
Heim >Java >javaLernprogramm >Analyse mehrerer häufiger Java-Interviewfragen für die Personalbeschaffung im Herbst
Analyse mehrerer häufiger Java-Interviewfragen für die Personalbeschaffung im Herbst

- 青灯夜游nach vorne
- 2018-10-23 16:44:152559Durchsuche
In diesem Artikel finden Sie eine Analyse mehrerer häufiger Java-Interviewfragen für die Personalbeschaffung im Herbst. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird Ihnen hilfreich sein.
Vorwort
Nur eine Glatze kann dich stark machen
Redis schaut immer noch zu, heute werde ich meinen Herbst teilen Rekrutierung Einige Interviewfragen, die ich gesehen (relativ häufig) habe
0. Schlusswörter
Besprechen Sie kurz die letzten Schlüsselwörter Was kann mit dem Wort „final“ geändert werden?
Diese Frage ist mir damals in einem echten Interview begegnet. Ich habe sie nicht sehr gut beantwortet.
final kann Klassen, Methoden und Mitgliedsvariablen ändern
Wenn final eine Klasse ändert, bedeutet dies, dass die Klasse nicht vererbt werden kann
Wenn eine Methode endgültig geändert wird, bedeutet dies, dass die Methode nicht überschrieben werden kann
In den frühen Tagen kann die endgültig geänderte Methode sein verwendet, und die Compiler-Ziele Alle Aufrufe dieser Methoden werden in Inline-Aufrufe umgewandelt, was die Effizienz verbessert (aber jetzt ist uns das im Allgemeinen egal, Compiler und JVM werden immer intelligenter)
Wenn final eine Mitgliedsvariable ändert, gibt es zwei Situationen:
Wenn es sich um einen Basistyp handelt, bedeutet dies, dass der durch diese Variable dargestellte Wert niemals sein kann geändert (kann nicht neu zugewiesen werden)!
Wenn es sich bei der Änderung um einen Referenztyp handelt, kann die Referenz der Variablen nicht geändert werden, aber der Inhalt des durch die Referenz dargestellten Objekts ist variabel!
Es ist erwähnenswert, dass: nicht unbedingt bedeutet, dass durch final geänderte Mitgliedsvariablen Konstanten zur Kompilierungszeit sind . Wir können zum Beispiel Code wie folgt schreiben: private final int java3y = new Randon().nextInt(20);
Haben Sie solche Programmiererfahrung? Wenn Sie Code mit einem Compiler schreiben, müssen Sie die Variable in einem bestimmten Szenario als final deklarieren, sonst erfolgt die Kompilierung. Fehlersituation. Warum ist es so konzipiert?
Dies kann passieren, wenn anonyme innere Klassen geschrieben werden:
-
Externe Klasseninstanzvariablen
Lokale Variablen innerhalb einer Methode oder eines Bereichs
Parameter einer Methode
class Outer {
// string:外部类的实例变量
String string = "";
//ch:方法的参数
void outerTest(final char ch) {
// integer:方法内局部变量
final Integer integer = 1;
new Inner() {
void innerTest() {
System.out.println(string);
System.out.println(ch);
System.out.println(integer);
}
};
}
public static void main(String[] args) {
new Outer().outerTest(' ');
}
class Inner {
}
}Wo wir sehen können: Lokale Variablen und Methodenparameter innerhalb einer Methode oder Scope muss angezeigt und geändert werden mit dem finalen Schlüsselwort (unter jdk1.7)!
