
Heim >Java >javaLernprogramm >Analyse von LinkedHashMap in einfachen Worten (Bilder und Text)
Analyse von LinkedHashMap in einfachen Worten (Bilder und Text)

- angryTomnach vorne
- 2019-11-28 13:44:492099Durchsuche

1. Zusammenfassung
Im ersten Kapitel der Sammlungsreihe haben wir gelernt, dass die Implementierungsklasse von Map ist HashMap, LinkedHashMap, TreeMap, IdentityHashMap, WeakHashMap, Hashtable, Properties usw.
In diesem Artikel wird hauptsächlich die Implementierung von LinkedHashMap auf Datenstruktur- und Algorithmusebene erläutert.
(Empfohlenes Lernen: Java-Video-Tutorial)
2. Einführung
LinkedHashMap kann als HashMap+LinkedList betrachtet werden. Es verwendet HashMap, um die Datenstruktur zu verwalten, und LinkedList, um die Reihenfolge der eingefügten Elemente beizubehalten. Es übernimmt intern die Form einer doppelt verknüpften Liste. Verbinde alle Elemente (Einträge).
LinkedHashMap erbt HashMap, sodass Elemente mit einem Nullschlüssel eingefügt werden können und Elemente mit einem Wert von Null eingefügt werden können. Wie aus dem Namen hervorgeht, handelt es sich bei diesem Container um eine Mischung aus LinkedList und HashMap, was bedeutet, dass er bestimmte Merkmale von HashMap und LinkedHashMap erfüllt und als eine mit Linked List erweiterte HashMap betrachtet werden kann.
Öffnen Sie den LinkedHashMap-Quellcode und Sie können die drei Hauptkernattribute sehen:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>{
/**双向链表的头节点*/
transient LinkedHashMap.Entry<K,V> head;
/**双向链表的尾节点*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 1、如果accessOrder为true的话,则会把访问过的元素放在链表后面,放置顺序是访问的顺序
* 2、如果accessOrder为false的话,则按插入顺序来遍历
*/
final boolean accessOrder;
}
LinkedHashMap In der Initialisierungsphase wird standardmäßig in der Einfügungsreihenfolge
public LinkedHashMap() {
super();
accessOrder = false;
}
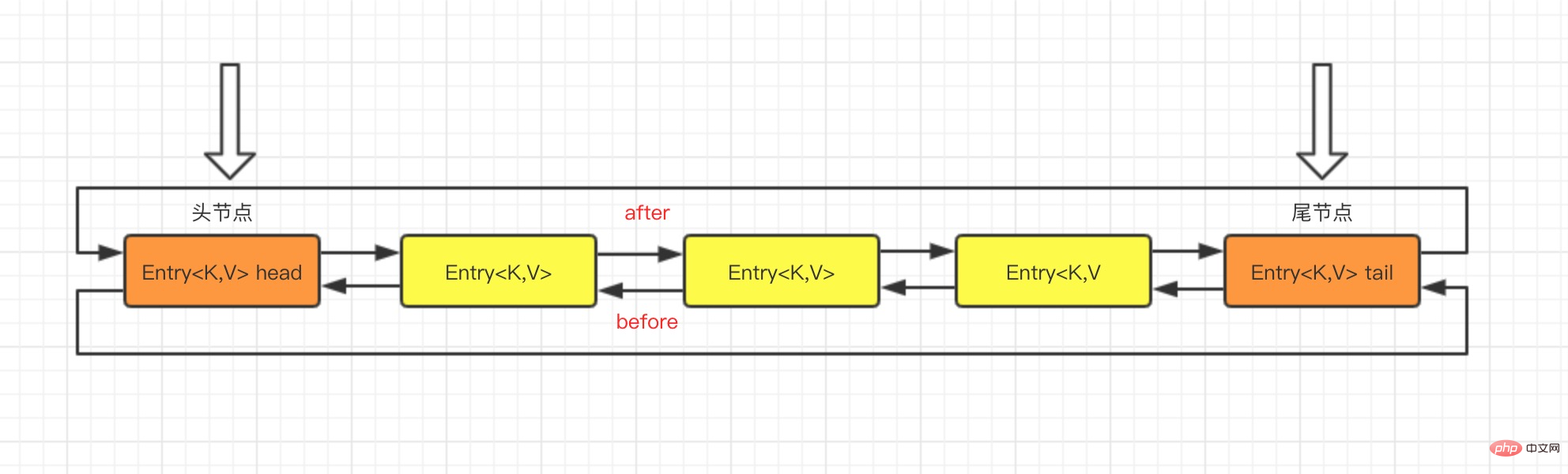
durchlaufen Der von LinkedHashMap und HashMap verwendete Hash-Algorithmus ist derselbe, der Unterschied besteht jedoch darin, dass er das im Array gespeicherte Element Entry neu definiert. Zusätzlich zum Speichern der Referenz des aktuellen Objekts speichert Entry auch die Referenz seines vorherigen Elements vor und Das nächste Element danach, also in der Hash-Tabelle, wird im Grunde eine zweifach verknüpfte Liste gebildet.
