
Heim >Backend-Entwicklung >PHP-Tutorial >Was sind die Unterschiede zwischen Clustering, Verteilung und Lastausgleich? (Bilder und Text)
Was sind die Unterschiede zwischen Clustering, Verteilung und Lastausgleich? (Bilder und Text)

- 不言Original
- 2018-07-25 16:46:493617Durchsuche
Es gibt große Unterschiede zwischen Clustering, Verteilung und Lastausgleich in PHP. Im folgenden Artikel werde ich Ihnen ohne weitere Umschweife eine detaillierte Beschreibung der spezifischen Unterschiede geben.
Das Konzept des Clusters
Computercluster sind über eine Reihe lose integrierter Computersoftware und/oder -hardware miteinander verbunden, um bei der Erledigung der Computerarbeit eng zusammenzuarbeiten. In gewissem Sinne kann man sie sich wie einen Computer vorstellen. Die einzelnen Computer in einem Clustersystem werden üblicherweise Knoten genannt und sind meist über ein lokales Netzwerk verbunden, es sind jedoch auch andere Verbindungen möglich. Cluster-Computer werden häufig verwendet, um die Rechengeschwindigkeit und/oder Zuverlässigkeit eines einzelnen Computers zu verbessern. Generell sind Cluster-Rechner wesentlich kostengünstiger als Einzelrechner, etwa Workstations oder Supercomputer. Beispielsweise wird ein einzelner Hochleistungsvorgang zur parallelen Verarbeitung auf mehrere Knotengeräte verteilt. Nachdem jedes Knotengerät die Verarbeitung abgeschlossen hat, werden die Ergebnisse zusammengefasst und an den Benutzer zurückgegeben. Die Systemverarbeitungsfähigkeit wird erheblich verbessert. Im Allgemeinen in mehrere Typen unterteilt:
- Hochverfügbarkeitscluster: Dies bedeutet im Allgemeinen, dass die Aufgaben darauf automatisch auf andere normale Knoten übertragen werden, wenn ein Knoten im Cluster ausfällt. Dies bedeutet auch, dass ein Knoten im Cluster offline gehalten und dann wieder online geschaltet werden kann. Dieser Vorgang hat keine Auswirkungen auf den Betrieb des gesamten Clusters.
- Lastausgleichscluster: Wenn ein Lastausgleichscluster ausgeführt wird, verteilt er die Arbeitslast im Allgemeinen auf eine Gruppe von Servern im Hintergrund Dadurch wird eine hohe Performance und hohe Verfügbarkeit des Gesamtsystems erreicht.
- Hochleistungs-Computing-Cluster: High-Performance-Computing-Cluster verbessert die Rechenleistung, indem es Rechenaufgaben auf verschiedene Rechenknoten im Cluster verteilt, also hauptsächlich Wird im Bereich des wissenschaftlichen Rechnens verwendet.
Verteilt
Cluster: Das gleiche Unternehmen wird auf mehreren Servern bereitgestellt. Verteilt: Ein Unternehmen ist in mehrere Unterunternehmen aufgeteilt, oder es handelt sich um unterschiedliche Unternehmen, die auf verschiedenen Servern bereitgestellt werden. Einfach ausgedrückt verbessert die Verteilung die Effizienz, indem sie die Ausführungszeit einer einzelnen Aufgabe verkürzt, während Clustering die Effizienz verbessert, indem sie die Anzahl der pro Zeiteinheit ausgeführten Aufgaben erhöht. Beispiel: Nehmen wir Sina.com: Wenn mehr Leute es besuchen, kann es einen Cluster erstellen, einen Ausgleichsserver vorne und mehrere Server hinten platzieren, um das gleiche Geschäft abzuschließen Der Antwortserver erkennt, welcher Server nicht stark ausgelastet ist. Wenn ein Server ausfällt, können andere Server hochfahren. Jeder verteilte Knoten führt unterschiedliche Dienste aus. Wenn ein Knoten zusammenbricht, kann das Geschäft scheitern.
Lastausgleich
Konzept Mit der Zunahme des Geschäftsvolumens nimmt die Anzahl der Besuche und der Datenverkehr in jedem Kernteil des bestehenden Netzwerks zu Dementsprechend sind auch die Rechenleistung und die Rechenintensität gestiegen, so dass ein einzelnes Servergerät dies nicht mehr bewältigen kann. Wenn Sie in diesem Fall die vorhandene Ausrüstung wegwerfen und viele Hardware-Upgrades durchführen, führt dies zu einer Verschwendung vorhandener Ressourcen, und wenn Sie mit der nächsten Steigerung des Geschäftsvolumens konfrontiert sind, führt dies zu hohen Kosten für ein weiteres Hardware-Upgrade. Kosteninvestitionen, selbst die beste Ausrüstung kann den aktuellen Bedarf an Geschäftswachstum nicht decken. Die Lastausgleichstechnologie virtualisiert die Anwendungsressourcen mehrerer realer Server im Backend zu einem Hochleistungsanwendungsserver, indem eine virtuelle Server-IP (VIP) festgelegt wird. Über den Lastausgleichsalgorithmus wird die Anforderung des Benutzers an den Backend-Intranetserver weitergeleitet . Der Intranet-Server gibt die Antwort auf die Anfrage an den Load Balancer zurück, und der Load Balancer sendet die Antwort dann an den Benutzer. Dadurch wird die Intranet-Struktur vor Internetbenutzern verborgen und Benutzer werden daran gehindert, direkt auf den Backend-Server (Intranet) zuzugreifen Server sicherer, wodurch Angriffe auf den Kernnetzwerk-Stack und auf anderen Ports ausgeführte Dienste verhindert werden können. Und das Lastausgleichsgerät (Software oder Hardware) überprüft kontinuierlich den Anwendungsstatus auf dem Server und isoliert automatisch den ungültigen Anwendungsserver, wodurch eine einfache, skalierbare und äußerst zuverlässige Anwendungslösung realisiert wird, die das Problem löst Leistung, unzureichende Skalierbarkeit und geringe Zuverlässigkeit.