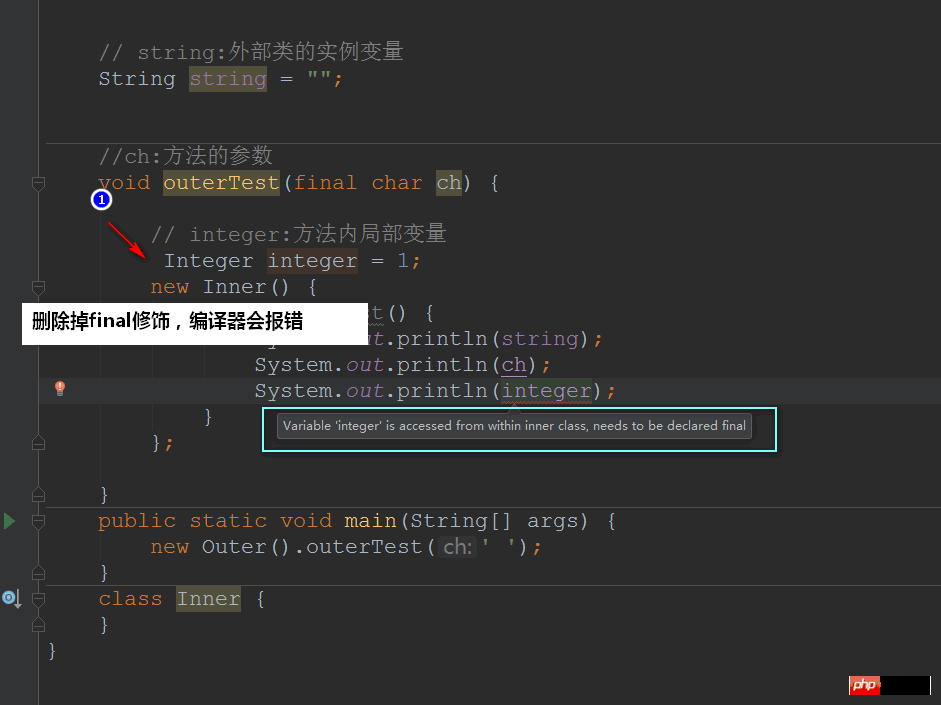
Wenn Sie zur jdk1.8-Kompilierungsumgebung wechseln, können Sie es kompilieren~
Lass uns darüber reden 1. Der Grund, warum die Erklärung endgültig ist, ist unten aufgeführt: Um die Konsistenz interner und externer Daten aufrechtzuerhalten
Java implementiert den Abschluss nur in Form einer Erfassung -by-value, der anonym ist. Die Funktion kopiert die freie Variable erneut, und dann gibt es zwei Kopien der Daten außerhalb der Funktion und innerhalb der Funktion.
Um interne und externe Datenkonsistenz zu erreichen, können wir nur verlangen, dass zwei Variablen unverändert bleiben. Vor JDK8 war die Verwendung der endgültigen Änderung erforderlich. JDK8 ist intelligenter. Sie können die endgültige Methode effektiv verwenden Eigenschaften externer Klassen nach Belieben
Die innere Klasse speichert eine
, die auf die Instanz der äußeren Klasse verweist. Über diese Referenz greift die innere Klasse auf die Mitgliedsvariablen der äußeren Klasse zu.
hat die referenzierten Daten in der inneren Klasse geändert, und die von der äußeren Klasse
und- erhaltenen Daten sind dieselben!
-
Wenn Sie dann versuchen, den Wert einer externen Basistypvariablen in einer anonymen inneren Klasse oder die Ausrichtung einer externen Referenzvariablen zu ändern,
auf der Oberfläche Scheint alles erfolgreich zu sein, aber
. Um zu verhindern, dass es so seltsam aussieht, hat Java daher diese letzte Einschränkung hinzugefügt. Referenz:
Warum sind die Parameterreferenzen anonymer innerer Klassen in Java endgültig? https://www.zhihu.com/question/21395848
- 1. Der Unterschied zwischen char und varchar
char hat eine feste Länge und varchar hat eine variable Länge. varchar:
Wenn der ursprüngliche Speicherort seinen Speicherbedarf nicht decken kann- , sind einige zusätzliche Vorgänge erforderlich. Abhängig von der Speicher-Engine verwenden einige den
- Split-Mechanismus
und andere Paging-Mechanismus.
char的存储方式是:英文字符占1个字节,汉字占用2个字节;varchar的存储方式是:英文和汉字都占用2个字节,两者的存储数据都非unicode的字符数据。
char是固定长度,长度不够的情况下,用空格代替。varchar表示的是实际长度的数据类型
选用考量:
如果字段长度较短和字符间长度相近甚至是相同的长度,会采用char字符类型
二、多个线程顺序打印问题
三个线程分别打印A,B,C,要求这三个线程一起运行,打印n次,输出形如“ABCABCABC....”的字符串。
原博主给出了4种方式,我认为信号量这种方式比较简单和容易理解,我这里粘贴一下(具体的可到原博主下学习)..
