
Heim >Backend-Entwicklung >PHP-Problem >So verwenden Sie die PHP-Funktion html_entity_decode
So verwenden Sie die PHP-Funktion html_entity_decode

- 青灯夜游Original
- 2019-05-27 10:06:332749Durchsuche
Die Funktion html_entity_decode() wird verwendet, um HTML-Entitäten in Zeichen umzuwandeln. Die Syntax ist html_entity_decode(string, flags, Zeichensatz).
Wie verwende ich die PHP-Funktion html_entity_decode()?
Die Funktion html_entity_decode() wandelt HTML-Entitäten in Zeichen um.
Syntax
html_entity_decode(string,flags,character-set)
Parameter:
1. Zeichenfolge: erforderlich. Gibt die zu dekodierende Zeichenfolge an.
2. Flags: optional. Gibt an, wie mit Anführungszeichen umgegangen wird und welcher Dokumenttyp verwendet wird.
Verfügbare Angebotstypen:
● ENT_COMPAT – Standard. Es werden nur doppelte Anführungszeichen dekodiert.
● ENT_QUOTES – Doppelte und einfache Anführungszeichen dekodieren.
● ENT_NOQUOTES – Keine Anführungszeichen entschlüsseln.
Zusätzliche Flags, die den verwendeten Dokumenttyp angeben:
● ENT_HTML401 – Standard. Code verarbeitet als HTML 4.01.
● ENT_HTML5 – Behandeln Sie Code als HTML 5.
● ENT_XML1 – Code als XML 1 verarbeiten.
● ENT_XHTML – als XHTML-Verarbeitungscode.
3. Zeichensatz: optional. Zeichenfolgenwert, der den zu verwendenden Zeichensatz angibt. Zulässige Werte:
● UTF-8 – Standard. ASCII-kompatibler Multibyte-8-Bit-Unicode
● ISO-8859-1 – Westeuropa
● ISO-8859-15 – Westeuropa (Eurozeichen + ISO-8859 hinzugefügt -1 französische und finnische Buchstaben fehlen in .)
● cp866 – DOS-spezifischer kyrillischer Zeichensatz
● cp1251 – Windows-spezifischer kyrillischer Zeichensatz
● cp1252 – Windows -spezifischer westeuropäischer Zeichensatz
● KOI8-R – Russisch
● BIG5 – Traditionelles Chinesisch, hauptsächlich in Taiwan verwendet
● GB2312 – Vereinfachtes Chinesisch, nationaler Standardzeichensatz
● BIG5-HKSCS – Big5 mit Hongkong-Erweiterung
●Shift_JIS – Japanisch
● EUC-JP – Japanisch
● MacRoman – Verwendeter Zeichensatz von Mac-Betriebssystemen
Hinweis: In Versionen vor PHP 5.4 werden nicht erkannte Zeichensätze ignoriert und durch ISO-8859-1 ersetzt. Ab PHP 5.4 werden nicht erkannte Zeichensätze ignoriert und durch UTF-8 ersetzt.
Rückgabewert: Gibt die konvertierte Zeichenfolge zurück
Nehmen wir ein Beispiel, um zu sehen, wie die PHP-Funktion strstr() verwendet wird.
Beispiel 1: HTML-Entitäten in Zeichen umwandeln
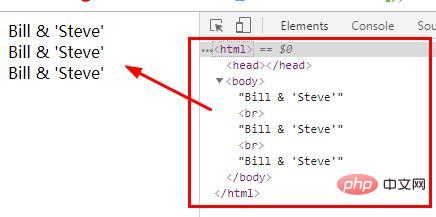
<?php $str = "Bill & 'Steve'"; echo html_entity_decode($str, ENT_COMPAT); // 只转换双引号 echo "<br>"; echo html_entity_decode($str, ENT_QUOTES); // 转换双引号和单引号 echo "<br>"; echo html_entity_decode($str, ENT_NOQUOTES); // 不转换任何引号 ?>
Ausgabe:
Beispiel 2: HTML-Entitäten mithilfe westeuropäischer Zeichensätze in Zeichen umwandeln
<?php $str = "My name is Øyvind Åsane. I'm Norwegian."; echo html_entity_decode($str, ENT_QUOTES, "ISO-8859-1"); ?>
HTML-Ausgabe des obigen Codes (Quellcode anzeigen):
<!DOCTYPE html> <html> <body> My name is ?yvind ?sane. I'm Norwegian. </body> </html>
Browser-Ausgabe des obigen Codes:
My name is ?yvind ?sane. I'm Norwegian.
Das obige ist der detaillierte Inhalt vonSo verwenden Sie die PHP-Funktion html_entity_decode. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!