
Heim >Java >javaLernprogramm >So implementieren Sie mit Java eine P2P-Seed-Suchfunktion
So implementieren Sie mit Java eine P2P-Seed-Suchfunktion

- 不言nach vorne
- 2019-04-15 10:20:394164Durchsuche
Der Inhalt dieses Artikels befasst sich mit der Verwendung von Java zur Implementierung einer P2P-Seed-Suchfunktion. Ich hoffe, dass er für Freunde in Not hilfreich ist.
Ich hatte vor vielen Jahren großes Interesse an P2P, aber es blieb in der Theorie und hatte nie die Gelegenheit, es in die Praxis umzusetzen. Ich habe dieses Ding kürzlich implementiert. Ich denke, es gibt einige Dinge, die ich teilen kann. Kommen wir zum Punkt
Grundkonzepte
Bevor ich über P2P spreche, möchte ich darüber sprechen, wie wir Dateien herunterladen. Lassen Sie mich mehrere Möglichkeiten zum Herunterladen von Dateien auflisten
1. Verwenden Sie zum Herunterladen das http-Protokoll. Die am häufigsten verwendete Methode ist wahrscheinlich das Herunterladen von Dateien über einen Browser.
2. Zum Herunterladen gibt es zwei Modi: Port (aktiv) In diesem Modus öffnet der Client lokal eine FTP-Verbindung und dann senden Geben Sie dem FTP-Server N+1-Abhörport für die Datenübertragung. Wenn eine Firewall vorhanden ist oder der Client NAT ist, kann er nicht heruntergeladen werden. Eine andere Möglichkeit ist der passive Modus. In diesem Modus öffnet der FTP-Server zusätzlich zu Port 21 einen weiteren Port größer als 1023. Das heißt, der Client initiiert aktiv FTP-Verbindungen und Datenübertragungsverbindungen, solange der FTP-Server vorhanden ist ist offen. Es wird kein Problem mit diesem Port geben.
Die beiden oben genannten Methoden können zusammen als CS-Architektur bezeichnet werden. Bei dieser Architektur werden Ressourcen auf den Server konzentriert, wenn die Datenmenge ein bestimmtes Niveau erreicht. Um dieses Problem zu lösen, können wir an eine verteilte Dezentralisierung denken. P2P steht für Peer-to-Peer. Dabei handelt es sich um eine Peer-to-Peer-Architektur.
P2P-Architektur
Wenn Ressourcen auf jedem Knoten gespeichert sind, fragen wir uns möglicherweise: Wenn ich eine Ressource herunterlade, woher weiß ich, auf welchen Computern sich diese Datei befindet? Kann sie heruntergeladen werden?
In der frühen P2P-Architektur gab es eine Tracker-Rolle, die für die Speicherung von Metadateninformationen von Dateien verantwortlich war. Jetzt wird die Datei auf jedem Peer gespeichert und die Dateiinformationen werden über den Tracker abgerufen.
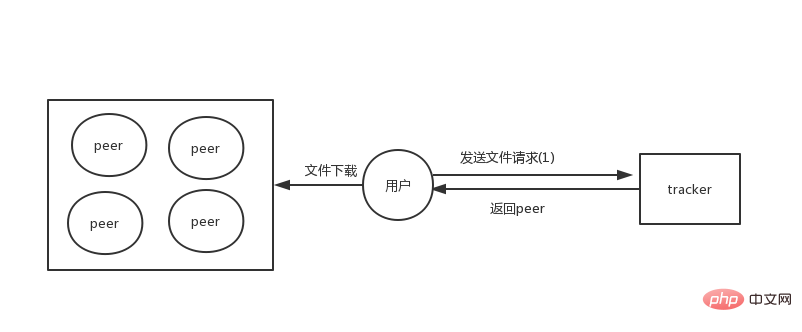
Unter dieser Architektur werden alle unsere Dateien verteilt, aber der Tracker ist für die Speicherung der Metadateninformationen aller Dateien verantwortlich, sodass der Tracker nur eine kleine Menge speichern muss von Daten im Vergleich zu vorhandenen Dateien wird relativ einfach sein.
Aber sobald der Tracker-Server hängt oder der Dienst nicht verfügbar ist, werden nicht alle Dateien heruntergeladen, da er nicht vollständig verteilt ist. Um vollständig dezentralisiert zu sein, wird später eine Tracker-lose Architektur entwickelt
Zu diesem Zeitpunkt existiert der Tracker nicht mehr und alle Dateien, einschließlich der Metadateninformationen der Dateien, werden verteilt gespeichert. DHTDHT (Distributed Hash Table) verteilte Hash-Tabelle, die als Ersatz für den Tracker verwendet wird. Es gibt viele Algorithmen zur Implementierung von DHT, wie zum Beispiel denKademlia-Algorithmus und so weiter.