public class PrintABCUsingSemaphore {
private int times;
private Semaphore semaphoreA = new Semaphore(1);
private Semaphore semaphoreB = new Semaphore(0);
private Semaphore semaphoreC = new Semaphore(0);
public PrintABCUsingSemaphore(int times) {
this.times = times;
}
public static void main(String[] args) {
PrintABCUsingSemaphore printABC = new PrintABCUsingSemaphore(10);
// 非静态方法引用 x::toString 和() -> x.toString() 是等价的!
new Thread(printABC::printA).start();
new Thread(printABC::printB).start();
new Thread(printABC::printC).start();
/*new Thread(() -> printABC.printA()).start();
new Thread(() -> printABC.printB()).start();
new Thread(() -> printABC.printC()).start();
*/
}
public void printA() {
try {
print("A", semaphoreA, semaphoreB);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printB() {
try {
print("B", semaphoreB, semaphoreC);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printC() {
try {
print("C", semaphoreC, semaphoreA);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void print(String name, Semaphore current, Semaphore next)
throws InterruptedException {
for (int i = 0; i < times; i++) {
current.acquire();
System.out.print(name);
next.release();
}
}
}作者:cheergoivan
链接:https://www.jianshu.com/p/40078ed436b4
來源:简书
2018年9月14日18:15:36 yy笔试题就出了..
三、生产者和消费者
在不少的面经都能看到它的身影哈~~~基本都是要求能够手写代码的。
其实逻辑并不难,概括起来就两句话:
如果生产者的队列满了(while循环判断是否满),则等待。如果生产者的队列没满,则生产数据并唤醒消费者进行消费。
如果消费者的队列空了(while循环判断是否空),则等待。如果消费者的队列没空,则消费数据并唤醒生产者进行生产。
基于原作者的代码,我修改了部分并给上我认为合适的注释(下面附上了原作者出处,感兴趣的同学可到原文学习)
生产者:
import java.util.Random;
import java.util.Vector;
import java.util.concurrent.atomic.AtomicInteger;
public class Producer implements Runnable {
// true--->生产者一直执行,false--->停掉生产者
private volatile boolean isRunning = true;
// 公共资源
private final Vector sharedQueue;
// 公共资源的最大数量
private final int SIZE;
// 生产数据
private static AtomicInteger count = new AtomicInteger();
public Producer(Vector sharedQueue, int SIZE) {
this.sharedQueue = sharedQueue;
this.SIZE = SIZE;
}
@Override
public void run() {
int data;
Random r = new Random();
System.out.println("start producer id = " + Thread.currentThread().getId());
try {
while (isRunning) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列满时阻塞等待
while (sharedQueue.size() == SIZE) {
synchronized (sharedQueue) {
System.out.println("Queue is full, producer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不满时持续创造新元素
synchronized (sharedQueue) {
// 生产数据
data = count.incrementAndGet();
sharedQueue.add(data);
System.out.println("producer create data:" + data + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupted();
}
}
public void stop() {
isRunning = false;
}
}消费者:
import java.util.Random;
import java.util.Vector;
public class Consumer implements Runnable {
// 公共资源
private final Vector sharedQueue;
public Consumer(Vector sharedQueue) {
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
Random r = new Random();
System.out.println("start consumer id = " + Thread.currentThread().getId());
try {
while (true) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列空时阻塞等待
while (sharedQueue.isEmpty()) {
synchronized (sharedQueue) {
System.out.println("Queue is empty, consumer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不空时持续消费元素
synchronized (sharedQueue) {
System.out.println("consumer consume data:" + sharedQueue.remove(0) + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
}Main方法测试:
