
Heim >Java >javaLernprogramm >Wie löst man eine hohe Parallelität in Java? Java-Lösung mit hoher Parallelität
Wie löst man eine hohe Parallelität in Java? Java-Lösung mit hoher Parallelität

- 不言nach vorne
- 2018-10-10 11:16:573085Durchsuche
Der Inhalt dieses Artikels befasst sich mit der Frage, wie hohe Parallelität in Java gelöst werden kann. Die Java-Lösung für hohe Parallelität hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen.
Wenn die Website, die wir entwickeln, eine sehr große Anzahl von Besuchen hat, müssen wir damit verbundene Probleme beim gleichzeitigen Zugriff berücksichtigen. Parallelitätsprobleme bereiten den meisten Programmierern Kopfzerbrechen.
Aber da wir ihnen nicht entkommen können, lassen Sie uns die Sache ruhig angehen ~ Lassen Sie uns heute gemeinsam die häufigsten Probleme untersuchen. Parallelität und Synchronisation.
Um Parallelität und Synchronisation besser zu verstehen, müssen wir zunächst zwei wichtige Konzepte verstehen: Synchronisation und Asynchronität
1. Der Unterschied zwischen Synchronisation und Asynchronität und Kontakt
Die sogenannte Synchronisation kann als Warten darauf verstanden werden, dass das System nach Ausführung einer Funktion oder Methode einen Wert oder eine Nachricht zurückgibt. Zu diesem Zeitpunkt ist das Programm blockiert und empfängt nur
Führen Sie andere Befehle erst aus, nachdem Sie den Wert oder die Nachricht zurückgegeben haben.
Asynchron: Nach der Ausführung der Funktion oder Methode muss nicht blockiert werden, bis der Rückgabewert oder die Rückgabenachricht vorliegt. Sie müssen lediglich einen asynchronen Prozess an das System delegieren Nachricht, das System löst automatisch den asynchronen Delegationsprozess aus, um einen vollständigen Prozess abzuschließen.
Die Synchronisierung kann bis zu einem gewissen Grad als ein einzelner Thread betrachtet werden. Nachdem dieser Thread eine Methode angefordert hat, wartet er darauf, dass die Methode darauf antwortet, andernfalls wird die Ausführung nicht fortgesetzt (tot).
Asynchron kann bis zu einem gewissen Grad als Multithreading angesehen werden (Unsinn, wie kann ein Thread als asynchron bezeichnet werden? Nach der Anforderung einer Methode wird er ignoriert und führt weiterhin andere Methoden aus).
Synchronisierung ist eine Sache, die einzeln durchgeführt wird.
Asynchron bedeutet, eine Sache zu tun, ohne dass andere Dinge erledigt werden.
Zum Beispiel:
Essen und Sprechen können immer nur einzeln stattfinden, da es nur einen Mund gibt. Aber Essen und Musikhören sind asynchron, denn Musikhören veranlasst uns nicht zum Essen.
Für Java-Programmierer hören wir oft das Synchronisationsschlüsselwort „synced“. Wenn das Synchronisationsüberwachungsobjekt eine Klasse ist, dann können andere Objekte, wenn sie auf die Synchronisationsmethode in der Klasse zugreifen, weiterhin darauf zugreifen Die Synchronisationsmethode in der Klasse wird blockiert. Erst nachdem das vorherige Objekt die Ausführung der Synchronisationsmethode abgeschlossen hat, kann das aktuelle Objekt die Methode weiter ausführen. Das ist Synchronisation. Im Gegenteil, wenn vor der Methode keine Änderung des Synchronisierungsschlüsselworts erfolgt, können verschiedene Objekte gleichzeitig auf dieselbe Methode zugreifen, was asynchron ist.
Zusätzlich (verwandte Konzepte von Dirty Data und nicht wiederholbaren Lesevorgängen):
Dirty Data
Dirty Reading bedeutet, dass bei einer Transaktion auf Daten zugegriffen und Vorgänge ausgeführt werden data Die Änderung wurde noch nicht an die Datenbank übermittelt. Zu diesem Zeitpunkt greift auch eine andere Transaktion auf die Daten zu und verwendet sie dann. Da diese Daten noch nicht festgeschrieben wurden, handelt es sich bei den von einer anderen Transaktion gelesenen Daten um fehlerhafte Daten, und auf fehlerhaften Daten basierende Vorgänge können fehlerhaft sein.