Die Systemerweiterung kann in vertikale (vertikale) Erweiterung und horizontale (horizontale) Erweiterung unterteilt werden. Bei der vertikalen Erweiterung geht es darum, die Verarbeitungsleistung des Servers aus der Sicht einer einzelnen Maschine zu erhöhen, indem die Hardware-Verarbeitungsfunktionen wie CPU-Verarbeitungsleistung, Speicherkapazität, Festplatte usw. erhöht werden, was den Anforderungen großer verteilter Systeme (Websites) nicht gerecht werden kann. , großer Datenverkehr, hohe Parallelität und große Datenmengen. Daher ist es notwendig, eine horizontale Erweiterungsmethode durch Hinzufügen von Maschinen anzuwenden, um die Verarbeitungskapazitäten großer Website-Dienste zu erfüllen. Wenn beispielsweise eine Maschine die Anforderungen nicht erfüllen kann, fügen Sie zwei oder mehr Maschinen hinzu, um den Zugriffsdruck zu teilen.
Eine der wichtigsten Anwendungen des Lastausgleichs ist die Verwendung mehrerer Server zur Bereitstellung eines einzelnen Dienstes Diese Lösung wird manchmal als Serverfarm bezeichnet. Normalerweise wird der Lastausgleich hauptsächlich in Web-Websites, großen Internet-Relay-Chat-Netzwerken, stark frequentierten Datei-Download-Websites, NNTP-Diensten (Network News Transfer Protocol) und DNS-Diensten verwendet. Jetzt unterstützen Load Balancer auch Datenbankdienste, sogenannte Datenbank-Load Balancer.
Der Lastausgleich des Servers verfügt über drei Grundfunktionen: Lastausgleichsalgorithmus, Gesundheitsprüfung und Sitzungswartung. Diese drei Funktionen sind die Grundelemente, um den normalen Betrieb des Lastausgleichs sicherzustellen. Einige andere Funktionen vertiefen diese drei Funktionen. Im Folgenden stellen wir die Funktionen und Prinzipien jeder Funktion im Detail vor.
Bevor das Lastausgleichsgerät bereitgestellt wird, greifen Benutzer direkt auf die Serveradresse zu (die Serveradresse kann anderen Adressen in der Firewall zugeordnet werden, es handelt sich jedoch im Wesentlichen um einen Eins-zu-eins-Zugriff). Wenn ein einzelner Server den Zugriff vieler Benutzer aufgrund unzureichender Leistung nicht bewältigen kann, muss die Verwendung mehrerer Server zur Bereitstellung von Diensten in Betracht gezogen werden. Der Weg, dies zu erreichen, ist der Lastausgleich. Das Implementierungsprinzip des Lastausgleichsgeräts besteht darin, die Adressen mehrerer Server einer externen Dienst-IP zuzuordnen (wir nennen sie normalerweise VIP). Für die Serverzuordnung können Sie die Server-IP direkt einer VIP-Adresse zuordnen oder den Server zuordnen IP:Port. Verschiedene Zuordnungsmethoden führen zu unterschiedlichen Portzuordnungen. Dieser Vorgang ist für den Benutzer nicht erkennbar Wenn der Lastausgleich erfolgt ist, ist es die Aufgabe des Lastausgleichsgeräts, den Zugriff des Benutzers auf den entsprechenden Server zu verteilen, nachdem er immer noch auf dieselbe Ziel-IP zugreift drei Hauptmerkmale, die oben erwähnt wurden.
Führen wir eine detaillierte Zugriffsprozessanalyse durch: 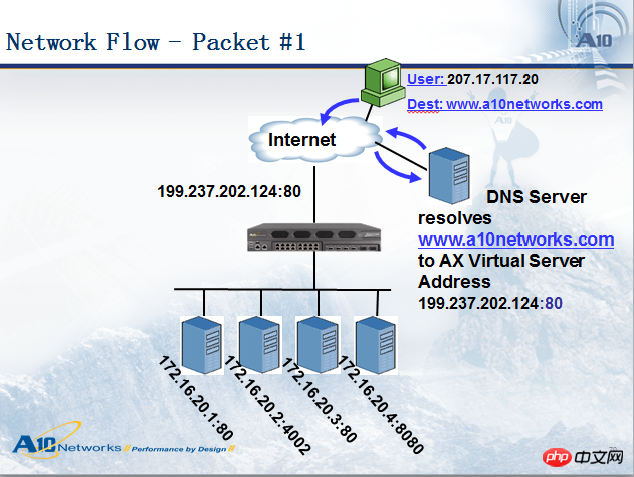
Wenn ein Benutzer (IP: 207.17.117.20) auf einen Domänennamen zugreift www.a10networks.com, analysiert er zunächst den öffentlichen Domänennamen von Dieser Domänenname wird über die DNS-Abfrage gesendet. Als nächstes greift der Benutzer 207.17.117.20 auf die Adresse 199.237.202.124 zu, sodass das Datenpaket beim Lastausgleichsgerät ankommt an den entsprechenden Server. Siehe Abbildung unten: 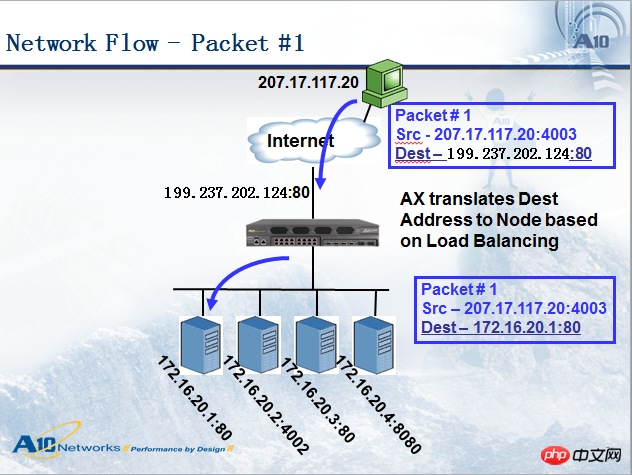
