
Heim >Datenbank >MySQL-Tutorial >[MySQL-Datenbank] Interpretation von Kapitel 4: Schema- und Datentypoptimierung (Teil 1)
[MySQL-Datenbank] Interpretation von Kapitel 4: Schema- und Datentypoptimierung (Teil 1)
- php是最好的语言Original
- 2018-08-07 13:53:421832Durchsuche
Vorwort:
Der Grundstein für hohe Leistung: gutes logisches und physisches Design, Designschema gemäß den vom System auszuführenden Abfrageanweisungen
Dieses Kapitel konzentriert sich auf das MySQL-Datenbankdesign und stellt den Unterschied zwischen MySQL-Datenbankdesign und anderen relationalen Datenbankverwaltungssystemen vor
Schema: [Quelle]
Schema ist Eine Sammlung von Datenbankobjekten . Diese Sammlung enthält verschiedene Objekte wie Tabellen, Ansichten, gespeicherte Prozeduren, Indizes usw. Um verschiedene Sammlungen zu unterscheiden, müssen Sie verschiedenen Sammlungen unterschiedliche Namen geben. Standardmäßig entspricht ein Benutzer einer Sammlung. Der Schemaname des Benutzers entspricht dem Benutzernamen und wird als Standardschema für verwendet der Benutzer. Die Schemasammlung sieht also wie Benutzernamen aus.
Wenn Sie sich die Datenbank als Lagerhaus vorstellen, hat das Lagerhaus viele Räume (Schema), ein Schema stellt einen Raum dar, der Tisch kann als Schließfach in jedem Raum angesehen werden und der Benutzer ist der Eigentümer von Jedes Schema hat das Recht, jeden Raum in der Datenbank zu bedienen, was bedeutet, dass jeder in der Datenbank zugeordnete Benutzer den Schlüssel zu jedem Schema (Raum) hat. Es gibt Unterschiede zwischen SQL Server und Oracle MySQL 4.1 Optimierte Datentypen auswählen Grundsätze: 1Kleinere Durchgänge sind besser, versuchen Sie es zu verwenden sie Der kleinste Datentyp, der Daten korrekt speichern kann (belegt weniger Festplattenspeicher und CPU-Cache, erfordert weniger CPU-Zyklen für die Verarbeitung: schneller), kann aber die Daten abdecken, und es wird peinlich sein, wenn sie nicht gespeichert werden können
2, Einfach ist gut: Einfacher Typ (weniger CPU-Zyklen), in MySQL integrierte Typspeicherzeit verwenden, Ganzzahltyp-Speicher-IP, Ganzzahltyp ist billiger als Zeichen (Zeichensatz und Sortierregeln machen Zeichen komplexer) 3. Versuchen Sie, Null zu vermeiden: Geben Sie am besten nicht Null an *) Nullspalten belegen mehr Speicherplatz und erfordern eine spezielle Verarbeitung in MySQL *) Null erstellt Index- und Indexstatistiken und der Wertevergleich ist komplexer; wenn nullfähige Spalten indiziert werden, erfordert jeder Indexdatensatz zusätzliche Bytes Ausnahme: InnoDB verwendet ein einzelnes Bit zum Speichern von Nullen, also für spärliche Daten (viele Werte sind null) Es gibt eine sehr gute Speicherplatzeffizienz, die nicht für MyISAM geeignet ist. 16) mediumint (24) int(32) bigint(64)1. Bereich der gespeicherten Werte:, N ist die Anzahl der Ziffern im Speicherplatz
2. optional, nicht erlaubt Negative Werte können die Obergrenze positiver Zahlen verdoppeln: tinyint unsigned 0~255, tinyint-128~127
3. Verwenden Sie den gleichen Speicherplatz und die gleiche Leistung mit oder ohne Vorzeichen
Die Breite kann für eine Ganzzahl wie INT(11) angegeben werden, was für die meisten Anwendungen bedeutungslos ist. Sie schränkt den zulässigen Wertebereich nicht ein, sondern gibt nur die Anzahl der von interaktiven Tools angezeigten Zeichen an. Für die Speicherung und Berechnung sind int(1) und int (20) dasselbe; 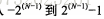
varchar:
1. Die Speicherung variabler Zeichenfolgen spart im Vergleich zu feste Länge (verbraucht nur den erforderlichen Platz), aber wenn die Tabelle row_format=fixed verwendet, werden die Zeilen in fester Länge gespeichert. 2 ist ein halbes zusätzliches Byte erforderlich, um die Zeichenfolgenlänge aufzuzeichnen maximale Länge 3. Sparen Sie Speicherplatz und verbessern Sie die Leistung; die Zeile kann sich jedoch während der Aktualisierung ändern. Sie ist länger als das Original und erfordert zusätzliche ArbeitGeeignete Situationen:
