
Heim >Datenbank >MySQL-Tutorial >Was verwenden große Unternehmen für MySQL-Cluster?
Was verwenden große Unternehmen für MySQL-Cluster?

- anonymityOriginal
- 2019-05-05 18:13:456168Durchsuche
In kleinen und mittleren Internetunternehmen. MySQL-Cluster haben im Allgemeinen die oben gezeigte Architektur. Der WEB-Knoten liest beim Lesen der Datenbank den dbproxy-Server. Der dbproxy-Server trennt das Lesen und Schreiben der Datenbank durch die Beurteilung von SQL-Anweisungen. Leseanforderungen werden in die Slave-Bibliothek geladen (die Master-Bibliothek kann ebenfalls hinzugefügt werden) und Schreibanforderungen werden in die Master-Bibliothek geschrieben.

Der Dbproxy ist hier der einzige Ausgang des Datenbankclusters, daher muss er auch hochverfügbar sein.
drproxy ist eine häufig verwendete Software für die Lese- und Schreibtrennung von Datenbanken. Amoeba, Mycat und Cobar werden ebenfalls häufig verwendet. Diese Art von Software hat nicht nur die Funktion der Trennung von Lesen und Schreiben, sondern kann auch einen Lastausgleich und eine Gesundheitsprüfung von Back-End-Knoten implementieren.
Diese Art von Datenbank-Middleware-Software realisiert nicht nur die Trennung von Lesen und Schreiben in der Datenbank, sondern kann auch in das Programm geschrieben werden.
Normalerweise muss unsere Hauptbibliothek Dual-Master-hochverfügbar sein, sodass bei einem Ausfall der Hauptbibliothek die andere Hauptbibliothek sofort übernimmt. Wenn kein Dual-Master verwendet wird, ist eine Statusmigration erforderlich, wenn die Slave-Datenbank die Master-Datenbank übernimmt, was zu einer Verzögerung führt.
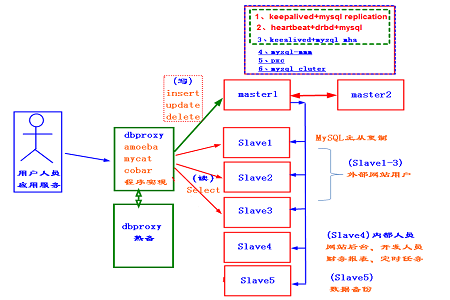
Der Hauptpunkt der Hochverfügbarkeit für die Hauptdatenbank ist die Datensynchronisierung. Die am häufigsten verwendeten Hochverfügbarkeitslösungen sind:
1. Keepalived+MySQL-Replikation. VIP-Eleganz wird durch Keepalived erreicht, und Datensynchronisierung wird durch Replikation erreicht, die von MySQL bereitgestellte Synchronisierungslösung.
2. Hearbeat+drbd. Die Dual-Master-Datensynchronisation wird durch DRBD erreicht. Diese Datensynchronisation basiert auf Blockgeräten. Viel schneller als herkömmliche Synchronisationslösungen. Realisieren Sie die Verwaltung von VIP-Drift und DRBD-Ressourcenwechsel durch Heartbeat.
3. keepalived+mha.
Für Slave-Bibliotheken ist es am besten, 5 nicht zu überschreiten. Wir können drei davon als Knoten verwenden, auf die Benutzer zugreifen können, und den anderen als Abfrageknoten für Insider. Denn wenn interne Mitarbeiter Knoten abfragen, erfolgt die Abfrage normalerweise nach Zeiträumen ohne Indizierung, was viele Ressourcen beansprucht. Daher muss dieser Knoten separat dediziert werden, um den Kundenzugriff nicht zu beeinträchtigen. Schließlich sollten wir eine Slave-Datenbank zur Datensicherung der Datenbank belassen.
Die Datenkonsistenz der Slave-Datenbank kann durch Master-Slave-Unterstützung direkt aus der Master-Datenbank oder durch Master-Slave-Replikation von anderen Slave-Datenbanken aufrechterhalten werden (der Vorteil besteht darin, den Druck auf die Master-Datenbank zu verringern, aber Der Nachteil ist, dass die Verzögerung etwas größer ist).
Das obige ist der detaillierte Inhalt vonWas verwenden große Unternehmen für MySQL-Cluster?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!