Nicht wiederholbares Lesen
Nicht wiederholbares Lesen bezieht sich auf das mehrmalige Lesen derselben Daten innerhalb einer Transaktion. Bevor diese Transaktion endet, greift auch eine andere Transaktion auf dieselben Daten zu. Dann können zwischen den beiden Datenlesevorgängen in der ersten Transaktion aufgrund der Änderung der zweiten Transaktion die von der ersten Transaktion zweimal gelesenen Daten unterschiedlich sein. Auf diese Weise sind die innerhalb einer Transaktion zweimal gelesenen Daten unterschiedlich, daher spricht man von nicht wiederholbarem Lesen
2. Umgang mit Parallelität und Synchronisation
Heute besprechen wir das Wie Die Bewältigung von Parallelitäts- und Synchronisationsproblemen erfolgt hauptsächlich über den Sperrmechanismus.
Wir müssen verstehen, dass der Verriegelungsmechanismus zwei Ebenen hat.
Eines ist auf der Codeebene, wie zum Beispiel die Synchronisationssperre in Java. Ich werde hier nicht zu viel erklären.
Das andere ist auf der Datenbankebene. Die typischeren sind pessimistisches Locking und optimistisches Locking. Wir konzentrieren uns hier auf pessimistisches Sperren (traditionelles physisches Sperren) und optimistisches Sperren.
pessimistische Sperre:pessimistische Sperre, wie der Name schon sagt, bezieht sie sich auf die Änderung der Daten (einschließlich anderer aktueller Transaktionen in diesem System und der Transaktionsverarbeitung von externen Systemen). Die Daten werden während des gesamten Datenverarbeitungsvorgangs gesperrt. Die Implementierung pessimistischer Sperren basiert häufig auf dem von der Datenbank bereitgestellten Sperrmechanismus (nur der von der Datenbankschicht bereitgestellte Sperrmechanismus kann die Exklusivität des Datenzugriffs wirklich garantieren. Andernfalls, selbst wenn der Sperrmechanismus implementiert ist Dieses System kann nicht sicherstellen, dass externe Systeme die Daten nicht ändern. Ein typischer pessimistischer Sperraufruf, der auf der Datenbank basiert:
select * from account where name=”Erica” for updateDiese SQL-Anweisung sperrt alle Datensätze in der Kontotabelle, die die Abrufbedingungen erfüllen (name="Erica").
本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。
Hibernate 的悲观锁,也是基于数据库的锁机制实现。
下面的代码实现了对查询记录的加锁:
String hqlStr ="from TUser as user where user.name='Erica'";
Query query = session.createQuery(hqlStr);
query.setLockMode("user",LockMode.UPGRADE); // 加锁
List userList = query.list();// 执行查询,获取数据query.setLockMode 对查询语句中,特定别名所对应的记录进行加锁(我们为 TUser 类指定了一个别名 “user” ),这里也就是对返回的所有 user 记录进行加锁。
观察运行期 Hibernate 生成的 SQL 语句:
select tuser0_.id as id, tuser0_.name as name, tuser0_.group_id as group_id, tuser0_.user_type as user_type, tuser0_.sex as sex from t_user tuser0_ where (tuser0_.name='Erica' ) for update
这里 Hibernate 通过使用数据库的 for update 子句实现了悲观锁机制。
Hibernate 的加锁模式有:
? LockMode.NONE : 无锁机制。
? LockMode.WRITE : Hibernate 在 Insert 和 Update 记录的时候会自动获取
? LockMode.READ : Hibernate 在读取记录的时候会自动获取。
以上这三种锁机制一般由 Hibernate 内部使用,如 Hibernate 为了保证 Update
过程中对象不会被外界修改,会在 save 方法实现中自动为目标对象加上 WRITE 锁。
? LockMode.UPGRADE :利用数据库的 for update 子句加锁。
? LockMode. UPGRADE_NOWAIT : Oracle 的特定实现,利用 Oracle 的 for
update nowait 子句实现加锁。
上面这两种锁机制是我们在应用层较为常用的,加锁一般通过以下方法实现:
Criteria.setLockMode
Query.setLockMode
Session.lock
注意,只有在查询开始之前(也就是 Hiberate 生成 SQL 之前)设定加锁,才会 真正通过数据库的锁机制进行加锁处理,否则,数据已经通过不包含 for update子句的 Select SQL 加载进来,所谓数据库加锁也就无从谈起。
为了更好的理解select... for update的锁表的过程,本人将要以mysql为例,进行相应的讲解
1、要测试锁定的状况,可以利用MySQL的Command Mode ,开二个视窗来做测试。
表的基本结构如下:
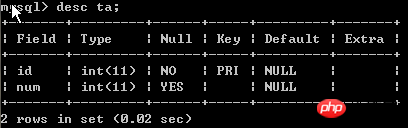
表中内容如下:
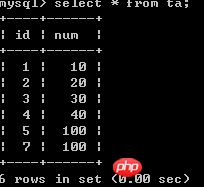
开启两个测试窗口,在其中一个窗口执行select * from ta for update0
然后在另外一个窗口执行update操作如下图:

等到一个窗口commit后的图片如下:

到这里,悲观锁机制你应该了解一些了吧~
需要注意的是for update要放到mysql的事务中,即begin和commit中,否者不起作用。
至于是锁住整个表还是锁住选中的行。
至于hibernate中的悲观锁使用起来比较简单,这里就不写demo了~感兴趣的自己查一下就ok了~
乐观锁(Optimistic Locking):