1) Die maximale Länge der String-Spalte ist viel größer als die durchschnittliche Länge; 2) Weniger Spaltenaktualisierung (keine Sorge wegen Fragmentierung); 3) Verwenden Sie UTF-8-Strings, jedes Zeichen wird mit einer anderen Anzahl von Bytes gespeichertchar:
1. Feste Länge, Platz entsprechend der Länge zuweisen, wenn die Länge nicht ausreicht, füllen Sie die Leerzeichen aus
2 Effizienterer Speicherplatz, Zeichen (1) wird verwendet, um nur 1 Wert von Y N Bytes, varchar2 Bytes und einer Datensatzlänge zu speichern
Geeignete Situationen:
1) Geeignet zum Speichern sehr kurzer Zeichenfolgen ; 2) Oder der Gesamtwert ist nahezu gleich lang; 3) Häufig geänderte Daten werden beim Speichern nicht leicht fragmentiert:
Beim Speichern des Zeichentyps werden die nachgestellten Leerzeichen gelöscht. Wie die Daten gespeichert werden, hängt von der Speicher-Engine ab. Die Speicher-Engine unterstützt nur Zeilen fester Länge (maximal zugewiesener Speicherplatz).
binär, varbinary: speichert Binärzeichenfolgen
,Bytecode , Länge nicht ausreichend, Früher Synonym für tinyint, neue Funktionen Bit (1) Einzelbitfeld, Bit (2) 2 Bit, maximale Länge 64 Bit Verhalten variiert je nach Speicher-Engine MyISAM packt und speichert alle BIT-Spalten (17 separate Bit-Spalten erfordern nur 17 Bit zum Speichern, myisam3 Bytes ok), andere Engines Memory und innoDB verwenden den kleinsten Integer-Typ, der ausreicht, um jede Bit-Spalte zu speichern, was keinen Speicherplatz spart MySQL behandelt Bits als String-Typ , Abruf Das Bit(1) Wert und Ergebnis sind Zeichenfolgen, die binäre 0/1 enthalten. Beim Abrufen des numerischen Kontexts wird die Verwendung von -Element in der Liste oder eine Kombination mehrerer Elemente 4.1.5 Bits
Bit: mysql5.0
![[MySQL-Datenbank] Interpretation von Kapitel 4: Schema- und Datentypoptimierung (Teil 1)](https://img.php.cn//upload/image/636/907/440/1533621119495187.png "1533621119495187.png")
1~8成员的集合,占1个字节。
9~16成员的集合,占2个字节。
17~24成员的集合,占3个字节。
25~32成员的集合,占4个字节。
33~64成员的集合,占8个字节。
Es müssen viele wahre und falsche Werte beibehalten werden Erwägen Sie daher das Zusammenführen dieser Spalten in den Satztyp, der intern durch eine Reihe von gepackten Bits
nutzt effektiv Speicherplatz ), und MySQL verfügt über find_in_set- und Feldfunktionen, um die Abfrage zu erleichtern in; Nachteile: Das Ändern der Definition einer Spalte ist teuer, erfordert eine Änderung der Tabelle und kann nicht mehr über die Indexsuche festgelegt werden
Bitweise Operation für ganzzahlige Spalten: Anstelle von set Die Methode: Verwenden Sie Ganzzahlen, um eine Reihe von Bits zu verpacken: 8 Bits können in tinyint gepackt und in bitweisen Operationen verwendet werden. Definieren Sie Namenskonstanten für die Bits, um diese Arbeit zu vereinfachen. Auf diese Weise ist die Abfrageanweisung jedoch schwierig zu schreiben schwer zu verstehen 4.1.6 Bezeichner auswählen Identifikationsspalte: Spalte mit automatischer Vergrößerung [Quelle] 1) Das System stellt keine Notwendigkeit dar, Werte manuell einzugeben Standardsequenzwerte; 2) Nicht erforderlich. Abgleich mit dem Primärschlüssel. 3) Es muss ein eindeutiger Schlüssel sein. 5) Der Typ kann nur numerisch sein. Es kann übergeben werden: set auto_increment_increment=3;Berücksichtigen Sie bei der Auswahl des Identitätsspaltentyps den Speichertyp und die Art und Weise, wie MySQL Berechnungen und Vergleiche für diesen Typ durchführt Stellen Sie sicher, dass Sie in allen zugehörigen Tabellen denselben Typ verwenden.