import java.util.Vector;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test2 {
public static void main(String[] args) throws InterruptedException {
// 1.构建内存缓冲区
Vector sharedQueue = new Vector();
int size = 4;
// 2.建立线程池和线程
ExecutorService service = Executors.newCachedThreadPool();
Producer prodThread1 = new Producer(sharedQueue, size);
Producer prodThread2 = new Producer(sharedQueue, size);
Producer prodThread3 = new Producer(sharedQueue, size);
Consumer consThread1 = new Consumer(sharedQueue);
Consumer consThread2 = new Consumer(sharedQueue);
Consumer consThread3 = new Consumer(sharedQueue);
service.execute(prodThread1);
service.execute(prodThread2);
service.execute(prodThread3);
service.execute(consThread1);
service.execute(consThread2);
service.execute(consThread3);
// 3.睡一会儿然后尝试停止生产者(结束循环)
Thread.sleep(10 * 1000);
prodThread1.stop();
prodThread2.stop();
prodThread3.stop();
// 4.再睡一会儿关闭线程池
Thread.sleep(3000);
// 5.shutdown()等待任务执行完才中断线程(因为消费者一直在运行的,所以会发现程序无法结束)
service.shutdown();
}
}作者:我没有三颗心脏
链接:https://www.jianshu.com/p/3f0cd7af370d
來源:简书
另外,上面原文中也说了可以使用阻塞队列来实现消费者和生产者。这就不用我们手动去写wait/notify的代码了,会简单一丢丢。可以参考:
使用阻塞队列解决生产者-消费者问题:https://www.cnblogs.com/chenpi/p/5553325.html
四、算法[1]
我现在需要实现一个栈,这个栈除了可以进行普通的push、pop操作以外,还可以进行getMin的操作,getMin方法被调用后,会返回当前栈的最小值,你会怎么做呢?你可以假设栈里面存的都是int整数
解决方案:
使用一个min变量来记住最小值,每次push的时候,看看是否需要更新min。
如果被pop出去的是min,第二次pop的时候,只能遍历一下栈内元素,重新找到最小值。
总结:pop的时间复杂度是O(n),push是O(1),空间是O(1)
使用辅助栈来存储最小值。如果当前要push的值比辅助栈的min值要小,那在辅助栈push的值是最小值
总结:push和pop的时间复杂度都是O(1),空间是O(n)。典型以空间换时间的例子。
import java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) {
data.add(num);
if (mins.size() == 0) {
// 初始化mins
mins.add(num);
} else {
// 辅助栈mins每次push当时最小值
int min = getMin();
if (num >= min) {
mins.add(min);
} else {
mins.add(num);
}
}
}
public int pop() {
// 栈空,异常,返回-1
if (data.size() == 0) {
return -1;
}
// pop时两栈同步pop
mins.remove(mins.size() - 1);
return data.remove(data.size() - 1);
}
public int getMin() {
// 栈空,异常,返回-1
if (mins.size() == 0) {
return -1;
}
// 返回mins栈顶元素
return mins.get(mins.size() - 1);
}
}继续优化:
栈为空的时候,返回-1很可能会带来歧义(万一人家push进去的值就有-1呢?),这边我们可以使用Java Exception来进行优化
算法的空间优化:上面的代码我们可以发现:data栈和mins栈的元素个数总是相等的,mins栈中存储几乎都是最小的值(此部分是重复的!)
所以我们可以这样做:当push的时候,如果比min栈的值要小的,才放进mins栈。同理,当pop的时候,如果pop的值是mins的最小值,mins才出栈,否则mins不出栈!
上述做法可以一定避免mins辅助栈有相同的元素!
但是,如果一直push的值是最小值,那我们的mins辅助栈还是会有大量的重复元素,此时我们可以使用索引(mins辅助栈存储的是最小值索引,非具体的值)!
最终代码:
import java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) throws Exception {
data.add(num);
if(mins.size() == 0) {
// 初始化mins
mins.add(0);
} else {
// 辅助栈mins push最小值的索引
int min = getMin();
if (num < min) {
mins.add(data.size() - 1);
}
}
}
public int pop() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// pop时先获取索引
int popIndex = data.size() - 1;
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
// 如果pop出去的索引就是最小值索引,mins才出栈
if(popIndex == minIndex) {
mins.remove(mins.size() - 1);
}
return data.remove(data.size() - 1);
}
public int getMin() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
return data.get(minIndex);
}
}参考资料:
[Interview Site] Wie implementiert man einen Stapel, der den Mindestwert erreichen kann?
Autor: channingbreeze Quelle: Internet Reconnaissance
5. HashMap unter Multithreading
Wie wir alle wissen, ist HashMap keine Thread-sichere Klasse. Während des Interviews werden Sie jedoch möglicherweise gefragt: Was passiert, wenn HashMap in einer Multithread-Umgebung verwendet wird? ?
