
Heim >Backend-Entwicklung >PHP-Tutorial >Strategien und Methoden zur Verhinderung wiederholter Auftragserteilung
Strategien und Methoden zur Verhinderung wiederholter Auftragserteilung

- 藏色散人nach vorne
- 2019-05-14 09:17:275758Durchsuche
Hintergrund
In der Geschäftsentwicklung stehen wir oft vor dem Problem, wiederholte Anfragen zu verhindern. Wenn die Antwort des Servers auf eine Anfrage eine Datenänderung oder Statusänderung beinhaltet, kann dies großen Schaden anrichten. Besonders gravierend sind die Folgen wiederholter Anfragen bei Transaktionssystemen, dem Schutz von After-Sales-Rechten und Zahlungssystemen.
Jitter bei Vordergrundvorgängen, schnelle Vorgänge, Netzwerkkommunikation oder langsame Back-End-Reaktionen erhöhen die Wahrscheinlichkeit einer wiederholten Verarbeitung im Back-End. Um Maßnahmen zu ergreifen, um Front-End-Vorgänge zu entprellen und schnelle Vorgänge zu verhindern, denken wir zunächst an eine Kontrollebene im Front-End. Wenn das Frontend einen Vorgang auslöst, wird möglicherweise eine Bestätigungsoberfläche angezeigt oder der Eintrag wird möglicherweise deaktiviert und der Countdown usw. wird hier nicht näher beschrieben. Allerdings können die Front-End-Beschränkungen nur einen kleinen Teil der Probleme lösen und sind nicht gründlich genug. Die Back-End-eigenen Antiduplikationsmaßnahmen sind unverzichtbar und obligatorisch.
Bei der Schnittstellenimplementierung verlangen wir häufig, dass die Schnittstelle die Idempotenz erfüllt, um sicherzustellen, dass nur eine der wiederholten Anforderungen gültig ist.
Die Schnittstelle der Abfrageklasse ist fast immer idempotent, aber wenn sie Dateneinfügung und Datenaktualisierung mit mehreren Modulen umfasst, wird es schwieriger, Idempotenz zu erreichen, insbesondere die Idempotenzanforderungen bei hoher Parallelität. Beispielsweise sind Front-End-Rückrufe und Hintergrundrückrufe von Drittanbietern, Batch-Rückrufe von Drittanbietern, langsame Geschäftslogik (z. B. Benutzer, die Rückerstattungsanträge einreichen, Händler, die einer Rückgabe/Rückerstattung zustimmen usw.) oder langsame Netzwerkumgebungen ein hohes Risiko. Risikoszenarien für wiederholte Verarbeitung.
Versuchen Sie es
Hier ist ein Beispiel für „Benutzer, der eine Rückerstattungsanforderung einreicht“, um die Wirkung der versuchten Verarbeitungsmethode zur Verhinderung von Duplikaten zu veranschaulichen. Wir haben drei Methoden der Back-End-Antiduplikationsverarbeitung ausprobiert:
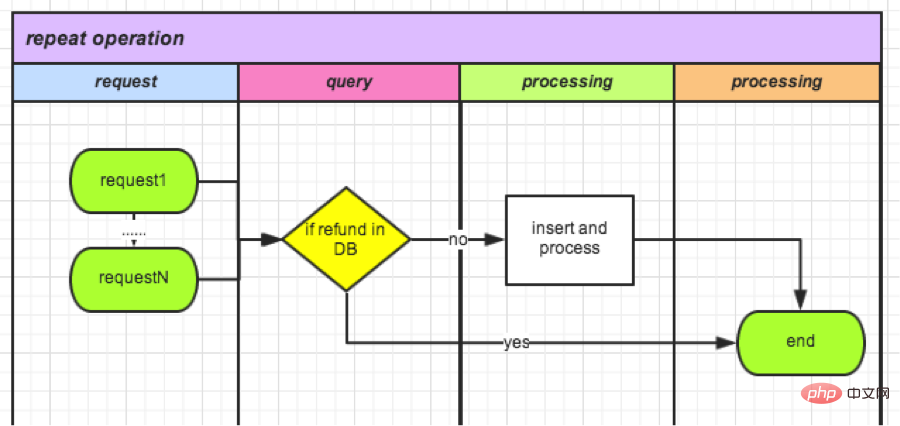
(1) Überprüfung basierend auf dem Rückerstattungsauftragsstatus in DB
Diese Methode ist einfach und intuitiv und wird von DB Refund abgefragt Details (einschließlich Status) können häufig auch in der Folgelogik verwendet werden, ohne dass zusätzliche Arbeit speziell für die Bearbeitung wiederholter Anfragen erforderlich ist.