Der Quellcode lautet wie folgt:
static class Entry<K,V> extends HashMap.Node<K,V> {
//before指的是链表前驱节点,after指的是链表后驱节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
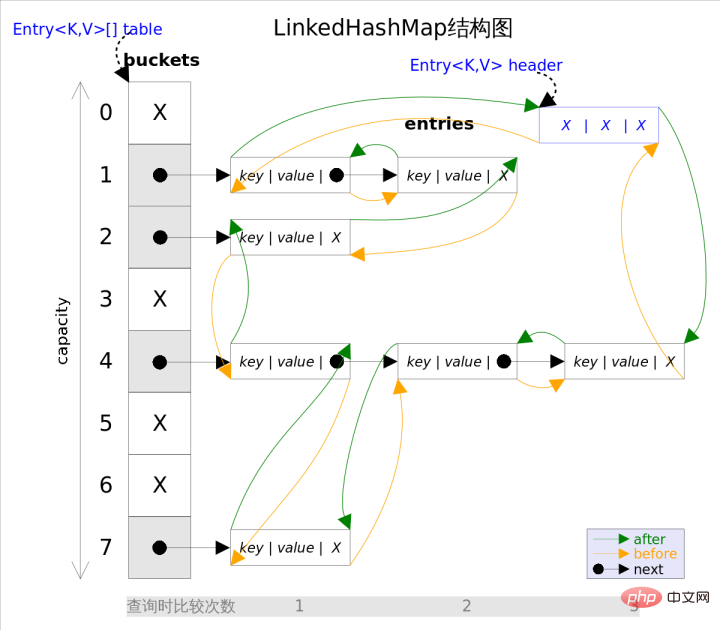
Es ist intuitiv zu erkennen, dass die am Kopf der doppelt verknüpften Liste eingefügten Daten der Eintrag von sind Die Durchlaufrichtung des Iterators beginnt am Kopf der verknüpften Liste und endet am Ende der verknüpften Liste.
Neben der Beibehaltung der Iterationsreihenfolge hat diese Struktur auch einen Vorteil: Beim Iterieren von LinkedHashMap müssen Sie nicht wie HashMap die gesamte Tabelle durchlaufen, sondern nur um den Header, auf den verwiesen wird, direkt zu durchlaufen Eine doppelt verknüpfte Liste ist ausreichend, was bedeutet, dass die Iterationszeit von LinkedHashMap nur von der Anzahl der Einträge abhängt und nichts mit der Größe der Tabelle zu tun hat.
3. Einführung in gängige Methoden
3.1 Get-Methode
Die Get-Methode gibt den entsprechenden Wert zurück angegebener Schlüsselwert. Der Prozess dieser Methode ist fast identisch mit dem der HashMap.get()-Methode. Standardmäßig wird sie in der Einfügereihenfolge durchlaufen.