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依 靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库 性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。 如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进 行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过 程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作 员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几 百上千个并发,这样的情况将导致怎样的后果。 乐观锁机制在一定程度上解决了这个问题。
乐观锁,大多是基于数据版本 Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来 实现。 读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提 交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据 版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。对于上面修改用户帐户信息的例子而言,假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。 2 在操作员 A 操作的过程中,操作员 B 也读入此用户信息( version=1 ),并 从其帐户余额中扣除 $20 ( $100-$20 )。 3 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣 除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大 于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。 4 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数 据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的 数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记 录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。 这样,就避免了操作员 B 用基于version=1 的旧数据修改的结果覆盖操作 员 A 的操作结果的可能。 从上面的例子可以看出,乐观锁机制避免了长事务中的数据库加锁开销(操作员 A和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系 统整体性能表现。 需要注意的是,乐观锁机制往往基于系统中的数据存储逻辑,因此也具备一定的局 限性,如在上例中,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户 余额更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在 系统设计阶段,我们应该充分考虑到这些情况出现的可能性,并进行相应调整(如 将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途 径,而不是将数据库表直接对外公开)。 Hibernate 在其数据访问引擎中内置了乐观锁实现。如果不用考虑外部系统对数 据库的更新操作,利用 Hibernate 提供的透明化乐观锁实现,将大大提升我们的 生产力。
User.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.xiaohao.test">
<class name="User" table="user" optimistic-lock="version" >
<id name="id">
<generator class="native" />
</id>
<!--version标签必须跟在id标签后面-->
<version column="version" name="version" />
<property name="userName"/>
<property name="password"/>
</class>
</hibernate-mapping>注意 version 节点必须出现在 ID 节点之后。
这里我们声明了一个 version 属性,用于存放用户的版本信息,保存在 User 表的version中
optimistic-lock 属性有如下可选取值:
? none无乐观锁
? version通过版本机制实现乐观锁
? dirty通过检查发生变动过的属性实现乐观锁
? all通过检查所有属性实现乐观锁
其中通过 version 实现的乐观锁机制是 Hibernate 官方推荐的乐观锁实现,同时也 是 Hibernate 中,目前唯一在数据对象脱离 Session 发生修改的情况下依然有效的锁机 制。因此,一般情况下,我们都选择 version 方式作为 Hibernate 乐观锁实现机制。
2 、配置文件hibernate.cfg.xml和UserTest测试类
hibernate.cfg.xml
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 指定数据库方言 如果使用jbpm的话,数据库方言只能是InnoDB-->
<property name="dialect">org.hibernate.dialect.MySQL5InnoDBDialect</property>
<!-- 根据需要自动创建数据表 -->
<property name="hbm2ddl.auto">update</property>
<!-- 显示Hibernate持久化操作所生成的SQL -->
<property name="show_sql">true</property>
<!-- 将SQL脚本进行格式化后再输出 -->
<property name="format_sql">false</property>
<property name="current_session_context_class">thread</property>
<!-- 导入映射配置 -->
<property name="connection.url">jdbc:mysql:///user</property>
<property name="connection.username">root</property>
<property name="connection.password">123456</property>
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<mapping resource="com/xiaohao/test/User.hbm.xml" />
</session-factory>
</hibernate-configuration>UserTest.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest {
public static void main(String[] args) {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.getCurrentSession();
Transaction tx=session.beginTransaction();
// User user=new User("小浩","英雄");
// session.save(user);
// session.createSQLQuery("insert into user(userName,password) value('张英雄16','123')")
// .executeUpdate();
User user=(User) session.get(User.class, 1);
user.setUserName("221");
// session.save(user);
System.out.println("恭喜您,用户的数据插入成功了哦~~");
tx.commit();
}
}每次对 TUser 进行更新的时候,我们可以发现,数据库中的 version 都在递增。
下面我们将要通过乐观锁来实现一下并发和同步的测试用例:
这里需要使用两个测试类,分别运行在不同的虚拟机上面,以此来模拟多个用户同时操作一张表,同时其中一个测试类需要模拟长事务
UserTest.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest {
public static void main(String[] args) {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.openSession();
// Session session2=sf.openSession();
User user=(User) session.createQuery(" from User user where user=5").uniqueResult();
// User user2=(User) session.createQuery(" from User user where user=5").uniqueResult();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
Transaction tx=session.beginTransaction();
user.setUserName("101");
tx.commit();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
// System.out.println(user.getVersion()==user2.getVersion());
// Transaction tx2=session2.beginTransaction();
// user2.setUserName("4468");
// tx2.commit();
}
}UserTest2.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest2 {
public static void main(String[] args) throws InterruptedException {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.openSession();
// Session session2=sf.openSession();
User user=(User) session.createQuery(" from User user where user=5").uniqueResult();
Thread.sleep(10000);
// User user2=(User) session.createQuery(" from User user where user=5").uniqueResult();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
Transaction tx=session.beginTransaction();
user.setUserName("100");
tx.commit();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
// System.out.println(user.getVersion()==user2.getVersion());
// Transaction tx2=session2.beginTransaction();
// user2.setUserName("4468");
// tx2.commit();
}
}操作流程及简单讲解: 首先启动UserTest2.java测试类,在执行到Thread.sleep(10000);这条语句的时候,当前线程会进入睡眠状态。在10秒钟之内启动UserTest这个类,在到达10秒的时候,我们将会在UserTest.java中抛出下面的异常:
Exception in thread "main" org.hibernate.StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [com.xiaohao.test.User#5]
at org.hibernate.persister.entity.AbstractEntityPersister.check(AbstractEntityPersister.java:1932)
at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:2576)
at org.hibernate.persister.entity.AbstractEntityPersister.updateOrInsert(AbstractEntityPersister.java:2476)
at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:2803)
at org.hibernate.action.EntityUpdateAction.execute(EntityUpdateAction.java:113)
at org.hibernate.engine.ActionQueue.execute(ActionQueue.java:273)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:265)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:185)
at org.hibernate.event.def.AbstractFlushingEventListener.performExecutions(AbstractFlushingEventListener.java:321)
at org.hibernate.event.def.DefaultFlushEventListener.onFlush(DefaultFlushEventListener.java:51)
at org.hibernate.impl.SessionImpl.flush(SessionImpl.java:1216)
at org.hibernate.impl.SessionImpl.managedFlush(SessionImpl.java:383)
at org.hibernate.transaction.JDBCTransaction.commit(JDBCTransaction.java:133)
at com.xiaohao.test.UserTest2.main(UserTest2.java:21)UserTest2代码将在 tx.commit() 处抛出 StaleObjectStateException 异 常,并指出版本检查失败,当前事务正在试图提交一个过期数据。通过捕捉这个异常,我 们就可以在乐观锁校验失败时进行相应处理
3. Analyse häufiger gleichzeitiger Synchronisierungsfälle
Fall 1: Buchungssystemfall Es gibt nur ein Ticket für einen bestimmten Flug. Gehen Sie davon aus, dass 10.000 Personen Ihre Website öffnen, um Tickets zu buchen . Fragen Sie, wie Sie das Parallelitätsproblem lösen können (kann auf jede Website mit hoher Parallelität ausgeweitet werden, um gleichzeitige Lese- und Schreibprobleme zu berücksichtigen)
Problem, 10.000 Personen kommen zu Besuch, bevor das Ticket freigegeben wird, müssen Sie sicherstellen dass jeder sehen kann, dass es ein Ticket gibt, ist unmöglich. Wenn eine Person das Ticket sieht, können andere es nicht sehen. Wer es ergattern kann, hängt vom „Glück“ der Person ab (Netzwerkgeschwindigkeit usw.). Wenn 10.000 Personen gleichzeitig klicken, um zu kaufen, wer kann den Deal abschließen? Insgesamt gibt es nur ein Ticket.