Tipps:1. Integer ist normalerweise der beste Auswahl, schnell und kann auto_increment verwenden
2. Enum- und Set-Typen, feste Speicherinformationen
3. Vermeiden Sie, dass der Speicherplatzverbrauch langsamer ist als bei Zahlen. Seien Sie besonders vorsichtig bei Myisam-Tabellen (Standard). Zeichenfolgenkomprimierung, langsame Abfrage) 1) Völlig „zufällige“ Zeichenfolge MD5 Die von der Funktion /SHA1/UUID generierten neuen Werte werden willkürlich in einem großen Raum verteilt, was dazu führt, dass das Einfügen und einige Auswahlvorgänge langsamer werden :
Einfügewerte werden zufällig an verschiedene Positionen im Index geschrieben, und das Einfügen wird langsamer (Seiten-Split-Disk-Random-Access-Cluster-Index-Auswahl verlangsamt sich,
logisch benachbarte Zeilen werden verteilt). Verschiedene Orte auf der Festplatte und im Speicher;Zufallswerte führen dazu, dass der Cache für alle Typabfrageanweisungen weniger effektiv wird (Ungültigmachen des Zugriffslokalitätsprinzips
, auf dem derCache basiert)
Clustered-Index , die tatsächlich gespeicherte sequentielle Struktur und die physische Struktur der Datenspeicherung Im Allgemeinen gibt es nur eine physische Sequenzstruktur und es kann nur einen Clustered-Index für a geben Normalerweise ist der Primärschlüssel der Standardwert. Das System fügt standardmäßig einen Clustered-Index für Sie hinzu. Nicht gruppierte Indizes mit unterschiedlichen Anforderungen können entsprechend eingerichtet werden die Einschränkungen verschiedener Spalten; 2) Speichern Sie die UUID, entfernen Sie das - Symbol oder verwenden Sie unhex, um den UUID-Wert in eine 16-Byte-Zahl umzuwandeln, und speichern Sie ihn in einer binären (16) Spalte, formatieren Sie ihn in das Hexadezimalformat durch die Hex-Funktion während des Abrufs; Es ist besser, die Ganzzahl zu erhöhen
Vorsicht vor automatisch generiertem Schema:Schwere Leistungsprobleme, große Varchar-Werte, verwandte Spalten verschiedener Typen; orm speichert jede Art von Daten in jeder Art von Back-End-Datenspeicher. Es ist nicht darauf ausgelegt, einen besseren Speichertyp zu verwenden. Manchmal wird für jedes Attribut jedes Objekts eine separate Zeile verwendet . Die Verwendung der zeitstempelbasierten Versionskontrolle führt zu mehreren Versionen eines einzelnen Attributs. Verwandte Artikel: [MySQL-Datenbank] Kapitel 3 Interpretation: Server-Leistungsanalyse (Teil 1) [MySQL-Datenbank] Kapitel 3 Interpretation: Server-Leistungsanalyse (Teil 2) 4.1.7 Spezielle Datentypen: leer
Das obige ist der detaillierte Inhalt von[MySQL-Datenbank] Interpretation von Kapitel 4: Schema- und Datentypoptimierung (Teil 1). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!