Diese Art von Logik zur Überprüfung nach der Statusabfrage ist in allen Geschäftslogikverarbeitungen vorhanden, die den Status enthalten, seit der Code online ging, und ist unverzichtbar. Die Wirkung der Anti-Duplikationsverarbeitung ist jedoch nicht gut: Vor der Hinzufügung der Anti-Duplikations-Übermittlung im Front-End lag die durchschnittliche Anzahl bei 25 pro Woche, nach der Front-End-Optimierung sank sie auf 7 pro Woche. Diese Zahl macht 3 % der Gesamtzahl der Erstattungsanträge aus, ein Anteil, der immer noch inakzeptabel ist.
Solange eine Anfrage den Abfragevorgang abschließt, bevor der Datenstatus aktualisiert wird, erfolgt theoretisch eine wiederholte Verarbeitung der Geschäftslogik. Wie unten gezeigt. Die Optimierungsrichtung besteht darin, die Geschäftsverarbeitungszeit zwischen Abfrage und Aktualisierung zu verkürzen, wodurch die Auswirkungen der Lückenperiode auf die Parallelität verringert werden können. Im Extremfall, wenn Abfragen und Aktualisierungen zu atomaren Operationen werden, besteht unser aktuelles Problem nicht.
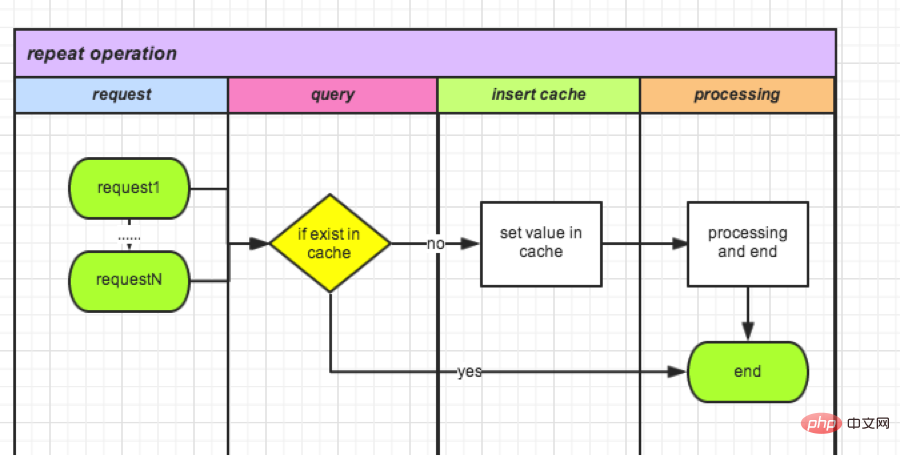
(2) Überprüfung basierend auf dem Status der zwischengespeicherten Daten
Redis-Speicherabfrage ist einfach und schnell. Wenn die Anfrage eingeht, kann sie zunächst im Cache aufgezeichnet werden. Nachfolgend eingehende Anfragen werden jeweils überprüft. Der gesamte Vorgang ist abgeschlossen und der Cache wird geleert. Nehmen Sie als Beispiel eine Rückerstattung:
- I. Lesen Sie bei jeder Initiierung eines Rückerstattungsantrags, ob ein Wert mit orderId als Schlüssel im Cache vorhanden ist.
- II. Gehen Sie zum Cache. Schreiben Sie den Wert
- III mit der Bestell-ID als Schlüssel. Wenn ja, bedeutet dies, dass die Rückerstattung der Bestellung läuft.
- IV. Leeren Sie den Cache nach dem Vorgang oder legen Sie den Lebenszyklus fest, wenn der Cache-Wert gespeichert wird.
Im Vergleich zu 1) wird die Datenbank durch einen Cache ersetzt, der schneller reagiert. Aber immer noch keine atomare Operation. Zwischen dem Einfügen und dem Lesen des Caches liegt noch ein Zeitintervall. Im Extremfall kommt es dennoch zu wiederholten Operationen. Nachdem diese Methode optimiert ist, wird der Vorgang einmal pro Woche wiederholt.