Zuerst können wir uns leicht mehrere Lösungen im Zusammenhang mit der Parallelität vorstellen:
Synchronisierung sperren. Die Synchronisierung bezieht sich eher auf die Anwendungsebene, auf die nur einzeln zugegriffen werden kann. Java Der Mittelfinger bezieht sich auf das Schlüsselwort syncrinized. Sperren haben auch zwei Ebenen: Die eine ist die in Java erwähnte Objektsperre, die für die Thread-Synchronisierung verwendet wird. Die andere Ebene ist die Datenbanksperre. Wenn es sich um ein verteiltes System handelt, kann dies offensichtlich nur durch die Verwendung der Sperre für die Datenbank erreicht werden Seite.
Angenommen, wir verwenden einen Synchronisierungsmechanismus oder einen physischen Sperrmechanismus für die Datenbank. Wenn sichergestellt wird, dass 10.000 Personen die Tickets weiterhin gleichzeitig sehen können, wird die Leistung offensichtlich beeinträchtigt, was auf Websites mit hoher Parallelität nicht ratsam ist. Nach der Verwendung des Ruhezustands haben wir ein anderes Konzept entwickelt: Optimistische Sperre und pessimistische Sperre (d. h. die Verwendung einer optimistischen Sperre kann dieses Problem lösen). Optimistisches Sperren bedeutet, die Geschäftskontrolle zu nutzen, um Parallelitätsprobleme zu lösen, ohne die Tabelle zu sperren. Dies stellt die gleichzeitige Lesbarkeit von Daten und die Exklusivität gespeicherter Daten sicher. Es stellt die Leistung sicher und löst gleichzeitig das Problem schmutziger Daten, die durch Parallelität verursacht werden.
So implementieren Sie optimistisches Sperren im Ruhezustand:
Voraussetzung: Fügen Sie der vorhandenen Tabelle ein redundantes Feld hinzu, Versionsnummer, langer Typ
Prinzip:
1) Es kann nur die aktuelle Versionsnummer = Versionsnummer der Datenbanktabelle übermittelt werden
2) Nach erfolgreicher Übermittlung wird die Versionsnummer Version ++
ganz einfach implementiert: Fügen Sie im Ormapping ein Attribut Optimistic hinzu -lock="version" reicht aus, das Folgende ist ein Beispielausschnitt
fcbe3e9142a5aba58f59285a7d211ac7
cb8fa3271e787dc97c7d5111201b534e
Fall 2, Aktienhandelssystem, Bankensystem, wie berücksichtigen Sie die Menge großer Datenmengen?
Erstens alle, Aktienhandelssystem In der Markttabelle wird alle paar Sekunden ein Marktdatensatz generiert. An einem Tag gibt es (unter der Annahme eines Marktes alle 3 Sekunden) die Anzahl der Aktien × 20 × 60 * 6 Datensätze tisch haben in einem monat? Wenn die Anzahl der Datensätze in einer Tabelle in Oracle 1 Million überschreitet, wird die Abfrageleistung sehr schlecht. Wie kann die Systemleistung sichergestellt werden?
Ein weiteres Beispiel: China Mobile hat Hunderte Millionen Benutzer. Wie gestaltet man die Tabelle? Alles in eine Tabelle packen? Daher muss für eine große Anzahl von Systemen eine Tabellenaufteilung in Betracht gezogen werden – (die Tabellennamen sind unterschiedlich, aber die Strukturen sind genau gleich. Es gibt mehrere gängige Methoden: (abhängig von der Situation)
1 ) Teilen nach Unternehmen, z. B. Für die Tabelle der Mobiltelefonnummern können wir die eine Tabelle, die mit 130 beginnt, als eine Tabelle betrachten, die andere Tabelle, die mit 131 beginnt usw.
