
Heim >Datenbank >MySQL-Tutorial >Eine kurze Diskussion über die Data-Warehouse-Technologie
Eine kurze Diskussion über die Data-Warehouse-Technologie

- little bottlenach vorne
- 2019-04-27 17:34:122610Durchsuche
In diesem Artikel geht es hauptsächlich um den Entwurf der logischen Data-Warehouse-Architektur, der einen gewissen Lernwert hat. Interessierte Freunde können mehr darüber erfahren.
Offline-Data-Warehouses werden normalerweise auf der Grundlage der dimensionalen Modellierungstheorie erstellt, hauptsächlich aus folgenden Gründen:
1. Benutzer sollten isoliert werden Verwenden Sie Daten, die vom Datenteam sorgfältig verarbeitet wurden, anstelle von Rohdaten aus dem Geschäftssystem. Der erste Vorteil besteht darin, dass Benutzer Daten verwenden, die aus geschäftlicher Sicht sorgfältig aufbereitet, standardisiert und sauber sind. Sehr einfach zu verstehen und zu verwenden. Zweitens: Wenn das vorgelagerte Geschäftssystem geändert oder sogar neu aufgebaut wird (z. B. Tabellenstruktur, Felder, Geschäftsbedeutung usw.), ist das Datenteam dafür verantwortlich, alle diese Änderungen zu bewältigen und die Auswirkungen auf nachgelagerte Benutzer zu minimieren.
2. Leistung und Wartbarkeit: Durch die Datenschichtung erfolgt die Datenverarbeitung grundsätzlich im Datenteam, sodass nicht wiederholt dieselbe Geschäftslogik ausgeführt werden muss. , wodurch entsprechender Speicher- und Rechenaufwand eingespart wird. Darüber hinaus macht die Datenschichtung die Wartung des Data Warehouse übersichtlich und komfortabel. Jede Schicht ist nur für ihre eigenen Aufgaben verantwortlich. Wenn bei der Datenverarbeitung auf einer bestimmten Schicht ein Problem auftritt, müssen Sie nur diese Schicht ändern.
3. Normativität: Für ein Unternehmen und eine Organisation ist die Qualität der Daten sehr wichtig Tabellen, Felder und Metriken müssen standardisiert sein.
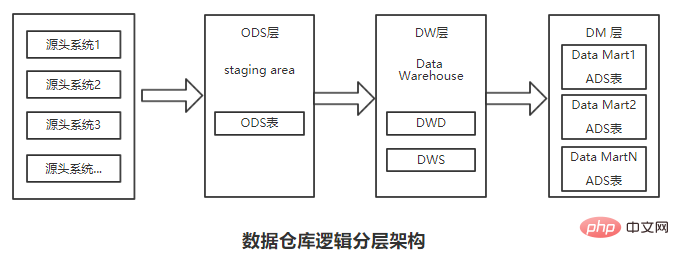
4. ODS-Schicht: Die Datentabelle des Data Warehouse-Quellsystems wird normalerweise intakt gespeichert. Dies wird oft als ODS-Schicht (Operation Data Store) bezeichnet Als Staging-Bereich sind sie die Quelle der Verarbeitungsdaten für die nachfolgende Data-Warehouse-Schicht (d. h. die Faktentabellen- und Dimensionstabellenschicht, die auf der Grundlage der Kimball-Dimensionsmodellierung generiert wurden, und die Zusammenfassungsschichtdaten, die auf der Grundlage dieser Faktentabellen und Detailtabellen verarbeitet wurden). Gleichzeitig speichert die ODS-Schicht auch historische inkrementelle Daten oder vollständige Daten.
5. DWD- und DWS-Schichten: Data Warehouse Detail (DWD) und Data Warehouse Summary (DWS) sind Gegenstand des Data Warehouse. Die Daten der DWD- und DWS-Schichten werden von der ODS-Schicht nach ETL-Bereinigung, Konvertierung und Laden generiert und basieren normalerweise auf Kimballs dimensionaler Modellierungstheorie, und die Dimensionen jedes Unterthemas werden durch konsistente Dimensionen und Datenbusse garantiert. Konsistenz.
6. Anwendungsschicht (ADS): Die Anwendungsschicht ist hauptsächlich der Data Mart (Data Mart, DM), der von jedem Unternehmen oder jeder Abteilung basierend auf DWD und DWS eingerichtet wird ist relativ zum Data Warehouse (Data Warehouse, DW) von DWD und DWS. Im Allgemeinen stammen die Daten der Anwendungsschicht von der DW-Schicht, ein direkter Zugriff auf die ODS-Schicht ist jedoch grundsätzlich nicht zulässig. Darüber hinaus enthält die Anwendungsschicht im Vergleich zur DW-Schicht nur detaillierte und zusammenfassende Schichtdaten, die für die Abteilungen oder Parteien selbst wichtig sind.
PHP-Chinese-Website!
Das obige ist der detaillierte Inhalt vonEine kurze Diskussion über die Data-Warehouse-Technologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!