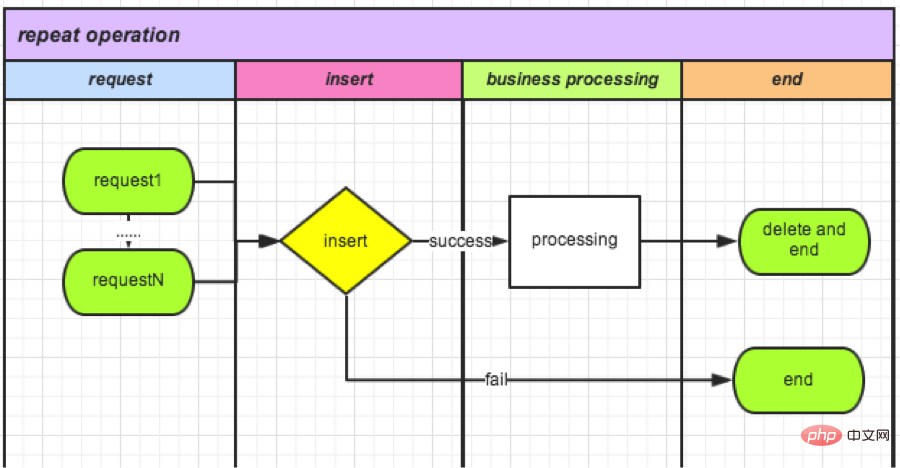
(3) Die Überprüfung mithilfe des eindeutigen Indexmechanismus
erfordert atomare Operationen, sodass mir der eindeutige Index der Datenbank in den Sinn kommt. Erstellen Sie eine neue TradeLock-Tabelle:
CREATE TABLE `TradeLock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `type` int(11) NOT NULL COMMENT '锁类型', `lockId` int(11) NOT NULL DEFAULT '0' COMMENT '业务ID', `status` int(11) NOT NULL DEFAULT '0' COMMENT '锁状态', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='Trade锁机制';
● Fügen Sie jedes Mal, wenn eine Anfrage eingeht, Daten in die Tabelle ein:
成功,则可以继续操作(相当于获取锁); 失败,则说明有操作在进行。
● Nachdem der Vorgang abgeschlossen ist, löschen Sie diesen Datensatz. (Entspricht dem Lösen der Sperre).
Es ist jetzt online und wartet auf die Datenstatistik nächste Woche.
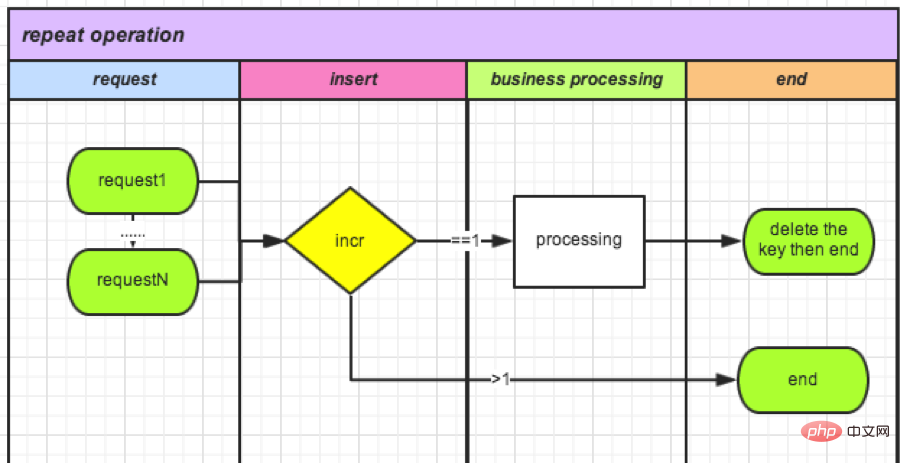
(4) Cache-basierte Zählerüberprüfung
Da Datenbankoperationen relativ leistungsintensiv sind, haben wir gelernt, dass Redis-Zähler auch atomare Operationen sind. Setzen Sie Zähler gezielt ein. Es kann nicht nur die Leistung verbessern, sondern auch den Bedarf an Speicher eliminieren und die Spitzen-QPS erhöhen.
Nehmen wir die Rückerstattung einer Bestellung als Beispiel:
● Jedes Mal, wenn eine Anfrage eingeht, wird ein neuer Zähler mit orderId als Schlüssel erstellt und dann +1.
如果>1(不能获得锁): 说明有操作在进行,删除。 如果=1(获得锁): 可以操作。
● Betriebsende (Löschsperre): Diesen Zähler löschen.
要了解计数器,可以参考:http://www.redis.cn/commands/incr.html
总结:
PHP语言自身没有提供进程互斥和锁定机制。因此才有了我们上面的尝试。网上也有文件锁机制,但是考虑到我们的分布式部署,建议还是用缓存。在大并发的情况下,程序各种情况的发生。特别是涉及到金额操作,不能有一分一毫的差距。所以在大并发要互斥的情况下可以考虑3、4两种方案。
爱迪生尝试了1600多种材料选择了钨丝发明了灯泡,实践出真知。遇到问题,和问题斗争,最后解决问题是一个最大提升自我的过程,不但加宽自己的知识广度,更加深了自己的技能深度。达到目标之后的成就感更是不言而喻。
Das obige ist der detaillierte Inhalt vonStrategien und Methoden zur Verhinderung wiederholter Auftragserteilung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Asynchrone Benachrichtigungs- und Verifizierungsauftragsmethode zum Aufrufen des SDK nach der Zahlung im WeChat-Applet
- Detaillierte Erläuterung der asynchronen Benachrichtigungs- und Überprüfungsverarbeitungsmethode zum Aufrufen des SDK nach der Zahlung im WeChat-Applet
- 5 Möglichkeiten, eindeutige Bestellnummern in PHP zu generieren
- PHP-Code zur Verarbeitung von WeChat-Zahlungsrückrufen, um den Zahlungsstatus der Bestellung zu ändern