Schlussfolgerung: Multithread-Dateninkonsistenz (Datenverlust), verursacht durch
put()resize()Die Der Vorgang führt zu einer zirkulären verknüpften Listejdk1.8 hat das Problem der zirkulären Kette gelöst (zwei Zeigerpaare deklarieren und zwei verknüpfte Listen verwalten)
Fail-Fast-Mechanismus, das gleichzeitige Löschen/Ändern der aktuellen HashMap löst eine ConcurrentModificationException-Ausnahme aus
Referenz:
Sprechen Sie über die Unsicherheit von HashMap-Threads: http://www.importnew.com/22011.html
Jdk1.8 Hashmap Multi-Threaded Put führt nicht zu einem Endlosschleife: https://blog.csdn.net/qq_27007251/article/details/71403647
6. Der Unterschied zwischen Spring und Springboot
1. SpringBoot kann unabhängige Spring-Anwendungen erstellen
2. Spring wird aufgrund seiner Umständlichkeit früher „Konfiguration“ genannt Konfiguration. „Hölle“, verschiedene XML- und Annotation-Konfigurationen sind umwerfend, und wenn etwas schief geht, ist es schwierig, den Grund herauszufinden.
-
Das Spring Boot-Projekt soll das Problem der langwierigen Konfiguration lösen und die Umsetzung von Konventionen über Konfigurationen (
Konventionen über Konfigurationen ) maximieren. -
Bietet eine Reihe von Abhängigkeitspaketen, um andere Aufgaben sofort verfügbar zu machen. Es verfügt über ein integriertes „Starter-POM“, das das Projekt stark kapselt Konstruktion.
, was die Konfiguration der Projektkonstruktion erheblich vereinfacht. 3. Eingebetteter Tomcat, Jetty-Container, keine Notwendigkeit, WAR-Paket bereitzustellen
G1 ist ein Kollektor mitGarbage Collector im Prozess der Speicherorganisation
,erzeugt nicht viele Speicherfragmente
.CMS verwendet einen Mark-and-Sweep-Garbage-Collection-Algorithmus, der viele Speicherfragmente erzeugen kann
- Vorhersagemechanismus
zur Pausenzeit hinzu, und Benutzer können
die erwartete Pausenzeit angeben . -
Erweiterte Lektüre:
Einführung in den G1 Garbage Collector: https://javadoop.com/post/g1
- G1 Stop The World (STW) ist besser kontrollierbar. G1 fügt einen
- 8. Massive-Data-Lösungen
Bloom-Filter Bloom-Filter
- Anwendbarer Geltungsbereich: Kann verwendet werden, um ein Datenwörterbuch zu implementieren, eine Datengewichtungsbeurteilung durchzuführen oder einen Schnittpunkt festzulegen
-
Anwendungsbereich: Große Datenmenge, viele Wiederholungen, aber kleine Datentypen können im Speicher abgelegt werden
Verteilte Verarbeitung Mapreduce
Anwendungsbereich: Große Datenmengen, aber kleine Datentypen können im Speicher abgelegt werden
Eine Zusammenfassung von zehn Interviewfragen zur Massendatenverarbeitung und zehn Methoden: https://blog.csdn.net/v_JULY_v/article/details/ 6279498
Was ist der Unterschied zwischen GET und POST? Und warum die meisten Antworten im Internet falsch sind. http://www.cnblogs.com/nankezhishi/archive/2012/06/09/getandpost.html
Hier ist eine kurze Erklärung der Bedeutung von „Nebenwirkungen“: Dies bedeutet, dass nach dem Senden einer Anfrage der Ressourcenstatus auf der Website nicht geändert wurde, das heißt, die Anfrage wird berücksichtigt. Es hat keine Nebenwirkungen.
GETist idempotent und hat keine NebenwirkungenZum Beispiel möchte ich die Bestellung mit der Bestell-ID 2 erhalten:
http://localhost/order/2, verwenden SieGET, um mehrfach, diese Bestellung mit der ID 2 (Ressource) ist keine Änderungen vorbehalten!ist idempotent und hat Nebenwirkungen
DELETE/PUT- Zum Beispiel möchte ich die ID löschen oder aktualisieren zu 2 Bestellung:
, verwenden Sie
http://localhost/order/2PUT/DELETE, um mehrmals anzufordern, diese Bestellung (Ressource) mit ID 2 ändert sich nur einmal (es hat Nebenwirkungen)! Wenn Sie die Anforderung jedoch mehrmals aktualisieren, ist der endgültige Status von Bestell-ID 2 konsistent. ist nicht idempotent und hat Nebenwirkungen.