Wenn das Lastausgleichsgerät das Datenpaket an den Server sendet, nimmt das Datenpaket einige Änderungen vor Das Datenpaket erreicht das Lastausgleichsgerät. Die Quelladresse lautet: 207.17.117.20. Die Zieladresse lautet: 199.237.202.124. Wenn das Lastausgleichsgerät das Datenpaket an den ausgewählten Server weiterleitet, lautet die Quelladresse weiterhin: 207.17.117.20 , und die Zieladresse wird 172.16.20.1. Wir nennen diese Methode Zieladresse NAT (DNAT, Destination Address Translation). Im Allgemeinen muss DNAT im Server-Lastausgleich erfolgen (es gibt einen anderen Modus namens Server Direct Return-DSR, der kein DNAT durchführt, wir werden dies separat besprechen), und die Quelladresse hängt manchmal vom Bereitstellungsmodus ab Es ist notwendig, in andere Adressen zu konvertieren, die wir als Quelladresse NAT (SNAT) bezeichnen. Im Allgemeinen erfordert der Bypass-Modus SNAT, der serielle Modus jedoch nicht. Dieses Diagramm ist im seriellen Modus, daher wurde kein NAT durchgeführt.
Schauen wir uns das Rückgabepaket vom Server an, wie in der Abbildung unten gezeigt. Es hat ebenfalls den IP-Adresskonvertierungsprozess durchlaufen, aber die Quell-/Zieladresse im Antwortpaket ist genau umgekehrt Die Quelladresse des vom Server zurückgegebenen Pakets lautet 172.16.20.1, die Zieladresse ist 207.17.117.20. Nach Erreichen des Lastausgleichsgeräts ändert das Lastausgleichsgerät die Quelladresse in 199.237.202.124 und leitet sie dann an den Benutzer weiter. Gewährleistung der Konsistenz des Zugriffs. 
Lastausgleichsalgorithmus
Im Allgemeinen unterstützen Lastausgleichsgeräte standardmäßig mehrere Lastausgleichsverteilungsstrategien, wie zum Beispiel:
RoundRobin sendet Anfragen in einer kreisförmigen Reihenfolge an jeden Server. Wenn einer der Server ausfällt, nimmt AX ihn aus der sequenziellen Ringwarteschlange und nimmt nicht an der nächsten Abfrage teil, bis der Normalzustand wiederhergestellt ist.
Verhältnis: Weisen Sie jedem Server einen gewichteten Wert als Verhältnis zu. Benutzeranfragen werden an jeden Server verteilt. Wenn einer der Server ausfällt, nimmt AX ihn aus der Serverwarteschlange und beteiligt sich erst dann an der Verteilung der nächsten Benutzeranforderung, wenn der Normalzustand wiederhergestellt ist.
Priorität: Gruppieren Sie alle Server, definieren Sie die Priorität für jede Gruppe und weisen Sie Benutzeranfragen der Priorität zu. Die Servergruppe der höchsten Ebene (innerhalb derselben Gruppe, wobei ein voreingestellter Abfrage- oder Verhältnisalgorithmus verwendet wird, um Benutzeranfragen zuzuweisen. Wenn alle Server oder eine bestimmte Anzahl von Servern in der höchsten Prioritätsstufe ausfallen, sendet AX die Anfrage an die Servergruppe mit der nächsten Priorität. Diese Methode bietet Benutzern tatsächlich eine Hot-Backup-Methode.
LeastConnection: AX zeichnet die aktuelle Anzahl von Verbindungen auf jedem Server oder Service-Port auf und neue Verbindungen werden an den Server mit der geringsten Anzahl von Verbindungen weitergeleitet. Wenn einer der Server ausfällt, nimmt AX ihn aus der Serverwarteschlange und beteiligt sich erst dann an der Verteilung der nächsten Benutzeranforderung, wenn der Normalzustand wiederhergestellt ist.
Schnelle Reaktionszeit: Neue Verbindungen werden an die Server mit der schnellsten Antwort weitergeleitet. Wenn einer der Server ausfällt, nimmt AX ihn aus der Serverwarteschlange und beteiligt sich erst dann an der Verteilung der nächsten Benutzeranforderung, wenn der Normalzustand wiederhergestellt ist.
Hash-Algorithmus (Hash): Hashen Sie die Quelladresse und den Port des Clients und leiten Sie das Ergebnis an einen einzelnen Server weiter Wenn einer der Server ausfällt, wird er aus der Serverwarteschlange entfernt und nimmt erst dann an der Verteilung der nächsten Benutzeranforderung teil, wenn der Normalzustand wiederhergestellt ist.
Paketbasierte Inhaltsverteilung: Wenn beispielsweise die HTTP-URL beurteilt wird, ob die URL die Erweiterung .jpg hat, dann das Paket wird an den angegebenen Server weitergeleitet.
