
Heim >Datenbank >MySQL-Tutorial >Das zugrunde liegende Implementierungsprinzip des MySQL-Index
Das zugrunde liegende Implementierungsprinzip des MySQL-Index

- 无忌哥哥Original
- 2018-07-12 10:14:291522Durchsuche
Die Datenstruktur und die Algorithmusprinzipien hinter MySQL-Indizes
1. Indexdefinition: Index (Index) soll MySQL helfen effizient sein Holen Sie sich die Datenstruktur der Daten. Essenz: Der Index ist eine Datenstruktur.
2. B-Baum
M-Ordnung B-Baum erfüllt die folgenden Bedingungen: 1. Jeder Knoten kann höchstens m Teilbäume haben.
2. Der Wurzelknoten hat nur mindestens 2 Knoten (oder im Extremfall hat ein Baum nur einen Wurzelknoten, ein einzelliger Organismus ist eine Wurzel, ein Blatt und ein Baum).3. Nicht-Wurzel- und Nicht-Blattknoten haben mindestens Ceil (m/2) Teilbäume (Ceil bedeutet Aufrunden, wie zum Beispiel ein B-Baum 5. Ordnung, jeder Knoten hat mindestens 3 Teilbäume, d. h. es gibt mindestens 3 Gabeln).
4. Die Informationen in Nicht-Blattknoten umfassen [n,A0,K1,A1,K2,A2,…,Kn,An], wobei n die Anzahl der im Knoten gespeicherten Schlüsselwörter darstellt und K das Schlüsselwort ist Und Ki
B-Tree-Funktionen:
1. Der Schlüsselwortsatz ist im gesamten Baum verteilt; ein Nicht-Blattknoten; 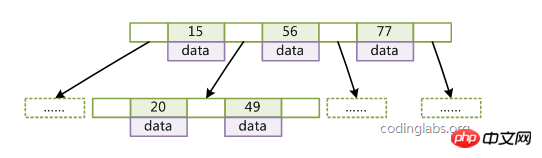 5. Die Schlüssel in einem Knoten sind von links nach rechts nicht abnehmend angeordnet;
5. Die Schlüssel in einem Knoten sind von links nach rechts nicht abnehmend angeordnet;
Der Pseudocode des Suchalgorithmus auf B-Tree lautet wie folgt:
 Der Unterschied zwischen B+Tree und B-Tree ist:
Der Unterschied zwischen B+Tree und B-Tree ist:
Alle Schlüsselwörter werden gespeichert auf Blattknoten; 3. Jeder Blattknoten enthält einen Zeiger auf den benachbarten Blattknoten. und enthält nur das größte (oder kleinste) Schlüsselwort in seinem Unterbaum (Wurzelknoten);
 4. Leistungsanalyse des B/B+-Baumindex
4. Leistungsanalyse des B/B+-Baumindex
Basis : Verwenden Sie die Anzahl der Festplatten-E/As, um die Qualität der Indexstruktur zu bewerten
Hauptspeicher und Festplattenaustauschdaten in Seiteneinheiten. Stellen Sie die Größe eines Knotens auf eine Seite ein, sodass jeder Knoten nur eine E/A benötigt . Voll beladen.
Gemäß der Definition des B-Baums ist ersichtlich, dass für einen Abruf auf maximal h Knoten zugegriffen werden muss
Asymptotische Komplexität: O(h)=O(logdN)
dmax=floor (pagesize/(keysize+datasize+pointsize) )
Einmal im B-Tree-Abruf erfordert höchstens h-1 I/O (Wurzelknoten-residenter Speicher) Die Knoten im B+Tree enthalten keine Datenfelder, daher der Out-Grad Je größer d, desto kleiner ist h, desto geringer ist die Anzahl der E/A und desto höher ist die Effizienz. Daher eignet sich B+Tree besser für externe Speicherindizes.
5. MySQL-Indeximplementierung
1. Das Datenfeld des Blattknotens speichert die Adresse > MyISAM main Es gibt keinen strukturellen Unterschied zwischen dem Index und dem Hilfsindex, außer dass der Schlüssel des Primärindex eindeutig sein muss, während der Schlüssel des Hilfsindex wiederholt werden kann.