POST- Wenn ich beispielsweise eine Bestellung mit dem Namen 3y erstellen möchte:
, verwenden Sie
http://localhost/order, um mehrere Male anzufordern 🎜> kann erstellt werden. Die Bestellung mit dem Namen 3yPOST, diese Bestellung (Ressource) wird sich mehrmals ändern, der angeforderte Ressourcenstatus ändert sich jedes Mal ! - Shallow Sprechen über den Unterschied zwischen Get und Post in HTTP http://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
- POST- und GET-Anfragen in HTTP-Anfragen Der Unterschied? https://www.zhihu.com/question/27622127/answer/37676304
3y musste als Erstsemester Sportunterricht nehmen, das Klassensystem der Schule jedoch schon Schrecklich (sehr hohe Latenz). Ich wollte an dem Kurs teilnehmen, also habe ich mehr als 10 Chrome-Tabs geöffnet, um ihn zu nutzen (selbst wenn ein Chrome-Tab abstürzte, hatte ich immer noch einen anderen Chrome-Tab zur Verfügung). Ich möchte mir einen Tischtennisball oder einen Badmintonball schnappen.
Wenn es an der Zeit ist, den Kurs zu ergattern, klicke ich abwechselnd auf die Tischtennisplatte oder das Badminton, die ich mir schnappen möchte. Wenn das System nicht gut konzipiert ist, die Anfrage nicht idempotent ist (oder die Transaktion nicht gut kontrolliert wird) und meine Handgeschwindigkeit schnell genug und das Netzwerk gut genug ist, dann habe ich möglicherweise mehrere Tischtennis- oder Badmintonstunden genommen. (Das ist unzumutbar. Eine Person kann nur einen Kurs auswählen, aber ich habe mehrere oder wiederholte Kurse belegt)
Anwendungsszenarien im Zusammenhang mit dem Einkaufszentrum können sein: Der Benutzer hat mehrere doppelte Bestellungen aufgegeben
- Es wird höchstens ein Datensatz im Datenbankhintergrund vorhanden sein, sodass nicht mehrere Kurse belegt werden müssen.
- Synchronisationssperre (einzelner Thread, kann in einem Cluster fehlschlagen)
- Verteilte Sperren wie Redis (komplexe Implementierung)
- Geschäftsfelder plus eindeutige Einschränkungen (einfach)
Token-Tabelle + eindeutige Einschränkung (einfache Empfehlung)---->Eine Möglichkeit, eine idempotente Schnittstelle zu implementieren
- MySQL-Einfügung ignorieren oder bei doppelter Schlüsselaktualisierung (einfach)
- Gemeinsame Sperre + normaler Index (einfach)
- MQ- oder Redis-Erweiterung (Warteschlangen) verwenden
- Andere Lösungen wie die Multiversionskontrolle, MVCC, optimistische Sperre, pessimistische Sperrzustandsmaschine usw. .
- Verteilte Systemschnittstelle idempotence http://blog.brucefeng.info/post/api-idempotent
- So vermeiden Sie doppelte Bestellungen https://www.jianshu.com/p/e618cc818432
- Zusammenfassung zur Schnittstellen-Idempotenz https://www.jianshu. com/p/6eba27f8fb03
- Verwendung eindeutiger Datenbankschlüssel zur Erzielung von Transaktionsidempotenz http://www.caosh.me/be-tech/idempotence-using- unique-key/
- Nicht-idempotente Probleme mit der API-Schnittstelle und Verwendung von Redis zur Implementierung einfacher verteilter Sperren https://blog.csdn.net/rariki/article/details/50783819
- Hashing
- Bitmap
- Heap
- Doppelschichtige Eimerteilung- ---Tatsächlich handelt es sich im Wesentlichen um die Idee von [Teile und herrsche], wobei der Schwerpunkt auf der Technik des „Teilens“ liegt!