Health Check
Health Check wird verwendet, um den Verfügbarkeitsstatus verschiedener vom Server geöffneter Dienste zu überprüfen. Lastausgleichsgeräte werden im Allgemeinen mit verschiedenen Methoden zur Gesundheitsprüfung konfiguriert, z. B. Ping, TCP, UDP, HTTP, FTP, DNS usw. Ping gehört zur dritten Ebene der Integritätsprüfung und wird zur Überprüfung der Konnektivität der Server-IP verwendet, während TCP/UDP zur vierten Ebene der Integritätsprüfung gehört und zur Überprüfung des UP/DOWN des Dienstports verwendet wird Genauer gesagt müssen Sie eine Integritätsprüfung auf Basis von Schicht 7 durchführen, beispielsweise eine HTTP-Integritätsprüfung erstellen, eine Seite zurückholen und prüfen, ob der Seiteninhalt eine bestimmte Zeichenfolge enthält. Wenn dies der Fall ist, ist der Dienst UP. Wenn die Seite nicht enthalten ist oder nicht abgerufen werden kann, wird davon ausgegangen, dass der Webdienst des Servers nicht verfügbar (DOWN) ist. Wenn das Lastausgleichsgerät beispielsweise erkennt, dass Port 80 des Servers 172.16.20.3 DOWN ist, leitet das Lastausgleichsgerät nachfolgende Verbindungen nicht an diesen Server weiter, sondern leitet die Datenpakete basierend auf dem Algorithmus an andere Server weiter. Beim Erstellen einer Integritätsprüfung können Sie das Prüfintervall und die Anzahl der Versuche festlegen. Wenn Sie beispielsweise das Intervall auf 5 Sekunden und die Anzahl der Versuche auf 3 festlegen, leitet das Lastausgleichsgerät alle 5 Sekunden eine Integritätsprüfung ein. Wenn die Prüfung fehlschlägt, wird es dreimal versucht. Wenn die Prüfung dreimal fehlschlägt, wird der Dienst als DOWN markiert und der Server überprüft dann weiterhin alle 5 Sekunden den Serverzustand Wenn der Server zu einem bestimmten Zeitpunkt wieder erfolgreich ist, wird er erneut für UP markiert. Das Intervall und die Anzahl der Gesundheitsprüfungsversuche sollten entsprechend der Gesamtsituation festgelegt werden. Der Grundsatz besteht darin, dass dies weder Auswirkungen auf das Geschäft hat noch eine große Belastung für die Lastausgleichsausrüstung darstellt.
Sitzungspersistenz
So stellen Sie sicher, dass zwei HTTP-Anfragen eines Benutzers an denselben Server weitergeleitet werden, was erfordert, dass das Lastausgleichsgerät die Sitzungspersistenz konfiguriert.
Sitzungspersistenz wird verwendet, um die Kontinuität und Konsistenz von Sitzungen aufrechtzuerhalten. Da es schwierig ist, Benutzerzugriffsinformationen in Echtzeit zwischen Servern zu synchronisieren, ist es erforderlich, die vorherigen und nachfolgenden Zugriffssitzungen des Benutzers zur Verarbeitung auf einem Server zu halten. Wenn ein Benutzer beispielsweise eine E-Commerce-Website besucht, verwaltet der erste Server die Anmeldung des Benutzers, der Kauf von Waren durch den Benutzer wird jedoch vom zweiten Server abgewickelt, da der zweite Server die Informationen des Benutzers nicht kennt erfolgreich sein. In diesem Fall muss die Sitzung aufrechterhalten werden und die Vorgänge des Benutzers müssen vom ersten Server verarbeitet werden, um erfolgreich zu sein. Natürlich erfordert nicht jeder Zugriff eine Sitzungswartung. Wenn der Server beispielsweise statische Seiten wie den Nachrichtenkanal der Website bereitstellt und jeder Server denselben Inhalt hat, ist für einen solchen Zugriff keine Sitzungswartung erforderlich.
Die meisten Lastausgleichsprodukte unterstützen zwei grundlegende Arten der Sitzungspersistenz: Quell-/Zieladressen-Sitzungspersistenz und Cookie-Sitzungspersistenz. Darüber hinaus sind Hash, URL-Persistenz usw. ebenfalls häufig verwendete Methoden, die jedoch nicht von allen Geräten unterstützt werden. Je nach Anwendung müssen unterschiedliche Sitzungsaufbewahrungen konfiguriert werden, andernfalls kommt es zu einem Lastungleichgewicht oder sogar zu Zugriffsausnahmen. Wir analysieren hauptsächlich die Sitzungswartung der B/S-Struktur.
Bewerbung basierend auf B/S-Struktur:
Für Anwendungsinhalte mit gewöhnlicher B/S-Struktur, wie z. B. statische Seiten von Websites, müssen Sie keine Sitzungspersistenz konfigurieren. Für ein Geschäftssystem, das auf einer B/S-Struktur basiert, insbesondere eine Middleware-Plattform, muss jedoch eine Sitzungspersistenz konfiguriert werden konfiguriert werden. Unter normalen Umständen konfigurieren wir die Aufbewahrung von Quelladressensitzungen entsprechend den Anforderungen. Da der Client jedoch möglicherweise über die oben genannte Umgebung verfügt, die der Aufbewahrung von Quelladressensitzungen nicht förderlich ist, ist die Verwendung von Cookie-Sitzungsaufbewahrung eine bessere Möglichkeit. Durch die Cookie-Sitzungspersistenz werden die vom Lastausgleichsgerät ausgewählten Serverinformationen in einem Cookie gespeichert und an den Client gesendet. Wenn der Client den Besuch fortsetzt, wird das Cookie vom Lastausgleichsmodul analysiert, um die Sitzung aufrechtzuerhalten ausgewählten Server. Cookies werden in Datei-Cookies und Speicher-Cookies unterteilt. Sie werden auf der Festplatte des Client-Computers gespeichert. Solange die Cookie-Datei nicht abläuft, kann sie auf demselben Server gespeichert werden, unabhängig davon, ob der Browser wiederholt geschlossen wird nicht. Speichercookies speichern Cookie-Informationen im Speicher. Die Lebensdauer des Cookies beginnt mit dem Öffnen des Browsers und endet mit dem Schließen des Browsers. Da aktuelle Browser über bestimmte Standardsicherheitseinstellungen für Cookies verfügen, kann es sein, dass einige Clients festlegen, dass die Verwendung von Dateicookies nicht zulässig ist, sodass in der aktuellen Anwendungsentwicklung hauptsächlich Speichercookies verwendet werden.