2 InnoDB selbst ist die Indexdatei, und der Blattknoten enthält die vollständigen Datensätze. Dieser Index wird als Clustered-Index bezeichnet.
Da die Datendateien von InnoDB selbst nach Primärschlüssel aggregiert werden, erfordert InnoDB, dass die Tabelle einen Primärschlüssel haben muss (MyISAM benötigt diesen nicht, wenn er nicht explizit angegeben wird, wählt das MySQL-System automatisch eine Spalte aus, die den eindeutig identifizieren kann). Wenn eine solche Spalte nicht vorhanden ist, generiert MySQL automatisch ein implizites Feld als Primärschlüssel für die InnoDB-Tabelle.
Das Hilfsindexdatenfeld von InnoDB speichert den Wert des Primärschlüssels des entsprechenden Datensatzes anstelle der Adresse.
Die Hilfsindexsuche muss den Index zweimal abrufen: Rufen Sie zuerst den Hilfsindex ab, um den Primärschlüssel zu erhalten Verwenden Sie dann den Primärschlüssel, um den Datensatz im Primärindex abzurufen Der Datensatz wird nacheinander in die Seite eingefügt. Fahren Sie mit dem Einfügen in eine neue Seite fort.
Wenn die Schreibvorgänge nicht in der richtigen Reihenfolge sind, muss InnoDB häufig Seitenaufteilungen durchführen, um Platz für neue Zeilen zu reservieren. Durch die Seitenaufteilung werden große Datenmengen verschoben; bei einer Einfügung müssen mindestens drei Seiten statt einer geändert werden. Wenn Seiten häufig geteilt werden, werden die Seiten spärlich und unregelmäßig gefüllt, sodass die Daten schließlich fragmentiert werden.
Das Verständnis der Indeximplementierungsmethoden verschiedener Speicher-Engines ist für die korrekte Verwendung und Optimierung von Indizes sehr hilfreich
2. Warum ein Auto-Inkrement-Feld als Primärschlüssel wählen?
3. Warum wird nicht empfohlen, einen Index für Felder zu erstellen, die häufig aktualisiert werden?
4. Warum eine stark differenzierte Spalte als Index wählen? Die Unterscheidungsformel lautet count(distinct col)/count(*)
Verwenden Sie den abdeckenden Index so weit wie möglich
7. Optimieren Sie die LIMIT-Paging-Abfrage.
SELECT * FROM table where condition LIMIT offset , rows ;
Der Implementierungsmechanismus der obigen SQL-Anweisung ist:
1. Offset+Zeilenzeilendatensätze aus der Tabelle „Tabelle“ lesen.
2. Verwerfen Sie die vorherigen versetzten Zeilendatensätze und geben Sie die Zeilendatensätze der nachfolgenden Zeilen als Endergebnis zurück.
Abgedeckter Index:
select a.id, sid, parent_s_id from cashpool_account_relationship a join (select id from cashpool_account_relationship LIMIT 1000000,10)b on a.id = b.id; select id, sid, parent_s_id from cashpool_account_relationship where id >=(select id from cashpool_account_relationship LIMIT 1000000,1) LIMIT 10;
8. Unterstützt InnoDB einen Hash-Index? --Ma in einer Tabelle. 2. Die Blattknoten des InnoDB-Primärschlüsselindex enthalten vollständige Datensätze. Ist die Primärschlüsselindexdatei größer als die Datendatei? --Xu Caihou
1). In der Innodb-Engine enthalten die Blattknoten im Primärschlüsselindex Datensatzdaten, und die Primärschlüsselindexdatei ist die Datendatei.2). Die in der Tabellentabelle gezählten data_length-Daten sind die Primärschlüsselindexgröße und index_length ist die gezählte Größe aller Hilfsindizes (Sekundärindizes) in dieser Tabelle.
Das obige ist der detaillierte Inhalt vonDas zugrunde liegende Implementierungsprinzip des MySQL-Index. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!