2) Verwenden Sie den Tabellenaufteilungsmechanismus von Oracle um Untertabellen zu erstellen
3 ) Wenn es sich um ein Handelssystem handelt, können wir erwägen, es entsprechend der Zeitachse aufzuteilen, mit den Daten des aktuellen Tages in einer Tabelle und den historischen Daten in einer anderen Tabelle. Die Berichte und Abfragen historischer Daten haben hier keinen Einfluss auf den Handel des Tages.
Natürlich muss nach der Aufteilung der Tabelle unser Antrag entsprechend angepasst werden. Möglicherweise muss die einfache Oder-Zuordnung geändert werden. Beispielsweise müssen einige Unternehmen gespeicherte Prozeduren usw. durchlaufen.
Darüber hinaus müssen wir Caching in Betracht ziehen
Der Cache bezieht sich hier nicht nur auf den Ruhezustand, sondern der Ruhezustand selbst stellt First- und Cache der zweiten Ebene. Der Cache ist hier unabhängig von der Anwendung und ist immer noch ein Speicherlesevorgang. Wenn wir den häufigen Zugriff auf die Datenbank reduzieren können, ist dies auf jeden Fall von großem Nutzen für das System. Wenn beispielsweise bei der Produktsuche in einem E-Commerce-System häufig nach einem Produkt mit einem bestimmten Schlüsselwort gesucht wird, können Sie erwägen, diesen Teil der Produktliste im Cache (im Speicher) zu speichern, sodass Sie dies nicht tun müssen Greifen Sie jedes Mal auf die Datenbank zu und die Leistung wird erheblich verbessert.
Für einfaches Caching können Sie verstehen, dass Sie selbst eine Hashmap erstellen und einen Schlüssel für häufig abgerufene Daten erstellen. Der Wert ist der Wert, der zum ersten Mal aus der Datenbank gesucht wird Beim nächsten Besuch verfügen professionellere Anbieter derzeit über unabhängige Caching-Frameworks wie Memcached, die unabhängig als Cache-Server bereitgestellt werden können.
4. Gemeinsame Methoden zur Verbesserung der Zugriffseffizienz bei hoher Parallelität
Zunächst müssen wir verstehen, wo der Engpass bei hoher Parallelität liegt?
1. Die Servernetzwerkbandbreite reicht möglicherweise nicht aus
2. Die Anzahl der Web-Thread-Verbindungen reicht möglicherweise nicht aus.
3 hinaufgehen.
Je nach Situation sind auch die Lösungsideen unterschiedlich.
Wie im ersten Fall können Sie die Netzwerkbandbreite erhöhen und die Auflösung von DNS-Domänennamen auf mehrere Server verteilen.
Lastausgleich, Front-End-Proxyserver Nginx, Apache usw.
Datenbankabfrageoptimierung, Lese-/Schreibtrennung, Tabellen-Sharding usw.
Kopieren Sie endlich etwas davon werden bei hoher Parallelität benötigt Inhalte, die häufig verarbeitet werden müssen:
Versuchen Sie, Cache zu verwenden, einschließlich Benutzer-Cache, Informations-Cache usw. Wenn Sie mehr Speicher für das Caching aufwenden, kann dies die Interaktion mit der Datenbank erheblich reduzieren und die Leistung verbessern.
Verwenden Sie Tools wie jprofiler, um Leistungsengpässe zu finden und zusätzlichen Overhead zu reduzieren.
Optimieren Sie Datenbankabfrageanweisungen und reduzieren Sie die Anzahl direkt generierter Anweisungen mithilfe von Tools wie Hibernate (nur Langzeitabfragen werden optimiert).
Optimieren Sie die Datenbankstruktur, erstellen Sie mehr Indizes und verbessern Sie die Abfrageeffizienz.
Versuchen Sie, Statistikfunktionen so weit wie möglich zwischenzuspeichern oder verwandte Berichte täglich oder regelmäßig zu zählen, um bei Bedarf Statistiken zu vermeiden.
Verwenden Sie nach Möglichkeit statische Seiten, um das Parsen von Containern zu reduzieren (versuchen Sie, statisches HTML für dynamische Inhalte zur Anzeige zu generieren).