Speichercookies sind jedoch nicht allmächtig. Beispielsweise kann der Browser Cookies aus Sicherheitsgründen vollständig deaktivieren, sodass die Speicherung von Cookies ihre Wirkung verliert. Wir können Sitzungspersistenz durch Sitzungs-ID erreichen, das heißt, Sitzungs-ID als URL-Parameter verwenden oder in ein verstecktes Feld <input type="hidden"> einfügen und dann die Sitzungs-ID zur Verteilung analysieren.
Eine andere Lösung besteht darin, jede Sitzungsinformation in einer Datenbank zu speichern. Da diese Lösung die Belastung der Datenbank erhöht, ist sie nicht geeignet, die Leistung zu verbessern. Die Datenbank eignet sich am besten zum Speichern von Sitzungsdaten für längere Sitzungen. Um Single Points of Failure in der Datenbank zu vermeiden und ihre Skalierbarkeit zu verbessern, wird die Datenbank in der Regel auf mehreren Servern repliziert und Anfragen werden über einen Load Balancer an die Datenbankserver verteilt.
Die Verwendung einer auf Quell-/Zieladresse basierenden Sitzungspersistenz ist nicht sehr einfach, da Kunden möglicherweise über DHCP, NAT oder einen Web-Proxy eine Verbindung zum Internet herstellen und sich ihre IP-Adressen häufig ändern, wodurch die Servicequalität dieser Lösung nicht gewährleistet ist.
NAT (Network Address Translation, Network Address Translation) : Wenn einigen Hosts im privaten Netzwerk lokale IP-Adressen zugewiesen wurden (d. h. private Adressen, die nur innerhalb dieses privaten Netzwerks verwendet werden), aber jetzt wann Wenn Sie mit einem Host im Internet (unverschlüsselt) kommunizieren möchten, können Sie das NAT-Verfahren nutzen. Für diese Methode muss eine NAT-Software auf dem Router installiert sein, der das private Netzwerk mit dem Internet verbindet. Ein mit NAT-Software ausgestatteter Router wird als NAT-Router bezeichnet und verfügt über mindestens eine gültige externe globale IP-Adresse. Wenn also alle Hosts, die lokale Adressen verwenden, mit der Außenwelt kommunizieren, müssen ihre lokalen Adressen auf dem NAT-Router in globale IP-Adressen umgewandelt werden, bevor sie eine Verbindung zum Internet herstellen können.
Weitere Vorteile des Lastausgleichs
Hohe Skalierbarkeit
Durch das Hinzufügen oder Reduzieren der Anzahl von Servern können Sie hohe gleichzeitige Anforderungen besser bewältigen.
(Server) Health Check
Der Load Balancer kann den Zustand der Back-End-Server-Anwendungsschicht überprüfen und ausgefallene Server aus dem Serverpool entfernen, um die Zuverlässigkeit zu verbessern.
TCP-Verbindungswiederverwendung
Die TCP-Verbindungswiederverwendungstechnologie multiplext HTTP-Anfragen von mehreren Clients am Front-End in einer TCP-Verbindung, die zwischen dem Back-End und dem Server hergestellt wird. Diese Technologie kann die Leistungslast des Servers erheblich reduzieren, die durch neue TCP-Verbindungen mit dem Server verursachte Verzögerung verringern, die Anzahl gleichzeitiger Verbindungsanforderungen vom Client an den Back-End-Server minimieren und die Ressourcenbelegung des Servers reduzieren.
Im Allgemeinen muss der Client vor dem Senden einer HTTP-Anfrage einen TCP-Drei-Wege-Handshake mit dem Server durchführen, eine TCP-Verbindung herstellen und dann die HTTP-Anfrage senden. Der Server verarbeitet die HTTP-Anfrage nach dem Empfang und sendet das Verarbeitungsergebnis an den Client zurück. Anschließend senden der Client und der Server einander FIN und schließen die Verbindung, nachdem sie die ACK-Bestätigung des FIN erhalten haben. Auf diese Weise erfordert eine einfache HTTP-Anfrage die Verarbeitung von mehr als einem Dutzend TCP-Paketen.
