
Heim >Datenbank >MySQL-Tutorial >Was sind die Unterschiede zwischen MySQL-Speicher-Engines?
Was sind die Unterschiede zwischen MySQL-Speicher-Engines?

- 清浅Original
- 2019-05-06 11:33:124465Durchsuche
Der Unterschied zwischen Speicher-Engines in MySQL: Wenn man Innodb und Myisam als Beispiel nimmt, unterstützt erstere Transaktionen, erstere legt jedoch nicht Wert auf Vielseitigkeit und unterstützt erweiterte Funktionen, während erstere sich hauptsächlich auf die Leistung konzentriert unterstützt keine Volltextindizierung, und letztere unterstützt die Volltextindizierung usw.
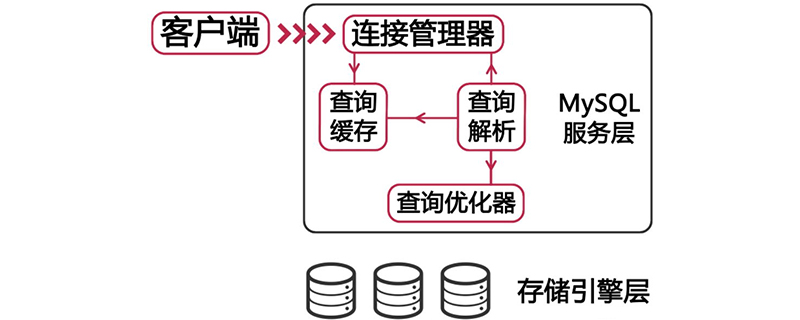
MySQL unterstützt mehrere Speicher-Engines. Hier besprechen wir hauptsächlich einige häufig verwendete Speicher Motoren. Innodb, myisam
INNODB
INNODB-Indeximplementierung
Das Gleiche wie MyISAM ist, dass InnoDB auch B+Tree verwendet Diese Datenstruktur wird zur Implementierung des B-Tree-Index verwendet. Der große Unterschied besteht darin, dass die InnoDB-Speicher-Engine die Datenspeichermethode „Clustered Index“ verwendet, um den B-Tree-Index zu implementieren. Die sogenannte „Aggregation“ bedeutet, dass die Datenzeilen und benachbarten Schlüsselwerte kompakt zusammen gespeichert werden Beachten Sie, dass InnoDB nur die Datensätze einer Blattseite (16 KB) aggregieren kann (d. h. der Clustered-Index erfüllt einen bestimmten Bereich von Datensätzen), sodass Datensätze mit benachbarten Schlüsselwerten möglicherweise weit voneinander entfernt sind.
In InnoDB wird die Tabelle als indexorganisierte Tabelle bezeichnet. InnoDB erstellt einen B+Baum entsprechend dem Primärschlüssel (wenn kein Primärschlüssel vorhanden ist, wird stattdessen ein eindeutiger und nicht leerer Index ausgewählt. Wenn Ohne einen solchen Index definiert InnoDB implizit einen Primärschlüssel als Clustered-Index, und die Blattseiten speichern die Zeilendatensatzdaten der gesamten Tabelle. Die Blattknoten des Clustered-Index können auch als Datenseiten und Nicht-Blatt-Seiten bezeichnet werden Seiten können als spärlicher Index von Blattseiten betrachtet werden.
Die folgende Abbildung veranschaulicht die Implementierung des InnoDB-Clusterindex und spiegelt auch die Struktur einer InnoDB-Tabelle wider. Es ist ersichtlich, dass in InnoDB der Primärschlüsselindex und die Daten integriert und nicht getrennt sind.
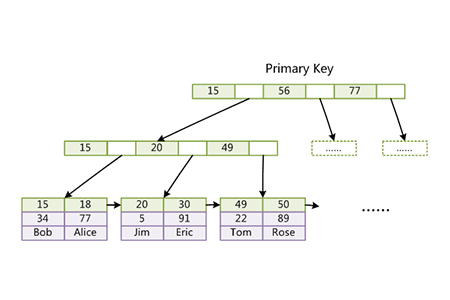
Diese Implementierungsmethode verleiht InnoDB eine extrem hohe Leistung für den Abruf per Primärschlüssel. Sie können einen Clustered-Index gezielt auswählen, z. B. eine Mail-Tabelle, und Sie können eine Benutzer-ID zum Aggregieren von Daten auswählen. Auf diese Weise müssen Sie nur eine kleine Anzahl aufeinanderfolgender Datenseiten von der Festplatte lesen, um alle E-Mails eines zu erhalten Benutzer mit einer bestimmten ID, sodass keine zufälligen E/A-Vorgänge für das Lesen verstreuter Seiten erforderlich sind.
InnoDB ist eine E/A-Operation, die Innodb zum Lesen und Schreiben verwendet, um eine hohe Parallelität zu unterstützen.