Nachdem Sie die oben genannten Probleme gelöst haben, verwenden Sie einen Servercluster, um das Engpassproblem eines einzelnen Servers zu lösen.
Java hat eine hohe Parallelität, wie man es löst, welche Methode, um es zu lösen
Bevor ich fälschlicherweise dachte, dass die Lösung für hohe Parallelität durch Threads oder Warteschlangen gelöst werden könnte , weil hohe Parallelität Manchmal greifen viele Benutzer zu, was zu falschen Systemdaten und Datenverlust führt, dachte ich Warteschlangen werden verwendet, um das Problem zu lösen. Wenn wir beispielsweise auf Produkte bieten, Kommentare auf Weibo weiterleiten oder Flash-Verkäufe von Produkten verkaufen, ist die Anzahl der Besuche gleich Eine besondere Rolle spielen hier die Warteschlangen. Alle Anfragen werden in die Warteschlange gestellt und in Millisekunden geordnet verarbeitet, sodass es nicht zu Datenverlusten oder fehlerhaften Systemdaten kommt.
Nachdem wir die Informationen heute überprüft haben, gibt es zwei Lösungen für eine hohe Parallelität:
Eine besteht darin, Caching zu verwenden, die andere darin, statische Seiten zu generieren Optimieren Sie den von uns geschriebenen Code, um unnötige Ressourcenverschwendung zu reduzieren: (
1. Verwenden Sie nicht häufig neue Objekte. Verwenden Sie den Singleton-Modus für Klassen, die nur eine Instanz in der gesamten Anwendung benötigen. Verwenden Sie für String-Verbindungsvorgänge StringBuffer oder StringBuilder. Greifen Sie bei Dienstprogrammklassen über statische Methoden darauf zu
2. Vermeiden Sie die Verwendung falscher Methoden. Exception kann beispielsweise den Methodenstart steuern, aber Exception sollte Stacktrace beibehalten, um die Leistung zu verbrauchen. Um beispielsweise eine bedingte Beurteilung vorzunehmen, versuchen Sie, die bedingte Beurteilungsmethode des Verhältnisses zu verwenden. Verwenden Sie effiziente Klassen in JAVA, wie z. B. ArrayList, die eine bessere Leistung als Vector bietet. )
Erstens habe ich nie Caching-Technologie verwendet. Ich denke, sie sollte die Daten im Cache speichern, wenn der Benutzer sie anfordert. Bei der nächsten Anfrage wird erkannt, ob sich Daten im Cache befinden, um mehrere Anfragen zu verhindern Dies führt zu einem ernsthaften Absturz des Servers. Detaillierte Informationen müssen jedoch weiterhin online erfasst werden Ich habe viele Websites gesehen, als die Seite angefordert wurde, z. B. „http://developer.51cto.com/art/201207/348766.htm“. Diese Seite ist tatsächlich eine Serveranforderungsadresse , die Zugriffsgeschwindigkeit erhöht sich, da statische Seiten keine Serverkomponenten haben. Ich werde sie hier näher vorstellen:
1 Was ist Seitenstatik:
Einfach Einfach ausgedrückt, wenn wir einen Link besuchen ,Das entsprechende Modul des Servers verarbeitet diese Anfrage, geht zur entsprechenden JSP-Schnittstelle und generiert schließlich die Daten, die wir sehen möchten. Der Nachteil liegt auf der Hand: Da jede Anfrage an den Server verarbeitet wird, z Wenn es zu viele gleichzeitige Anfragen gibt, erhöht dies den Druck auf den Anwendungsserver und kann ihn sogar zum Absturz bringen. Wie kann man es also vermeiden? Wenn wir das Paar test.do setzen Das Ergebnis wird nach der Anfrage in einer HTML-Datei gespeichert und der Benutzer greift dann jedes Mal darauf zu. Würde sich dadurch nicht der Druck auf den Anwendungsserver verringern?
Woher kommen also statische Seiten? Wir können nicht zulassen, dass wir jede Seite manuell verarbeiten, oder? Dabei geht es um das, was wir erklären werden, die Lösung zur Generierung statischer Seiten ... Was wir brauchen, ist die automatische Generierung einer statischen Seite. Wenn der Benutzer sie besucht, wird test.html automatisch generiert und dann dem Benutzer angezeigt.