Nach der Verwendung der TCP-Verbindungswiederverwendungstechnologie wird ein Drei-Wege-Handshake zwischen dem Client (z. B. ClientA) und dem Lastausgleichsgerät durchgeführt und eine HTTP-Anfrage gesendet. Nach Erhalt der Anfrage erkennt das Lastausgleichsgerät, ob auf dem Server eine lange Verbindung im Leerlauf vorhanden ist. Wenn keine Verbindung vorhanden ist, stellt der Server eine neue Verbindung her. Wenn die HTTP-Anforderungsantwort abgeschlossen ist, verhandelt der Client mit dem Lastausgleichsgerät, um die Verbindung zu schließen, und der Lastausgleich hält die Verbindung mit dem Server aufrecht. Wenn ein anderer Client (z. B. ClientB) eine HTTP-Anfrage senden muss, sendet das Lastausgleichsgerät die HTTP-Anfrage direkt an die inaktive Verbindung mit dem Server und vermeidet so die durch die neue TCP-Verbindung verursachte Verzögerung und den Serverressourcenverbrauch. 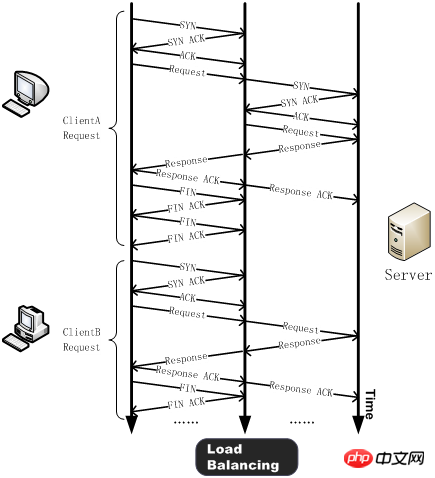
In HTTP 1.1 kann der Client mehrere HTTP-Anfragen in einer TCP-Verbindung senden. Diese Technologie wird HTTP-Multiplexing genannt. Der grundlegendste Unterschied zum TCP-Verbindungsmultiplexing besteht darin, dass beim TCP-Verbindungsmultiplexing HTTP-Anforderungen von mehreren Clients an eine serverseitige TCP-Verbindung gemultiplext werden, während beim HTTP-Multiplexing mehrere HTTP-Anforderungen von einem Client über eine TCP-Verbindung gemultiplext werden verarbeitet wird. Ersteres ist eine einzigartige Funktion des Lastausgleichsgeräts; letzteres ist eine neue Funktion, die vom HTTP 1.1-Protokoll unterstützt wird und derzeit von den meisten Browsern unterstützt wird.
HTTP-Cache
Load Balancer können statische Inhalte speichern und direkt auf Benutzer reagieren, wenn sie diese anfordern, ohne Backend-Server anfordern zu müssen.
TCP-Pufferung
TCP-Pufferung soll das Problem der Verschwendung von Serverressourcen lösen, das durch die Diskrepanz zwischen der Netzwerkgeschwindigkeit des Back-End-Servers und der Front-End-Netzwerkgeschwindigkeit des Kunden verursacht wird. Die Verbindung zwischen dem Client und dem Load Balancer weist eine hohe Latenz und geringe Bandbreite auf, während die Verbindung zwischen dem Load Balancer und dem Server eine LAN-Verbindung mit geringer Latenz und hoher Bandbreite verwendet. Da der Load Balancer die Antwortdaten des Backend-Servers an Kunden vorübergehend speichern und diese dann an Kunden mit längeren Antwortzeiten und langsameren Netzwerkgeschwindigkeiten weiterleiten kann, kann der Backend-Webserver die entsprechenden Threads für andere Aufgaben freigeben.
SSL-Beschleunigung
Unter normalen Umständen wird HTTP im Klartext im Netzwerk übertragen, was illegal abgehört werden kann, insbesondere die zur Authentifizierung verwendeten Passwortinformationen. Um solche Sicherheitsprobleme zu vermeiden, wird im Allgemeinen das SSL-Protokoll (d. h. HTTPS) zur Verschlüsselung des HTTP-Protokolls verwendet, um die Sicherheit des gesamten Übertragungsprozesses zu gewährleisten. Bei der SSL-Kommunikation wird zunächst die asymmetrische Schlüsseltechnologie zum Austausch von Authentifizierungsinformationen verwendet. Anschließend wird der Sitzungsschlüssel zum Verschlüsseln von Daten zwischen dem Server und dem Browser ausgetauscht. Anschließend wird der Schlüssel zum Ver- und Entschlüsseln der Informationen während des Kommunikationsprozesses verwendet.
SSL ist eine Sicherheitstechnologie, die viele CPU-Ressourcen verbraucht. Derzeit verwenden die meisten Load-Balancing-Geräte SSL-Beschleunigungschips (Hardware-Load-Balancer), um SSL-Informationen zu verarbeiten. Diese Methode bietet eine höhere SSL-Verarbeitungsleistung als die herkömmliche serverbasierte SSL-Verschlüsselungsmethode, wodurch eine große Menge an Serverressourcen eingespart wird und der Server sich auf die Verarbeitung von Geschäftsanfragen konzentrieren kann. Darüber hinaus kann eine zentralisierte SSL-Verarbeitung auch die Verwaltung von Zertifikaten vereinfachen und den Arbeitsaufwand für die tägliche Verwaltung verringern.
Inhaltsfilterung
Einige Load Balancer können die durch sie geleiteten Daten nach Bedarf ändern.
Intrusion-Prevention-Funktion
Auf der Grundlage der Firewall, die die Sicherheit der Netzwerkschicht/Transportschicht gewährleistet, bietet sie auch Sicherheit auf der Anwendungsschicht.
Klassifizierung
Im Folgenden wird die Implementierung des Lastausgleichs auf verschiedenen Ebenen erläutert:
DNS-Lastausgleich
DNS ist für die Bereitstellung von Diensten zur Auflösung von Domainnamen verantwortlich. Beim Zugriff auf eine bestimmte Site müssen Sie zunächst die IP-Adresse, auf die der Domänenname verweist, über den DNS-Server des Domänennamens der Site abrufen. Bei diesem Vorgang schließt der DNS-Server die Zuordnung des Domänennamens zur IP-Adresse ab In ähnlicher Weise kann diese Zuordnung auch eine Eins-zu-Viele-Zuordnung sein. Zu diesem Zeitpunkt fungiert der DNS-Server als Lastausgleichsplaner und verteilt Benutzeranforderungen an mehrere Server. Verwenden Sie den Befehl dig, um einen Blick auf die DNS-Einstellungen von „baidu“ zu werfen: 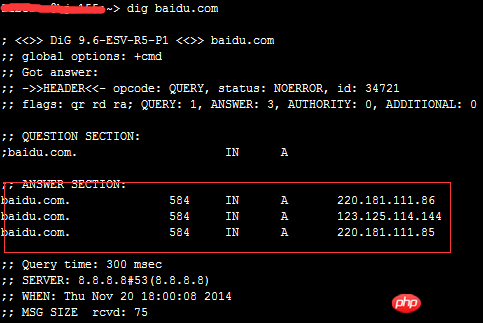
Es ist ersichtlich, dass Baidu drei A-Einträge hat.
