
Heim >Backend-Entwicklung >Python-Tutorial >Beispiel für einen Python3-Crawler: NetEase Cloud-Musik-Crawler
Beispiel für einen Python3-Crawler: NetEase Cloud-Musik-Crawler

- 青灯夜游nach vorne
- 2018-10-23 16:35:154267Durchsuche
Dieser Artikel stellt Ihnen das NetEase Cloud Music Crawler-Beispiel eines Python3-Crawlers vor. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird Ihnen hilfreich sein.
Das Ziel dieses Mal ist es, alle Kommentare zum angegebenen Song auf NetEase Cloud Music zu crawlen und eine Wortwolke zu generieren
Spezifische Schritte:
1: JS-Verschlüsselung implementieren
Es ist nicht schwierig, diese Ajax-Schnittstelle zu finden. Das Problem besteht darin, dass die übergebenen Daten durch JS-Verschlüsselung abgerufen werden der js-code.
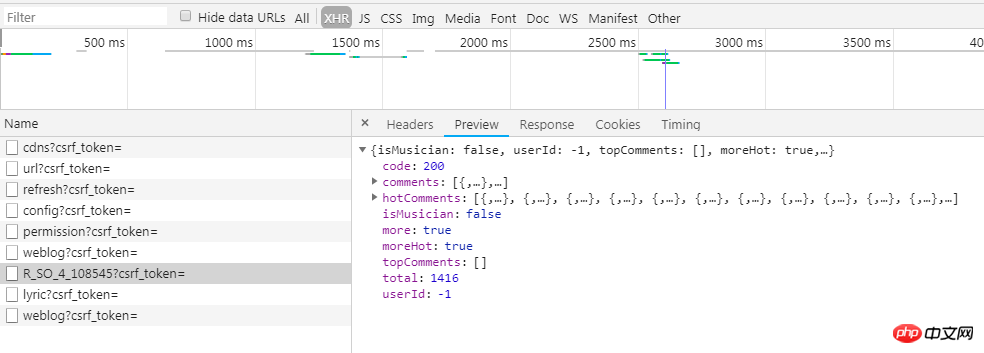
Wenn Sie das Debuggen abbrechen, können Sie feststellen, dass die Daten durch die Funktion window.asrsea in core_8556f33641851a422ec534e33e6fa5a4.js?8556f33641851a422ec534e33e6fa5a4.js verschlüsselt werden.

Durch weitere Suche können Sie die folgende Funktion finden:
function() {
// 生成长度为16的随机字符串
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
// 实现AES加密
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
// 实现RSA加密
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
// 得到加密后的结果
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
}()
Wir müssen also Python verwenden, um die oben genannten vier Funktionen zu implementieren. Die erste Funktion zum Generieren einer Zufallszeichenfolge ist nicht schwierig. Der implementierte Code lautet wie folgt:
# 生成随机字符串
def generate_random_string(length):
string = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
# 初始化随机字符串
random_string = ""
# 生成一个长度为length的随机字符串
for i in range(length):
random_string += string[int(floor(random() * len(string)))]
return random_stringDie zweite Funktion ist eine Funktion zum Implementieren der AES-Verschlüsselung, und die Verwendung der AES-Verschlüsselung erfordert die Verwendung der Crypto-Bibliothek. Wenn diese Bibliothek nicht installiert ist, müssen Sie zuerst die Pycrypto-Bibliothek und dann die Crypto-Bibliothek installieren. Nach erfolgreicher Installation: Wenn beim Importieren kein Crypto, sondern nur Crypto vorhanden ist, öffnen Sie zunächst den Ordner Libsite-packagescrypto im Python-Installationsverzeichnis. Wenn sich darin ein Cipher-Ordner befindet, kehren Sie zu Libsite- zurück. Benennen Sie die Pakete im Verzeichnis crypto in Crypto um, und dann sollte es erfolgreich importiert werden.
Da die Länge des AES-verschlüsselten Klartexts ein Vielfaches von 16 sein muss, müssen wir die erforderliche Auffüllung des Klartexts durchführen, um sicherzustellen, dass seine Länge ein Vielfaches von 16 ist. Der Modus der AES-Verschlüsselung ist AES.MODE_CBC. Initialisierungsvektor iv ='0102030405060708′.
Der Code zur Implementierung der AES-Verschlüsselung lautet wie folgt:
# AES加密
def aes_encrypt(msg, key):
# 如果不是16的倍数则进行填充
padding = 16 - len(msg) % 16
# 这里使用padding对应的单字符进行填充
msg += padding * chr(padding)
# 用来加密或者解密的初始向量(必须是16位)
iv = '0102030405060708'
# AES加密
cipher = AES.new(key, AES.MODE_CBC, iv)
# 加密后得到的是bytes类型的数据
encrypt_bytes = cipher.encrypt(msg)
# 使用Base64进行编码,返回byte字符串
encode_string = base64.b64encode(encrypt_bytes)
# 对byte字符串按utf-8进行解码
encrypt_text = encode_string.decode('utf-8')
# 返回结果
return encrypt_textDer dritte ist die Funktion zur Implementierung der RSA-Verschlüsselung, Bei der RSA-Verschlüsselung sind sowohl Klartext als auch Chiffretext Zahlen, Der Chiffretext von RSA ist das Ergebnis mod N der E-Potenz der Zahl, die den Klartext darstellt Die Länge der nach der RSA-Verschlüsselung erhaltenen Zeichenfolge beträgt 256. Sie ist nicht lang genug und wir füllen sie mit x Zeichen.
Der Code zum Implementieren der RSA-Verschlüsselung lautet wie folgt:
# RSA加密
def rsa_encrypt(random_string, key, f):
# 随机字符串逆序排列
string = random_string[::-1]
# 将随机字符串转换成byte类型数据
text = bytes(string, 'utf-8')
# RSA加密
sec_key = int(codecs.encode(text, encoding='hex'), 16) ** int(key, 16) % int(f, 16)
# 返回结果
return format(sec_key, 'x').zfill(256)Die vierte Funktion ist eine Funktion, die zwei Verschlüsselungsparameter abruft. Die vier übergebenen Parameter sind der erste Parameter JSON.stringify (i3x) ist der folgende Inhalt, bei dem die Offset- und Limit-Parameter erforderlich sind. Der Wert des Offsets beträgt (Anzahl der Seiten-1)*20 und der Wert des Limits beträgt 20
'{"offset":'+str(offset)+',"total":"True","limit":"20","csrf_token":""}'Der zweiter Parameter, die Werte des dritten und vierten Parameters werden basierend auf Zj4n.emj erhalten:

Der Wert von encText wird über AES übergeben Zweimal verschlüsselt, encSecKey wird durch RSA-Verschlüsselung erhalten, und der spezifische Code für die Implementierung lautet wie folgt:
# 获取参数
def get_params(page):
# 偏移量
offset = (page - 1) * 20
# offset和limit是必选参数,其他参数是可选的
msg = '{"offset":' + str(offset) + ',"total":"True","limit":"20","csrf_token":""}'
key = '0CoJUm6Qyw8W8jud'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a87' \
'6aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9' \
'd05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b' \
'8e289dc6935b3ece0462db0a22b8e7'
e = '010001'
# 生成长度为16的随机字符串
i = generate_random_string(16)
# 第一次AES加密
enc_text = aes_encrypt(msg, key)
# 第二次AES加密之后得到params的值
encText = aes_encrypt(enc_text, i)
# RSA加密之后得到encSecKey的值
encSecKey = rsa_encrypt(i, e, f)
return encText, encSecKey 2. Analysieren und speichern Sie Kommentare
Sie können es herausfinden Anzeigen der Vorschauinformationen Der Benutzername und der Kommentarinhalt werden in Daten im JSON-Format

gespeichert, so dass die Analyse einfach ist. Extrahieren Sie einfach den Spitznamen und den Inhalt direkt. Die erhaltenen Daten werden in einer TXT-Datei mit dem Dateinamen des Songs gespeichert. Der implementierte Code lautet wie folgt:
# 爬取评论内容
def get_comments(data):
# data=[song_id,song_name,page_num]
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_' + str(data[0]) + '?csrf_token='
# 得到两个加密参数
text, key = get_params(data[2])
# 发送post请求
res = requests.post(url, headers=headers, data={"params": text, "encSecKey": key})
if res.status_code == 200:
print("正在爬取第{}页的评论".format(data[2]))
# 解析
comments = res.json()['comments']
# 存储
with open(data[1] + '.txt', 'a', encoding="utf-8") as f:
for i in comments:
f.write(i['content'] + "\n")
else:
print("爬取失败!")3. Wortwolke generieren
Bevor Sie mit diesem Schritt fortfahren, müssen Sie die Module „jieba“ und „wordcloud“ installieren. Das Modul „jieba“ wird für Chinesisch verwendet Wortsegmentierung, das Wordcloud-Modul ist ein Modul zum Generieren von Wortwolken, das Sie selbst erlernen können.
Ich werde nicht näher auf diesen Teil eingehen. Der spezifische Code lautet wie folgt:
# 生成词云 def make_cloud(txt_name): with open(txt_name + ".txt", 'r', encoding="utf-8") as f: txt = f.read() # 结巴分词 text = ''.join(jieba.cut(txt)) # 定义一个词云 wc = WordCloud( font_path="font.ttf", width=1200, height=800, max_words=100, max_font_size=200, min_font_size=10 ) # 生成词云 wc.generate(text) # 保存为图片 wc.to_file(txt_name + ".png")
Der vollständige Code wurde auf Github hochgeladen (einschließlich der Datei „font.ttf“): https:/ /github.com/QAQ112233/WangYiYun
Das obige ist der detaillierte Inhalt vonBeispiel für einen Python3-Crawler: NetEase Cloud-Musik-Crawler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!