2. Lassen Sie uns kurz die Wissenspunkte vorstellen, die Sie beherrschen sollten, um das Seitenstatikisierungsschema zu beherrschen:
Grundlagen – URL-Rewrite
Was ist URL-Rewrite? ? URL-Umschreibung. Lassen Sie uns das Problem anhand eines einfachen Beispiels veranschaulichen: Geben Sie die URL ein, greifen Sie jedoch tatsächlich auf abc.com/test.action zu, dann können wir sagen, dass die URL neu geschrieben wurde. Diese Technologie ist weit verbreitet und es gibt viele Open-Source-Tools, die diese Funktion erreichen können.
2. Grundlagen – Servlet web.xml
Wenn Sie immer noch nicht wissen, wie eine Anfrage und ein Servlet in web.xml zusammengeführt werden, durchsuchen Sie bitte die Servlet-Dokumentation. Das ist kein Unsinn, viele Leute denken, dass die Matching-Methode /xyz/*.do effektiv sein kann.
Wenn Sie immer noch nicht wissen, wie man ein Servlet schreibt, dann suchen Sie bitte danach, wie man ein Servlet schreibt. Das ist kein Scherz, da heutzutage viele Integrationstools im Umlauf sind, werden viele Leute keins von Grund auf schreiben .servlet.
3. Grundlegende Lösungseinführung

Unter anderem können Sie für den URL-Rewriter-Teil kostenpflichtige oder Open-Source-Tools verwenden Implementieren Sie es. Wenn die URL nicht besonders komplex ist, können Sie erwägen, sie in einem Servlet zu implementieren. Dann sieht es so aus:

总 结:其实我们在开发中都很少考虑这种问题,直接都是先将功能实现,当一个程序员在干到1到2年,就会感觉光实现功能不是最主要的,安全性能、质量等等才是 一个开发人员最该关心的。今天我所说的是高并发。
我的解决思路是:
1、采用分布式应用设计
2、分布式缓存数据库
3、代码优化
Java高并发的例子:
具体情况是这样: 通过java和数据库,自己实现序列自动增长。
实现代码大致如下:
id_table表结构, 主要字段:
id_name varchar2(16); id_val number(16,0); id_prefix varchar2(4);
//操作DB
public synchronized String nextStringValue(String id){
SqlSession sqlSess = SqlSessionUtil.getSqlSession();
sqlSess.update("update id_table set id_val = id_val + 1 where id_name="+id);
Map map = sqlSess.getOne("select id_name, id_prefix, id_val from id_table where id_name="+ id);
BigDecimal val = (BigDecimal) map.get("id_val");
//id_val是具体数字,rePack主要是统一返回固定长度的字符串;如:Y0000001, F0000001, T0000001等
String idValue = rePack(val, map);
return idValue;
}
//公共方法
public class IdHelpTool{
public static String getNextStringValue(String idName){
return getXX().nextStringValue(idName);
}
}具体使用者,都是通过类似这种方式:IdHelpTool.getNextStringValue("PAY_LOG");来调用。
问题:
(1) 当出现并发时, 有时会获取重复的ID;
(2) 由于服务器做了相关一些设置,有时调用这个方法,好像还会导致超时。
为了解决问题(1), 考虑过在方法getNextStringValue上,也加上synchronized , 同步关键字过多,会不会更导致超时?
跪求大侠提供个解决问题的大概思路!!!
解决思路一:
1、推荐 https://github.com/adyliu/idcenter
2、可以通过第三方redis来实现。
解决思路一:
1、出现重复ID,是因为脏读了,并发的时候不加 synchronized 比如会出现问题
2、但是加了 synchronized ,性能急剧下降了,本身 java 就是多线程的,你把它单线程使用,不是明智的选择,同时,如果分布式部署的时候,加了 synchronized 也无法控制并发
3、调用这个方法,出现超时的情况,说明你的并发已经超过了数据库所能处理的极限,数据库无限等待导致超时
基于上面的分析,建议采用线程池的方案,支付宝的单号就是用的线程池的方案进行的。
数据库 update 不是一次加1,而是一次加几百甚至上千,然后取到的这 1000个序号,放在线程池里慢慢分配即可,能应付任意大的并发,同时保证数据库没任何压力。
Das obige ist der detaillierte Inhalt vonWie löst man eine hohe Parallelität in Java? Java-Lösung mit hoher Parallelität. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!