Die Vorteile dieser Technologie bestehen darin, dass sie einfach zu implementieren, leicht zu implementieren und kostengünstig ist, für die meisten TCP/IP-Anwendungen geeignet ist und der DNS-Server unter allen verfügbaren A den Server finden kann, der dem Benutzer am nächsten liegt Aufzeichnungen. Die Mängel sind jedoch auch sehr offensichtlich. Erstens ist diese Lösung kein Lastausgleich im eigentlichen Sinne. Der DNS-Server verteilt HTTP-Anfragen gleichmäßig an die Hintergrund-Webserver (oder entsprechend dem geografischen Standort). Wenn die Konfigurations- und Verarbeitungsfunktionen der Backend-Webserver unterschiedlich sind, wird der langsamste Webserver zum Flaschenhals des Systems, und der Server mit den starken Verarbeitungsfunktionen kann zweitens seine Rolle nicht vollständig erfüllen Wird nicht berücksichtigt, wenn ein bestimmter Webserver im Hintergrund ausfällt, weist der DNS-Server weiterhin DNS-Anfragen an diesen ausgefallenen Server zu, was dazu führt, dass der Client nicht antworten kann. Der letzte Punkt ist fatal. Er kann dazu führen, dass eine beträchtliche Anzahl von Kunden die Webdienste nicht nutzen können, und aufgrund des DNS-Cachings werden die Folgen über einen langen Zeitraum anhalten (der allgemeine Aktualisierungszyklus von DNS beträgt etwa 24 Stunden). . Daher wird diese Lösung in den neuesten Website-Lösungen ausländischer Bauzentren selten verwendet.
Lastausgleich der Verbindungsschicht (OSI-Schicht 2)
Ändern Sie die MAC-Adresse in der Datenverbindungsschicht des Kommunikationsprotokolls für den Lastausgleich.
Ändern Sie beim Verteilen von Daten nicht die IP-Adresse (da die IP-Adresse noch nicht sichtbar ist), ändern Sie nur die Ziel-Mac-Adresse und konfigurieren Sie alle virtuellen IPs des Back-End-Servers so, dass sie mit der IP-Adresse des Lastenausgleichs konsistent sind. damit die Quelladresse und Zieladresse des Datenpakets zum Zweck der Datenverteilung nicht verändert werden.
Die tatsächliche IP des Verarbeitungsservers stimmt mit der Ziel-IP der Datenanforderung überein. Es ist nicht erforderlich, den Lastausgleichsserver zur Adressübersetzung zu durchlaufen. Das Antwortdatenpaket kann direkt an den Browser des Benutzers zurückgegeben werden, um den Lastausgleichsserver zu umgehen Die Bandbreite der Netzwerkkarte wird zum Engpass. Wird auch als Direct-Routing-Modus (DR-Modus) bezeichnet. Wie unten gezeigt: 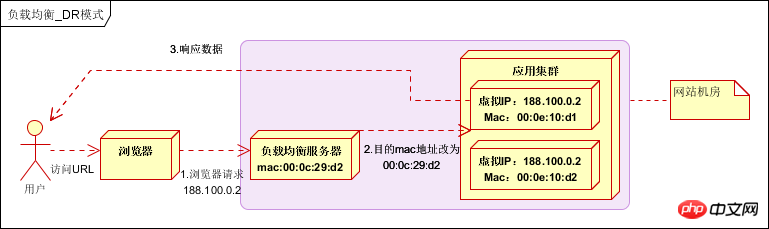
Die Leistung ist sehr gut, aber die Konfiguration ist kompliziert und wird derzeit häufig verwendet.
Transportschicht (OSI-Schicht 4) Lastausgleich
Die Transportschicht ist OSI-Schicht 4, einschließlich TCP und UDP. Beliebte Load-Balancer der Transportschicht sind HAProxy (dieser wird auch für den Lastausgleich der Anwendungsschicht verwendet) und IPVS.
Der endgültig ausgewählte interne Server wird hauptsächlich durch die Zieladresse und den Port in der Nachricht sowie die vom Lastausgleichsgerät festgelegte Serverauswahlmethode bestimmt.
Am Beispiel des üblichen TCP: Wenn das Lastausgleichsgerät die erste SYN-Anfrage vom Client empfängt, wählt es mit der oben genannten Methode den besten Server aus und ändert die Ziel-IP-Adresse in der Nachricht (geändert in Backend-Server-IP). direkt an den Server weitergeleitet. Der TCP-Verbindungsaufbau, dh der Drei-Wege-Handshake, wird direkt zwischen dem Client und dem Server hergestellt, und das Lastausgleichsgerät fungiert nur als Router-ähnliche Weiterleitungsaktion. Um sicherzustellen, dass das vom Server zurückgegebene Paket korrekt an das Lastausgleichsgerät zurückgegeben werden kann, kann in einigen Bereitstellungssituationen die ursprüngliche Quelladresse des Pakets während der Weiterleitung des Pakets geändert werden. 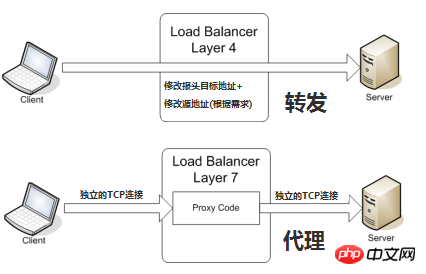
Lastausgleich der Anwendungsschicht (OSI-Schicht 7)
Die Anwendungsschicht ist OSI-Schicht 7. Es umfasst HTTP, HTTPS und WebSockets. Ein sehr beliebter und bewährter Load Balancer für die Anwendungsschicht ist Nginx [Engine X = Engine X].
