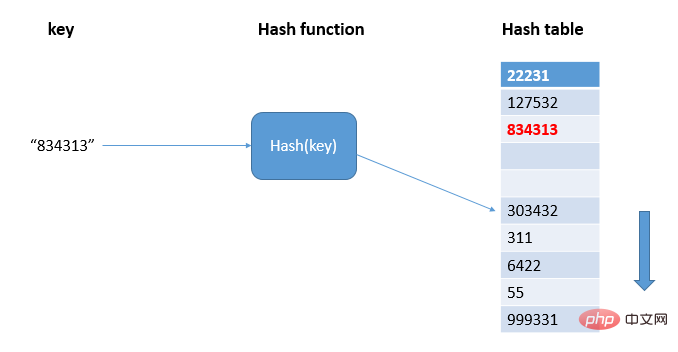
Die Methode der verknüpften Liste ist eine häufiger verwendete Methode zur Lösung von Hash-Konflikten und einfacher. Wie im Bild gezeigt:
In der Hash-Tabelle entspricht jeder Bucket/Slot einer verknüpften Liste. Alle Elemente mit demselben Hash-Wert werden in der entsprechenden verknüpften Liste platziert Wenn es viele Hash-Konflikte gibt, wird die Länge der verknüpften Liste ebenfalls länger, und das Abfragen des Hash-Werts erfordert das Durchlaufen der verknüpften Liste, wodurch sich die Abfrageeffizienz von O (1) auf O verringert (N).Diese Methode zur Lösung von Hash-Konflikten eignet sich besser für Hash-Tabellen mit großen Objekten und großen Datenmengen und unterstützt mehr Optimierungsstrategien, z. B. die Verwendung von Rot-Schwarz-Bäumen anstelle verknüpfter Listen Zur weiteren Optimierung wird der Rot-Schwarz-Baum eingeführt. Wenn die Länge der verknüpften Liste zu lang ist (Standard ist größer als 8), wird die verknüpfte Liste zu diesem Zeitpunkt in einen Rot-Schwarz-Baum umgewandelt -Schwarzer Baum kann zum schnellen Hinzufügen, Löschen, Überprüfen und Ändern verwendet werden, um die Leistung von HashMap zu verbessern. Wenn die Anzahl der rot-schwarzen Baumknoten weniger als 8 beträgt, wird der rot-schwarze Baum in eine verknüpfte Liste umgewandelt Wenn die Datenmenge relativ gering ist, muss der Rot-Schwarz-Baum das Gleichgewicht im Vergleich zur verknüpften Liste aufrechterhalten. Der Leistungsvorteil ist nicht offensichtlich.
2. Anwendungsszenarien von Hash-Algorithmen
Der am häufigsten für die Verschlüsselung verwendete Hash-Algorithmus ist MD5 (MD5 Message-Digest-Algorithmus) und SHA (Secure Hash-Algorithmus) verwenden die Eigenschaften von Hash, um den Hash-Wert zu berechnen, was es schwierig macht, die Originaldaten umgekehrt abzuleiten und so den Zweck der Verschlüsselung zu erreichen.
Am Beispiel von MD5 ist der Hash-Wert eine feste 128-Bit-Binärzeichenfolge, die bis zu 2^128 Daten darstellen kann, und die Wahrscheinlichkeit eines Hash-Konflikts ist geringer als 1/2^ 128. Wenn Sie mit der erschöpfenden Methode andere Daten finden möchten, die mit diesem MD5 identisch sind, sollte der Zeitaufwand astronomisch sein. Daher ist es immer noch schwierig, den Hash-Algorithmus innerhalb einer begrenzten Zeit zu knacken Verschlüsselungseffekt erreicht wird.
2.2 DatenüberprüfungMithilfe der Hash-Funktion, um sensibel auf
Datenzu reagieren, kann damit überprüft werden, ob die Daten während der Netzwerkübertragung vorhanden sind korrekt, um böswillige Änderungen zu verhindern.
2.3 Hash-Funktion
Unter Verwendung der relativen Gleichverteilung Eigenschaften der Hash-Funktion wird der Hash-Wert als Ortswert der Datenspeicherung verwendet, so dass Die Daten werden gleichmäßig im Container verteilt.