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
Wenn accessOrder wahr ist, werden die besuchten Elemente am Ende der verknüpften Liste platziert und die Platzierungsreihenfolge ist die Reihenfolge des Zugriffs
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
Testfall:
public static void main(String[] args) {
//accessOrder默认为false
Map<String, String> accessOrderFalse = new LinkedHashMap<>();
accessOrderFalse.put("1","1");
accessOrderFalse.put("2","2");
accessOrderFalse.put("3","3");
accessOrderFalse.put("4","4");
System.out.println("acessOrderFalse:"+accessOrderFalse.toString());
//accessOrder设置为true
Map<String, String> accessOrderTrue = new LinkedHashMap<>(16, 0.75f, true);
accessOrderTrue.put("1","1");
accessOrderTrue.put("2","2");
accessOrderTrue.put("3","3");
accessOrderTrue.put("4","4");
accessOrderTrue.get("2");//获取键2
accessOrderTrue.get("3");//获取键3
System.out.println("accessOrderTrue:"+accessOrderTrue.toString());
}
Ausgabeergebnis:
acessOrderFalse:{1=1, 2=2, 3=3, 4=4}
accessOrderTrue:{1=1, 4=4, 2=2, 3=3}
3.2, Put-Methode
put(K-Schlüssel, V-Wert)-Methode besteht darin, das angegebene Schlüssel-Wert-Paar zur Karte hinzuzufügen. Diese Methode ruft zunächst die Einfügemethode von HashMap auf und durchsucht die Karte, um festzustellen, ob sie enthalten ist. Der Suchvorgang ähnelt der Methode get(), wenn sie nicht gefunden wird. Das Element wird in die Sammlung eingefügt.
/**HashMap 中实现*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Methode in LinkedHashMap überschrieben
// LinkedHashMap 中覆写
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将 Entry 接在双向链表的尾部
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last 为 null,表明链表还未建立
if (last == null)
head = p;
else {
// 将新节点 p 接在链表尾部
p.before = last;
last.after = p;
}
}
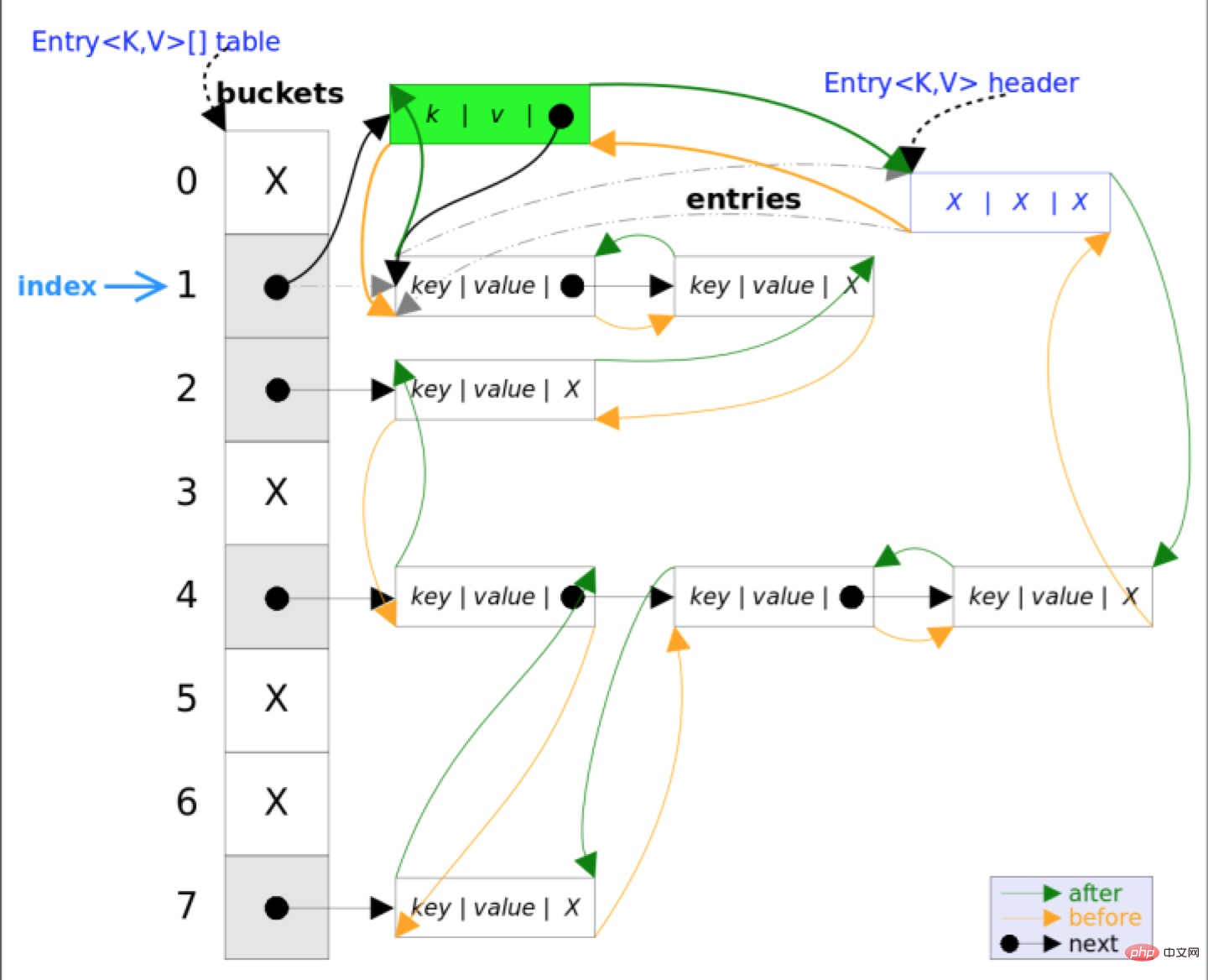
3.3, Methode entfernen
remove(Object key) Die Funktion besteht darin, den dem Schlüsselwert entsprechenden Eintrag zu löschen. Die Implementierungslogik dieser Methode basiert hauptsächlich auf HashMap. Suchen Sie zunächst den Eintrag, der dem Schlüsselwert entspricht, und löschen Sie dann den Eintrag (ändern Sie die entsprechende Referenz der verknüpften Liste). Der Suchvorgang ähnelt der get()-Methode. Schließlich wird die überschriebene Methode in LinkedHashMap aufgerufen und gelöscht!
/**HashMap 中实现*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) {...}
else {
// 遍历单链表,寻找要删除的节点,并赋值给 node 变量