Der sogenannte siebenschichtige Lastausgleich, auch „Content Switching“ genannt, basiert hauptsächlich auf der Bestimmung des wirklich sinnvollen Inhalts der Anwendungsschicht in der Nachricht, gepaart mit der vom Lastausgleichsgerät festgelegten Serverauswahlmethode die endgültige interne Auswahl. Beachten Sie, dass Sie zu diesem Zeitpunkt die vollständige URL der spezifischen http-Anfrage sehen können, sodass die in der folgenden Abbildung gezeigte Verteilung erreicht werden kann: 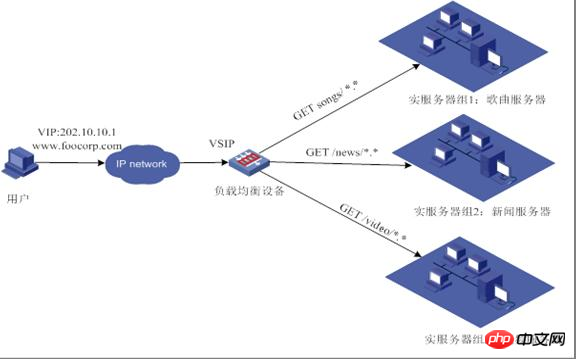
Nehmen wir als Beispiel allgemeines TCP Das Lastausgleichsgerät möchte auf dem tatsächlichen Inhalt der Anwendungsschicht basieren und dann den Server auswählen, der erst angezeigt werden kann, nachdem der Server und der Client endgültig eine Verbindung hergestellt haben (Drei-Wege-Handshake), und dann den tatsächlichen Inhalt der Anwendungsschicht melden Das vom Client gesendete Feld bestimmt in Kombination mit der vom Lastausgleichsgerät festgelegten Serverauswahlmethode die endgültige Auswahl des internen Servers. Das Lastausgleichsgerät ähnelt in diesem Fall eher einem Proxyserver. Der Lastausgleich sowie die Front-End-Clients und Back-End-Server stellen jeweils TCP-Verbindungen her. Aus der Sicht dieses technischen Prinzips stellt der siebenschichtige Lastausgleich offensichtlich höhere Anforderungen an die Lastausgleichsausrüstung, und die Fähigkeit, sieben Schichten zu verarbeiten, wird zwangsläufig geringer sein als bei der Bereitstellungsmethode im vierschichtigen Modus. Warum brauchen wir also einen Layer-7-Lastausgleich?
Der Vorteil des Lastausgleichs auf sieben Ebenen besteht darin, das gesamte Netzwerk „intelligenter“ zu machen. Die meisten der oben aufgeführten Vorteile des Lastausgleichs basieren beispielsweise auf dem Lastausgleich auf sieben Ebenen. Beispielsweise kann der Benutzerverkehr, der eine Website besucht, Anfragen nach Bildern an einen bestimmten Bildserver weiterleiten und mithilfe des Sieben-Schichten-Ansatzes können Anfragen nach Text an einen bestimmten Textserver weitergeleitet werden, und es kann eine Komprimierungstechnologie verwendet werden. Dies ist natürlich nur ein kleiner Fall einer siebenschichtigen Anwendung. Aus technischer Sicht kann diese Methode die Anfrage des Clients und die Antwort des Servers in jeder Hinsicht ändern und so die Flexibilität des Anwendungssystems auf der Netzwerkebene erheblich verbessern.
Ein weiteres häufig erwähntes Merkmal ist die Sicherheit. Der häufigste SYN-Flood-Angriff im Netzwerk besteht darin, dass Hacker viele Quell-Clients kontrollieren und falsche IP-Adressen verwenden, um SYN-Angriffe an dasselbe Ziel zu senden. Normalerweise sendet dieser Angriff eine große Anzahl von SYN-Nachrichten und erschöpft damit verbundene Ressourcen auf dem Server Denial-of-Service (DoS)-Zweck erreichen. Aus den technischen Prinzipien ist auch ersichtlich, dass diese SYN-Angriffe im Vierschichtmodus an den Back-End-Server weitergeleitet werden und im Siebenschichtmodus diese SYN-Angriffe natürlich auf dem Lastausgleichsgerät enden hat keinen Einfluss auf den normalen Betrieb des Back-End-Servers. Darüber hinaus kann das Lastausgleichsgerät mehrere Richtlinien auf der siebenschichtigen Ebene festlegen, um bestimmte Nachrichten zu filtern, z. B. SQL-Injection und andere Angriffsmethoden auf Anwendungsebene, um die Gesamtsystemsicherheit auf Anwendungsebene weiter zu verbessern.
Der aktuelle siebenschichtige Lastausgleich konzentriert sich hauptsächlich auf das weit verbreitete HTTP-Protokoll, sodass sein Anwendungsbereich hauptsächlich auf B/S-basierten Systemen wie zahlreichen Websites oder internen Informationsplattformen liegt. Der Layer-4-Lastausgleich entspricht anderen TCP-Anwendungen, wie ERP und anderen auf C/S basierenden Systemen.
Verwandte Empfehlungen:
Zusammenfassung der zu beachtenden Punkte zu verteilten Clustern
Das obige ist der detaillierte Inhalt vonWas sind die Unterschiede zwischen Clustering, Verteilung und Lastausgleich? (Bilder und Text). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)