Vollständiger Tabellenscan
Wenn InnoDB einen vollständigen Tabellenscan durchführt, ist dies nicht effizient, da InnoDB tatsächlich nicht sequenziell liest . Bei einem vollständigen Tabellenscan scannt InnoDB Seiten und Zeilen in der Reihenfolge der Primärschlüssel. Dies gilt für alle InnoDB-Tabellen, einschließlich fragmentierter Tabellen. Wenn die Primärschlüsselseitentabelle (die Seitentabelle, die Primärschlüssel und Zeilen speichert) nicht fragmentiert ist, ist ein vollständiger Tabellenscan recht schnell, da die Lesereihenfolge nahe an der physischen Speicherreihenfolge liegt. Wenn die Primärschlüsselseite jedoch fragmentiert ist, wird der Scan sehr langsam.
Sperre auf Zeilenebene
Bietet Zeilensperre (Sperrung auf Zeilenebene), bereitgestellt von Oracle Typkonsistentes, nicht sperrendes Lesen in SELECTs. Darüber hinaus ist die Zeilensperre der InnoDB-Tabelle nicht absolut. Wenn MySQL den zu scannenden Bereich beim Ausführen einer SQL-Anweisung nicht bestimmen kann, sperrt die InnoDB-Tabelle auch die gesamte Tabelle , wie zum Beispiel
update table set num=1 where name like “%aaa%”
MYISAM
Implementierung von MyISAM-Indizes
Jedes MyISAM wird als drei Dateien auf der Festplatte gespeichert. Der Name der ersten Datei beginnt mit dem Namen der Tabelle und die Erweiterung gibt den Dateityp an. Die MyISAM-Indexdatei [.MYI (MYIndex)] und die Datendatei [.MYD (MYData)] sind getrennt. Die Indexdatei speichert nur den Zeiger (physischen Speicherort) der Seite, auf der sich der Datensatz befindet Diese Adressen und dann wird die Seite gelesen. Werfen wir zunächst einen Blick auf das Strukturdiagramm
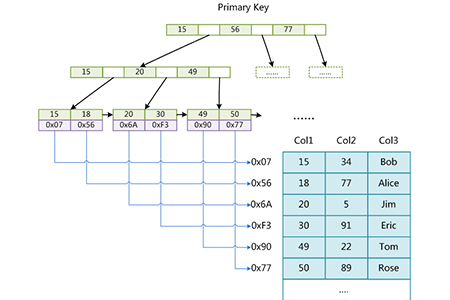
Das obige Bild zeigt gut, dass die Blätter im Baum die physische Position der entsprechenden Zeile speichern. Durch diesen Wert kann die Speicher-Engine die Tabelle reibungslos abfragen und eine vollständige Datensatzzeile erhalten. Gleichzeitig speichert jede Blattseite auch einen Zeiger auf die nächste Blattseite. Dies erleichtert das Durchqueren der Reichweite von Blattknoten. Der Sekundärindex wird in der MyISAM-Speicher-Engine auf die gleiche Weise wie in der obigen Abbildung implementiert. Dies zeigt auch, dass die Indizierungsmethode von MyISAM „nicht geclustert“ ist, was im Gegensatz zum „Clustered-Index“ von Innodb steht
MyISAM liest den Index standardmäßig in den Speicher und arbeitet direkt im Speicher.
Sperre auf Tabellenebene
Zusammenfassung: Innodb legt Wert auf Vielseitigkeit und den Vergleich der unterstützten Elemente Erweiterte Funktionen Viele, Myisam konzentriert sich hauptsächlich auf die Leistung
Unterschiede
1. InnoDB unterstützt jedoch nicht jede SQL-Sprache in einer Transaktion Standardmäßig und automatisch übermittelt, wirkt sich dies auf die Geschwindigkeit aus. Daher ist es am besten, mehrere SQL-Anweisungen zwischen begin und commit einzufügen, um eine Transaktion zu bilden.
2 ist an den Index gebunden und muss vorhanden sein. Es muss ein Primärschlüssel vorhanden sein, und die Indizierung über den Primärschlüssel ist sehr effizient. Der Hilfsindex erfordert jedoch zwei Abfragen: Zuerst wird der Primärschlüssel abgefragt und dann werden die Daten über den Primärschlüssel abgefragt. Daher sollte der Primärschlüssel nicht zu groß sein, denn wenn der Primärschlüssel zu groß ist, werden auch andere Indizes groß. MyISAM ist ein nicht gruppierter Index, die Datendateien sind getrennt und der Index speichert den Zeiger der Datendatei. Primärschlüsselindizes und Sekundärindizes sind unabhängig.
3. InnoDB speichert nicht die spezifische Anzahl von Zeilen in der Tabelle. Beim Ausführen von „select count(*) from table“ ist ein vollständiger Tabellenscan erforderlich. MyISAM verwendet eine Variable, um die Anzahl der Zeilen in der gesamten Tabelle zu speichern. Wenn Sie die obige Anweisung ausführen, ist dies sehr schnell.
4 , während MyISAM den Volltextindex unterstützt. In Bezug auf die Abfrageeffizienz ist MyISAM höher;
Das obige ist der detaillierte Inhalt vonWas sind die Unterschiede zwischen MySQL-Speicher-Engines?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!