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {...}
// 将要删除的节点从单链表中移除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node); // 调用删除回调方法进行后续操作
return node;
}
}
return null;
}
Die afterNodeRemoval-Methode wird in LinkedHashMap überschrieben
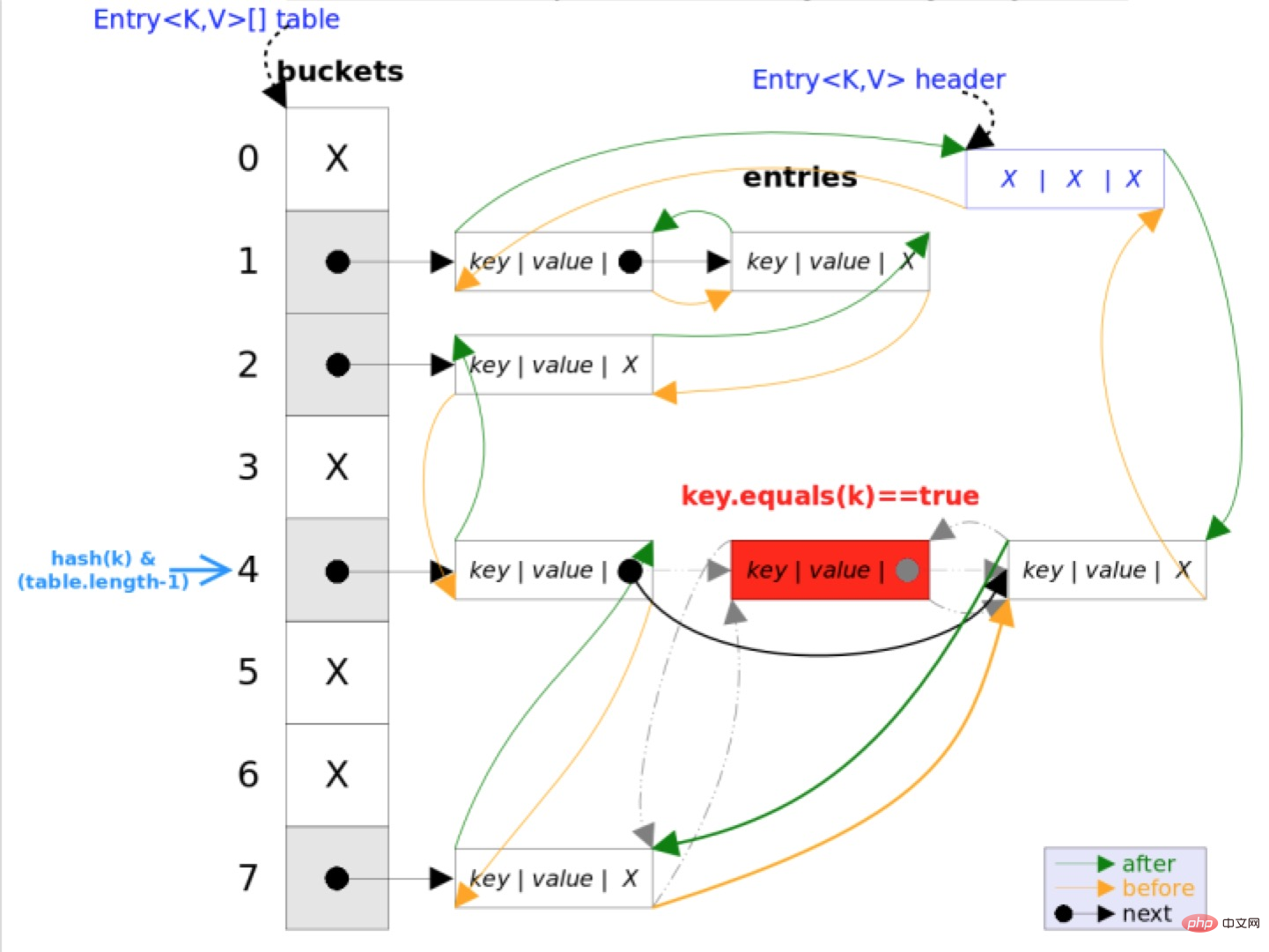
4. Zusammenfassung
LinkedHashMap erbt von HashMap Most Die Funktionsmerkmale sind grundsätzlich gleich. Der einzige Unterschied zwischen den beiden besteht darin, dass LinkedHashMap eine doppelt verknüpfte Liste verwendet, um alle auf HashMap basierenden Einträge zu verbinden. Dadurch wird sichergestellt, dass die Iterationsreihenfolge der Elemente mit der Einfügereihenfolge übereinstimmt. . Der Hauptteil ist genau derselbe wie HashMap, mit dem Zusatz, dass der Header auf den Kopf der doppelt verknüpften Liste zeigt und der Schwanz auf den Schwanz der doppelt verknüpften Liste zeigt. Die Standarditerationsreihenfolge der doppelt verknüpften Liste list ist die Einfügereihenfolge der Einträge.Dieser Artikel stammt von der chinesischen PHP-Website, Java-Tutorial-Kolumne, willkommen zum Lernen!
Das obige ist der detaillierte Inhalt vonAnalyse von LinkedHashMap in einfachen Worten (Bilder und Text). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!