
Heim >Web-Frontend >js-Tutorial >Wie der Knoten Bilder von Webseiten crawlt (Code im Anhang)
Wie der Knoten Bilder von Webseiten crawlt (Code im Anhang)

- 不言Original
- 2018-08-17 15:45:202849Durchsuche
Der Inhalt dieses Artikels befasst sich mit dem Crawlen von Bildern von Webseiten (mit Code). Ich hoffe, dass er für Freunde hilfreich ist.
Verzeichnis
Knoten installieren und Abhängigkeiten herunterladen
Dienst erstellen
-
Fordern Sie die Seite an, die wir crawlen möchten, und geben Sie JSON zurück
Knoten installieren
Wir beginnen mit der Installation des Knotens. Sie können zur offiziellen Website des Knotens gehen, um https herunterzuladen ://nodejs.org/zh-cn/, führen Sie node nach dem Herunterladen aus.
node -v
Nach erfolgreicher Installation wird die von Ihnen installierte Versionsnummer angezeigt.
Als nächstes verwenden wir den Knoten, um „Hallo Welt“ auszudrucken, erstellen eine neue Datei mit dem Namen index.js und geben
console.log('hello world')
ein. Führen Sie diese Datei aus
node index.js
und sie wird auf dem ausgegeben Systemsteuerung Hallo Welt
Erstelle einen Server
Erstelle einen neuen Ordner mit dem Namen node.
Zuerst müssen Sie die Express-Abhängigkeit
npm install express
herunterladen und dann eine neue Datei mit dem Namen demo.js mit der unten gezeigten Verzeichnisstruktur erstellen:

in demo.js stellt den heruntergeladenen Express vor
const express = require('express');
const app = express();
app.get('/index', function(req, res) {
res.end('111')
})
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
}) und führt den Knoten demo.js aus, um einen einfachen Dienst einzurichten, wie im Bild gezeigt: 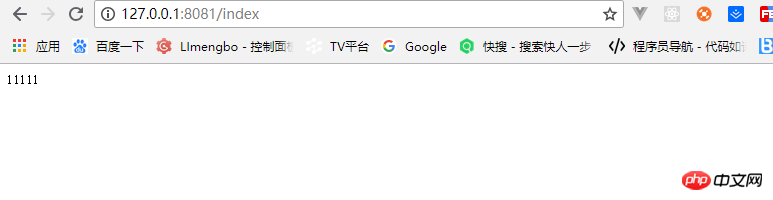
Seite anfordern wir wollen crawlen
Fordern Sie die Seite an, die wir crawlen möchten
npm install superagent npm install superagent-charset npm install cheerio
Superagent wird zum Initiieren von Anfragen verwendet. Es handelt sich um eine leichte, progressive Ajax-API mit guter Lesbarkeit, geringer Lernkurve und interner Abhängigkeit auf der nativen Anforderungs-API von nodejs, geeignet für die Umgebung von nodejs. Sie können auch http verwenden, um eine Anfrage zu initiieren Angepasst an den Server, schnelle, flexible und implementierte jQuery-Kernimplementierung. Nachdem Sie die Abhängigkeiten installiert haben, können Sie sie einführen
