
Heim >Backend-Entwicklung >Python-Tutorial >Was muss für den Python-Crawler installiert werden?
Was muss für den Python-Crawler installiert werden?

- 藏色散人Original
- 2019-07-05 10:28:2711011Durchsuche

80 % der Crawler weltweit werden auf Basis von Python entwickelt. Durch das Erlernen von Crawlerfähigkeiten können wichtige Datenquellen für die anschließende Big-Data-Analyse, das Mining, maschinelles Lernen usw. bereitgestellt werden.
Der Python-Crawler muss verwandte Bibliotheken installieren:
Am Python-Crawler beteiligte Bibliotheken:
Anforderungsbibliothek, Parsing-Bibliothek, Repository, Tool-Bibliothek
1. Bibliothek anfordern: urllib/re/requests
(1) urllib/re ist die Bibliothek, die standardmäßig mit Python geliefert wird und mit dem folgenden Befehl überprüft werden kann:
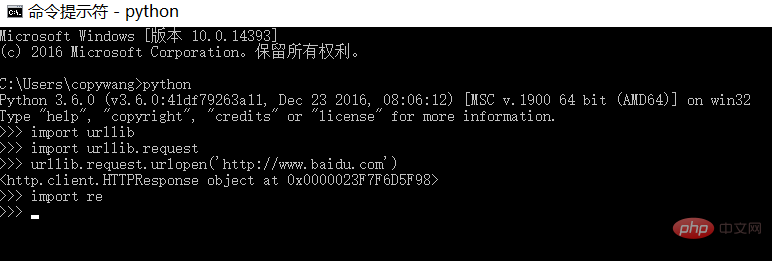
Es wird keine Fehlermeldung ausgegeben, was darauf hinweist, dass die Umgebung normal ist
(2) fordert Installation an
2.1 Öffnen Sie CMD und geben Sie
pip3 install requests
ein 2.2 Warten Sie auf die Installation und überprüfen Sie

(3) Selenium-Installation (steuert den Browser für das Website-Zugriffsverhalten)
3.1 Öffnen Sie CMD und geben Sie
pip3 install seleniumein
3.2 Chromedriver installieren
Website: https://npm.taobao.org/
Entpacken Sie das heruntergeladene komprimierte Paket und legen Sie die Exe-Datei im Pfad D:Python3.6.0Scripts ab
Solange es sich in der PATH-Variablen befindet
3.3 Nachdem die Installation abgeschlossen ist, überprüfen Sie

und drücken Sie die Eingabetaste, um das Chrome aufzurufen Browseroberfläche
3.4 Andere Browser installieren
Schnittstellenloser Browser Phantomjs
Download-URL: http://phantomjs.org/
Nachdem der Download abgeschlossen ist, Entpacken Sie es und legen Sie das gesamte Verzeichnis in D: Python3.6.0 ab. Skripte, fügen Sie den Pfad zum bin-Verzeichnis zur PATH-Variablen hinzu
Überprüfung:
CMD öffnen
phantomjs console.log('phantomjs') CTRL+C python from selenium import webdriver driver = webdriver.PhantomJS() dirver.get('http://www.baidu.com') driver.page_source
2 . Parsing-Bibliothek:
2.1 lxml (XPATH)
Öffnen Sie CMD
pip3 install lxml
oder laden Sie es von https://pypi.python.org herunter, zum Beispiel lxml -4.1.1-cp36-cp36m-win_amd64.whl (md5), laden Sie zuerst die WHL-Datei herunter
pip3 install 文件名.whl
2.2 beautifulsoup
Öffnen Sie CMD, Sie müssen lxml installieren
pip3 install beautifulsoup4
Überprüfung
python from bs4 import BeautifulSoup soup = BeautifulSoup('<html></html>','lxml')
2.3 pyquery (ähnlich der jquery-Syntax)
CMD öffnen
pip3 install pyquery
Installationsergebnisse überprüfen
python from pyquery import PyQuery as pq doc = pq('<html>hi</html>') result = doc('html').text() result