2.4 Lastausgleich
Verwenden Sie den Hash-Algorithmus, um den Hash-Wert der Client-ID-Adresse oder Sitzungs-ID zu berechnen, und vergleichen Sie den erhaltenen Hash-Wert mit der Größe der Serverliste Nach Durchführung der Modulo-Operation ist der Endwert die Servernummer, zu der weitergeleitet werden soll.
2.5 Data Sharding
Angenommen, wir haben eine 1T-Protokolldatei, die die Suchschlüsselwörter des Benutzers aufzeichnet. Wir möchten jedes Mal schnell zählen, wie oft a Stichwort wurde gesucht , was soll ich tun? Die Datenmenge ist relativ groß und es ist schwierig, sie im Speicher einer Maschine abzulegen. Selbst wenn sie auf einer Maschine abgelegt wird, ist die Verarbeitungszeit sehr lang. Um dieses Problem zu lösen, können wir die Daten zunächst fragmentieren Verwenden Sie dann mehrere Maschinen zur Verarbeitung, um die Verarbeitungsgeschwindigkeit zu erhöhen.
Die konkrete Idee ist: Um die Verarbeitungsgeschwindigkeit zu verbessern, verwenden wir n Maschinen für die Parallelverarbeitung. Aus der Protokolldatei des Suchdatensatzes wird nacheinander jedes Suchwort analysiert und der Hash-Wert über die Hash-Funktion berechnet. Der endgültige Wert ist die Maschinennummer, die auf diese Weise zugewiesen werden soll Hash-Wert Suchschlüsselwörter mit demselben Wert werden derselben Maschine zugewiesen. Jede Maschine zählt die Anzahl der Vorkommen des Schlüsselworts separat und kombiniert sie schließlich, um das Endergebnis zu erhalten. Tatsächlich ist der Verarbeitungsprozess hier auch die grundlegende Designidee von MapReduce.
2.6 Verteilter Speicher
Für Situationen, in denen große Datenmengen zwischengespeichert werden müssen, reicht ein Cache-Computer definitiv nicht aus, daher müssen wir die Daten auf mehrere auf einem verteilen Maschine. Zu diesem Zeitpunkt können wir die vorherige Sharding-Idee verwenden, dh den Hash-Algorithmus verwenden, um den Hash-Wert der Daten zu erhalten, und dann die Anzahl der Maschinen modulieren, um die Nummer der Cache-Maschine zu erhalten, die gespeichert werden soll.
Wenn jedoch die Daten zunehmen, können die ursprünglichen 10 Maschinen diese nicht mehr ertragen und müssen erweitert werden. Wenn zu diesem Zeitpunkt alle Daten-Hashwerte neu berechnet und dann auf die richtige Maschine verschoben werden, es wird ziemlich sein Da alle zwischengespeicherten Daten auf einmal ungültig werden, dringen sie in den Cache ein und kehren zur Quelle zurück, was zu einem Lawineneffekt führen und die Datenbank überfordern kann. Um eine neue Cache-Maschine hinzuzufügen, ohne alle Daten zu verschieben, ist der konsistente Hash-Algorithmus die bessere Wahl. Die Hauptidee ist: Angenommen, wir haben eine KGE-Maschine, der Hash-Wertbereich der Daten ist [. 0, Max] teilen wir den gesamten Bereich in m kleine Intervalle auf (m ist viel größer als k). Wenn eine neue Maschine beitritt, teilen wir die Daten bestimmter kleiner Intervalle auf Die ursprüngliche Maschine wird auf die neue Maschine verschoben. Auf diese Weise müssen nicht alle Daten erneut gehasht und verschoben werden, und das Gleichgewicht des Datenvolumens auf jeder Maschine bleibt erhalten.
3. Am Ende geschrieben
Tatsächlich gibt es viele andere Anwendungen von Hash-Algorithmen, wie z. B. Git-Commit-ID usw. Viele Anwendungen stammen aus dem Algorithmus Das Verständnis und die Erweiterung verkörpern auch den Wert grundlegender Datenstrukturen und Algorithmen, die wir in unserer Arbeit langsam verstehen und erfahren müssen.
Empfohlenes Tutorial: „Java-Tutorial“
Das obige ist der detaillierte Inhalt vonHäufig verwendete Algorithmen: Hash-Algorithmus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!