var superagent = require('superagent'); var charset = require('superagent-charset'); charset(superagent); const cheerio = require('cheerio');
Fordern Sie nach dem Import unsere Adresse an, https://www.qqtn.com/tx/weixintx_1.html, wie im Bild gezeigt:
Deklarieren Sie die Adressvariable:const baseUrl = 'https://www.qqtn.com/'
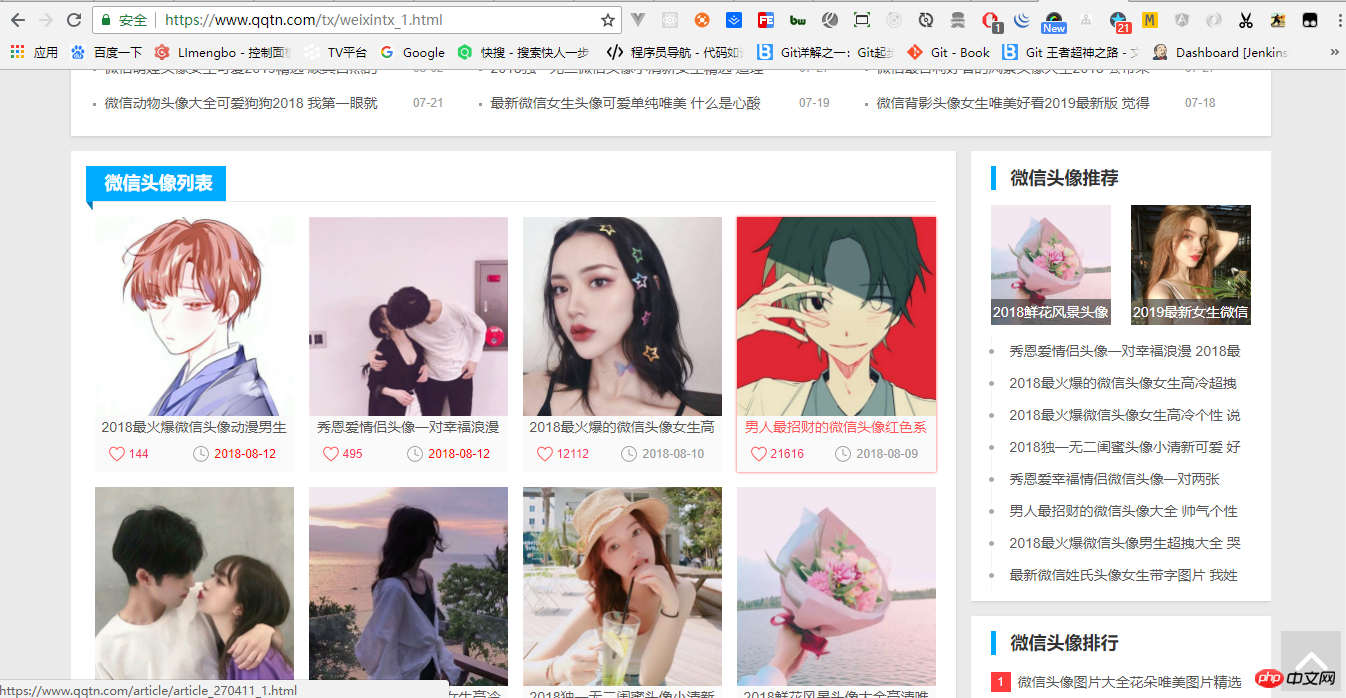 Nachdem diese Einstellungen abgeschlossen sind, wird die Anfrage gesendet. Als nächstes sehen Sie sich bitte den vollständigen Code demo.js an
Nachdem diese Einstellungen abgeschlossen sind, wird die Anfrage gesendet. Als nächstes sehen Sie sich bitte den vollständigen Code demo.js anvar superagent = require('superagent');
var charset = require('superagent-charset');
charset(superagent);
var express = require('express');
var baseUrl = 'https://www.qqtn.com/'; //输入任何网址都可以
const cheerio = require('cheerio');
var app = express();
app.get('/index', function(req, res) {
//设置请求头
res.header("Access-Control-Allow-Origin", "*");
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header('Access-Control-Allow-Headers', 'Content-Type');
//类型
var type = req.query.type;
//页码
var page = req.query.page;
type = type || 'weixin';
page = page || '1';
var route = `tx/${type}tx_${page}.html`
//网页页面信息是gb2312,所以chaeset应该为.charset('gb2312'),一般网页则为utf-8,可以直接使用.charset('utf-8')
superagent.get(baseUrl + route)
.charset('gb2312')
.end(function(err, sres) {
var items = [];
if (err) {
console.log('ERR: ' + err);
res.json({ code: 400, msg: err, sets: items });
return;
}
var $ = cheerio.load(sres.text);
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function(idx, element) {
var $element = $(element);
var $subElement = $element.find('img');
var thumbImgSrc = $subElement.attr('src');
items.push({
title: $(element).attr('title'),
href: $element.attr('href'),
thumbSrc: thumbImgSrc
});
});
res.json({ code: 200, msg: "", data: items });
});
});
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})Führen Sie demo.js aus und es wird an uns zurückgegeben. Die erhaltenen Daten sind wie in der Abbildung dargestellt:
Ein einfacher Knoten-Crawler ist fertig.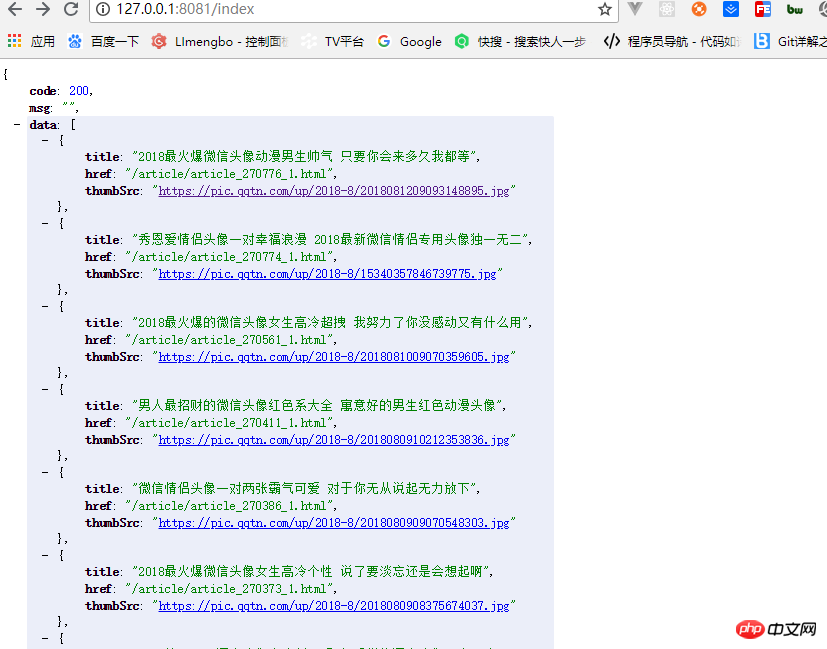 Verwandte Empfehlungen:
Verwandte Empfehlungen:
Knoten Beispielcode-Sharing von http-Crawler
Das obige ist der detaillierte Inhalt vonWie der Knoten Bilder von Webseiten crawlt (Code im Anhang). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!