3. Repository
3.1 pymysql (Operation MySQL, relationale Datenbank)
Installation:
pip3 install pymysql
Post-Installationstest:
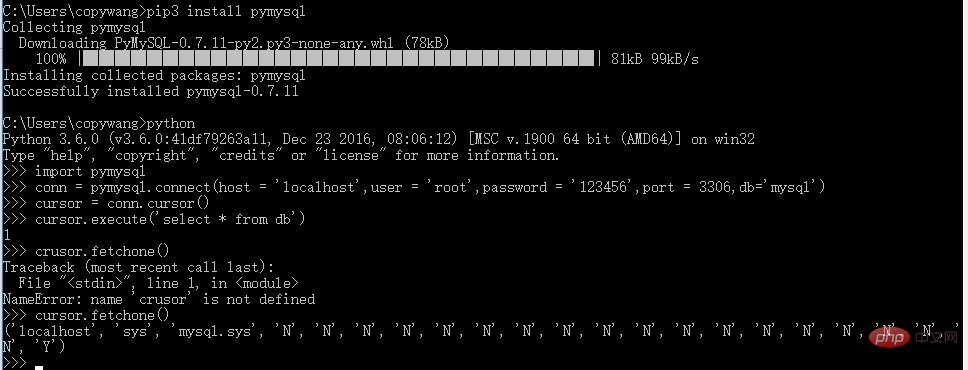
3.2 Pymongo (Betrieb von MongoDB, Schlüsselwert)
Installation
pip3 install pymongo
Verifizierung
python
import pymongo
client = pymongo.MongoClient('localhost')
db = client['testdb']
db['table'].insert({'name':'bob'})
db['table'].find_one({'name':'bob'}) 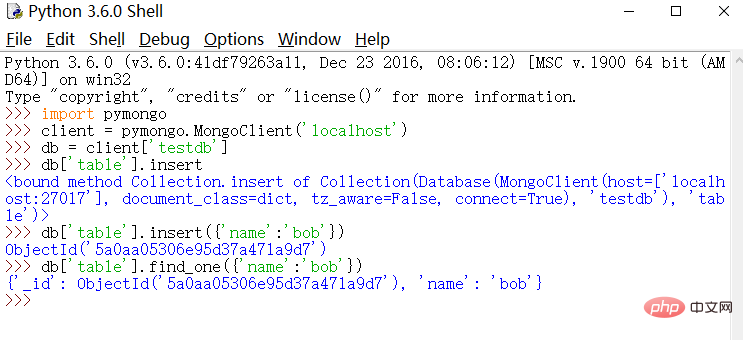
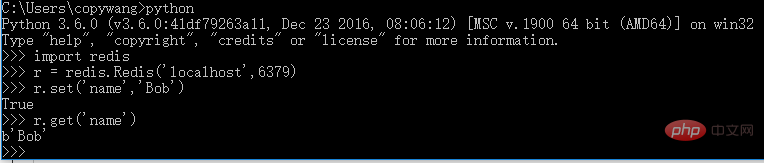
3.3 Redis (verteilter Crawler, Crawling-Warteschlange beibehalten)
Installation:
pip3 install redis
Überprüfung:
4. Tool-Bibliothek
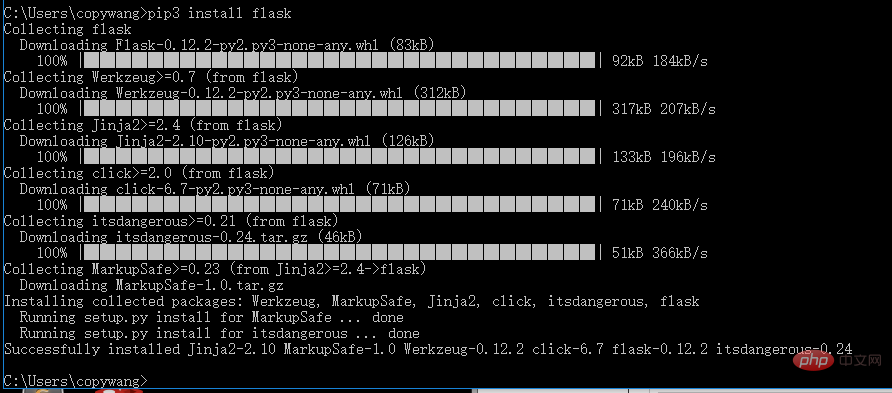
4.1 Flask (WEB-Bibliothek)
pip3 install flask
4.2 Django (verteiltes Crawler-Wartungssystem)
pip3 install django
4.3 jupyter (läuft auf der Webseite Notepad auf dem Client unterstützt Markdown und kann Code auf der Webseite ausführen)
pip3 install jupyter
Überprüfung:
Öffne CMD
jupyter notebook
und Sie können Notizblock- und Codeblöcke direkt auf der Webseite und Markdown-Blöcke erstellen und das Drucken unterstützen
[Verwandte Empfehlungen]
1. Python-Crawler-Bibliothek und zugehörige Tools
2. Erste Schritte mit Python-Crawlern-Tutorial
Das obige ist der detaillierte Inhalt vonWas muss für den Python-Crawler installiert werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!