Einige Konzepte:
3.Routing-Tabelle Routing-Tabelle
Der Schwerpunkt liegt hier auf der Implementierung, daher gibt es im Internet viele Informationen zum Hauptteil. Sie können sich auf
Wie man es implementiert
Es gibt zwei Schritte zur Implementierung der Seed-Suche. Der erste Schritt ist ein Crawler, der zum Crawlen von Seed-Informationen im Internet verwendet wird. Der zweite Schritt besteht darin, sich an der Suche zu beteiligen. Sie müssen über folgende Kenntnisse verfügen: Seeds, BitTorrent-DHT-Protokoll, BencodedWenn es um P2P geht, müssen wir Seeds erwähnen, also die Art von Dateien, die das Ergebnis sind .torrent. Jeder hat möglicherweise BT-Torrents verwendet, die Dateien heruntergeladen haben, und die heruntergeladenen Dateien verwenden das Bittorrent-Protokoll. Wie sammelt man Samen im Internet? Die in BT-Seeds enthaltenen Hauptfelder: https://segmentfault.com/a/1190000000681331Die in DHT erhaltenen Seeds werden als „Trackerless Torrent“ bezeichnet. Es gibt kein Ankündigungsattribut, aber es gibt stattdessen das nodes-Attribut. Es wird offiziell empfohlen, router.bittorrent.com nicht zum Seed oder zur Routing-Tabelle hinzuzufügen. 1.So erhalten Sie Samen von DHT
Wenn Sie die Sameninformationen erhalten möchten, müssen Sie über ein umfassendes Verständnis des DHT-Protokolls verfügen das DHT-Protokoll
Weitere Informationen finden Sie hier: http://www.bittorrent.org/beps/bep_0005.html
So implementieren Sie eine Routing-Tabelle:
Die Routing-Tabelle deckt alle Node-IDs ab, von 0 bis 2 hoch 160. Die Routing-Tabelle kann aus Buckets bestehen, und jeder Bucket deckt einen Teil aller Knoten ab. Zu Beginn gibt es nur einen Bucket in der Routing-Tabelle, der alle Nodeids abdeckt. Jeder Bucket kann nur bis zu K Knoten enthalten. Der aktuelle K-Wert beträgt 8. Wenn der Bucket voll ist und alle darin enthaltenen Knoten in Ordnung sind und sich die eigene Knoten-ID nicht in diesem Bucket befindet, wird der ursprüngliche Bucket in zwei neue Buckets aufgeteilt, die 0..2159
und 2 abdecken159..2160.
Wenn ein Bucket voll ist, werden neue Knoten leicht verworfen. Wenn ein Knoten darin offline geht, wird er ersetzt. Wenn ein Knoten in den letzten 15 Minuten nicht angepingt wurde, pingen Sie den Knoten an. Wenn keine Antwort zurückgegeben wird, wird der Knoten ebenfalls ersetzt.
Jeder Bucket sollte ein zuletzt geändertes Attribut haben, um die Aktivität dieses Buckets anzuzeigen. Dieses Feld wird in den folgenden Situationen aktualisiert:
1. Der Knoten im Bucket wird angepingt und hat eine Antwort
2. Ein Knoten wird zu diesem Bucket hinzugefügt
3 . Der Knoten im Bucket wurde ersetzt
Wenn der Bucket dieses Feld nicht innerhalb von 15 Minuten aktualisiert, wird eine ID innerhalb des Bucket-Bereichs zufällig ausgewählt, um die Operation „find_node“ auszuführen.
KRPC-Protokoll
Das KRPC-Protokoll wird zur Übertragung von Nachrichten im dht-Netzwerk verwendet.
1.ping
Ping-Abfrage wird hauptsächlich zur Heartbeat-Überprüfung verwendet
2.find_node
Suche Nach einem Knoten fragt die andere Partei die nächsten N Knoten ab und gibt sie aus ihrer eigenen Routing-Tabelle zurück, normalerweise 8
3.get_peers
finde den Besitzer von Der Infohash basiert auf dem Infohash-Peer. Wenn die zurückgegebenen Peers und keine Knoten gefunden werden, teilt return nodes
anderen Peers dies mit Sie haben auch Infohash.
Beachten Sie, dass die oben genannten vier die Routing-Tabelle aktualisieren
Zu Beginn gibt es keine Knoten in der Routing-Tabelle Sie müssen vom Superknoten aus beginnen (z. B. usw.), um Knoten über find_node-Anfragen zu finden und hinzuzufügen, und die zurückgegebenen Knoten werden für find_node verwendet.
Die Routing-Tabelle, die ich selbst implementiert habe, unterscheidet sich geringfügig von der oben beschriebenen. dht.transmissionbt.com
Wenn wir dem DHT-Netzwerk beitreten, können wir den Infohash der Seed-Datei nur über die vier oben vorgestellten Methoden abrufen, daher müssen wir den Seed auch über den Infohash herunterladen , siehe bep_009http://www.bittorrent.org/beps/bep_0009.html
Wir verwenden hauptsächlich bep_009, um das Namensfeld des Torrents abzurufen. Nachdem wir das Dateinamenfeld erhalten haben, können wir einen Index erstellen basierend auf dem Namen und dem Infohash, um eine Suche bereitzustellen. (Hier erstellen wir hauptsächlich Magnet-Links. Mit Magnet-Links können Sie zu Thunder, Baidu Netdisk usw. gehen, um Ressourcen herunterzuladen
)Die meisten Magnet-Link-Formate: magnet:?xt=urn : btih:infohash
Die oben vorgestellte Methode besteht darin, einen Magnet-Link zu erstellen, indem man Infohash erhält und ihn dann mithilfe von Software von Drittanbietern herunterlädt. Natürlich können Sie ihn auch selbst über das BitTorrent-Protokoll herunterladen. Wenn Sie interessiert sind, können Sie selbst recherchieren. Okay, das Obige stellt nur kurz einige Implementierungsschritte vor. In meinen eigenen Worten habe ich auf einige Github-DHT-Projekte verwiesen und sie dann selbst implementiert :https://github.com/mistletoe9527/dht-spiderDas obige ist der detaillierte Inhalt vonSo implementieren Sie mit Java eine P2P-Seed-Suchfunktion. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Analyse unveränderlicher Objekte in Java (mit Code)
- Zusammenfassung häufig verwendeter Array-Operationsmethoden in JavaScript (Code)
- Einführung in die Verwendung der neuen Java8-Funktion Optional (mit Code)
- Einführung in Java-Ausnahmebehandlungsmethoden (mit Code)
- Einführung in allgemeine JavaSE-Klassen und -Methoden (mit Code)