- Datenbankindex
- Invertierter Index (Invertierter Index)
- Externe Sortierung
- Trie-Baum
Für Einzelheiten finden Sie im Originaltext:
9. Idempotenz
9.1 HTTP-Idempotenz
Gestern habe ich eine Reihe schriftlicher Testfragen gestellt, um den Unterschied zwischen get/post im klassischen HTTP zu beleuchten. Ich habe heute noch einmal gesucht und festgestellt, dass es sich ein wenig von meinem vorherigen Verständnis unterscheidet.
Wenn jemand von Anfang an Webentwicklung betreibt, wird er wahrscheinlich die Verwendung des HTTP-Protokolls durch HTML als die einzig sinnvolle Verwendung des HTTP-Protokolls betrachten. Deshalb haben wir den Fehler gemacht,
zu verallgemeinern. Aus der HTTP-Protokollspezifikation können die GET/POST Unterschiede, die wir zuvor zusammengefasst haben, möglicherweise nutzlos sein. (Aber nachdem ich den gesamten Artikel gelesen habe, denke ich persönlich : Wenn es einen GET/POST Unterschied im Interview gibt, ist es besser, standardmäßig im Webentwicklungsszenario zu antworten. Dies könnte die Antwort des Interviewers sein will)
Referenz:
Ich habe auch das Konzept der Idempotenz gelernt, also habe ich es auch versucht. Machen Sie sich Notizen ~~~
Methoden können auch die Eigenschaft der „Idempotenz“ haben, da (abgesehen von Fehler- oder Ablaufproblemen) die Nebenwirkungen von N > 0 identischen Anforderungen die gleichen sind wie bei einer einzelnen Anforderung.
Per Definition ist die Idempotenz von HTTP-Methoden , was bedeutet, dass eine und mehrere Anfragen für eine Ressource die gleichen Nebenwirkungen haben sollten .
HTTPs GET/POST/DELETE/PUT-Methode ist idempotent:
Das HTTP-Protokoll selbst ist ein
ressourcenorientiertes Anwendungsschichtprotokoll, aber die eigentliche Verwendung des HTTP-Protokolls Es gibt zwei verschiedene Methoden: Die eine ist RESTful, die HTTP als Protokoll der Anwendungsschicht behandelt und die verschiedenen Vorschriften des HTTP-Protokolls besser einhält ( nutzt die HTTP-Methoden vollständig aus ). ; Ein weiteres ist SOAs , das HTTP nicht vollständig als Anwendungsschichtprotokoll betrachtet, sondern das HTTP-Protokoll als Transportschichtprotokoll verwendet und dann eine eigene Anwendung auf dem HTTP-Schichtprotokoll aufbaut Referenz:
- HTTP-Idempotenz verstehen http://www.cnblogs.com/weidagang2046/archive/2011/06/04/2063696. html#!comments
9.2 Schnittstellen-Idempotenz Wenn Sie die Informationen überprüfen, können Sie feststellen, dass viele Blogs über die Idempotenz von Schnittstellen sprechen. Aus dem oben Gesagten können wir auch ersehen, dass die Methode Nachdem ich so viel gesagt habe: Welche Vorteile hat es, eine Schnittstelle so zu gestalten, dass sie idempotent ist? ? ? ? Nehmen wir ein Beispiel für die Nachteile der Nicht-Idempotenz: Wenn meine Class-Grabbing-Schnittstelle idempotent wäre, würde dieses Problem nicht auftreten. Denn Idempotenz bedeutet, dass mehrere Anfragen für eine Ressource die gleichen Nebenwirkungen haben sollten. wiederholte Übermittlungen zu verhindern (mehrere doppelte Daten in der Datenbank)! POST nicht idempotent ist. Aber wir können einige Mittel nutzen, um die Schnittstelle der POST-Methode idempotent zu machen.
Um es ganz klar auszudrücken: Der Zweck des Entwurfs idempotenter Schnittstellen besteht darin,
Referenz:
AbschließendWenn mit dem oben Gesagten etwas nicht stimmt oder es einen besseren Weg gibt, es zu verstehen, hoffe ich, dass Sie nicht zögern, eine Nachricht im Kommentarbereich zu hinterlassen. Gemeinsam vorankommen!
Das obige ist der detaillierte Inhalt vonAnalyse mehrerer häufiger Java-Interviewfragen für die Personalbeschaffung im Herbst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!