
Heim >Datenbank >MySQL-Tutorial >Verwendung von EXISTS in SQL
Verwendung von EXISTS in SQL
- jackloveOriginal
- 2018-06-14 16:54:552970Durchsuche
Zum Beispiel gibt es in der Northwind-Datenbank eine Abfrage wie
SELECT c.CustomerId,CompanyName FROM Customers c
WHERE EXISTS(
SELECT OrderID FROM Orders o WHERE o.CustomerID=c.CustomerID)
Wie funktioniert EXISTS hier? Die Unterabfrage gibt das Feld OrderId zurück, aber die externe Abfrage sucht nach den Feldern CustomerID und CompanyName. Diese beiden Felder sind definitiv nicht in der OrderID enthalten.
EXISTS wird verwendet, um zu prüfen, ob die Unterabfrage mindestens eine Datenzeile zurückgibt. Die Unterabfrage gibt tatsächlich keine Daten zurück, sondern gibt True oder False zurück.
EXISTS gibt eine Unterabfrage an, um das Vorhandensein von Zeilen zu erkennen.
Syntax: EXISTS-Unterabfrage
Parameter: Unterabfrage ist eine eingeschränkte SELECT-Anweisung (COMPUTE-Klausel und INTO-Schlüsselwort sind nicht zulässig).
Ergebnistyp: Boolean Gibt TRUE zurück, wenn die Unterabfrage Zeilen enthält, andernfalls FLASE.
| Beispieltabelle A: TableIn | Beispieltabelle B: TableEx | ||||
|
|
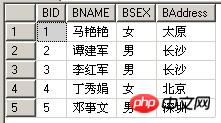 |
(1) Die Verwendung von NULL in der Unterabfrage gibt weiterhin die Ergebnismenge
select * from TableIn where exists(select null) 等同于: select * from TableIn

(2) zurück. Beachten Sie, dass beide Abfragen die gleichen Ergebnisse zurückgeben.
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME) select * from TableIn where ANAME in(select BNAME from TableEx)
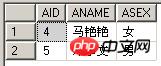
(3) Vergleichen Sie Abfragen mit EXISTS und = ANY. Beachten Sie, dass beide Abfragen die gleichen Ergebnisse zurückgeben.
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME) select * from TableIn where ANAME=ANY(select BNAME from TableEx)
NOT EXISTS macht genau das Gegenteil von EXISTS. Wenn die Unterabfrage keine Zeilen zurückgibt, ist die WHERE-Klausel in NOT EXISTS erfüllt.
Fazit:
Der Rückgabewert der EXISTS-Klausel (einschließlich NOT EXISTS) ist ein BOOL-Wert. Innerhalb von EXISTS gibt es eine Unterabfrageanweisung (SELECT ... FROM...), die ich die innere Abfrageanweisung von EXIST nenne. Die darin enthaltene Abfrageanweisung gibt eine Ergebnismenge zurück. Die EXISTS-Klausel gibt einen booleschen Wert zurück, basierend darauf, ob die Ergebnismenge der darin enthaltenen Abfrageanweisung leer oder nicht leer ist.
Eine beliebte Möglichkeit, dies zu verstehen, ist: Ersetzen Sie jede Zeile der äußeren Abfragetabelle als Test durch die innere Abfrage. Wenn das von der inneren Abfrage zurückgegebene Ergebnis ein Nicht-Null-Wert ist, gibt die EXISTS-Klausel TRUE zurück . Diese Zeile kann als Ergebniszeile der äußeren Abfrage verwendet werden, andernfalls kann sie nicht als Ergebnis verwendet werden.
Der Analysator prüft zunächst das erste Wort der Anweisung. Wenn er feststellt, dass das erste Wort das Schlüsselwort SELECT ist, springt er zum Schlüsselwort FROM, sucht dann den Tabellennamen über das Schlüsselwort FROM und gibt ihn ein Die Tabelle wird in den Speicher geladen. Der nächste Schritt besteht darin, nach dem Schlüsselwort WHERE zu suchen. Wenn es nicht gefunden wird, kehrt es zu SELECT zurück, um die Feldanalyse zu finden Analysieren Sie das Feld. Abschließend wird eine virtuelle Tabelle gebildet.
Was auf das Schlüsselwort WHERE folgt, ist ein bedingter Ausdruck. Nachdem der bedingte Ausdruck berechnet wurde, gibt es einen Rückgabewert, der ungleich Null oder 0 ist. Ungleich Null bedeutet wahr (wahr) und 0 bedeutet falsch (falsch). Auf die gleiche Weise hat auch die Bedingung nach WHERE einen Rückgabewert, wahr oder falsch, um zu bestimmen, ob als nächstes SELECT ausgeführt werden soll.
Der Analysator findet zuerst das Schlüsselwort SELECT, springt dann zum Schlüsselwort FROM, um die STUDENT-Tabelle in den Speicher zu importieren, findet den ersten Datensatz über den Zeiger und findet dann das Schlüsselwort WHERE, um seinen bedingten Ausdruck zu berechnen true, dann werden diese Datensätze in eine virtuelle Tabelle geladen und der Zeiger zeigt auf den nächsten Datensatz. Bei „false“ zeigt der Zeiger direkt auf den nächsten Datensatz, ohne dass andere Vorgänge ausgeführt werden. Rufen Sie immer die gesamte Tabelle ab und geben Sie die abgerufene virtuelle Tabelle an den Benutzer zurück. EXISTS ist Teil eines bedingten Ausdrucks, der auch einen Rückgabewert (wahr oder falsch) hat.
Bevor Sie einen Datensatz einfügen, müssen Sie prüfen, ob der Datensatz bereits vorhanden ist. Der Einfügevorgang wird nur ausgeführt, wenn der Datensatz nicht vorhanden ist. Sie können das Einfügen doppelter Datensätze verhindern, indem Sie die bedingte Anweisung EXISTS verwenden.
INSERT INTO TableIn (ANAME,ASEX)
SELECT top 1 '张三', '男' FROM TableIn
WHERE not existed (select * from TableIn where TableIn.AID = 7)
Was die Nutzungseffizienz von EXISTS und IN angeht, ist die Verwendung von „exists“ im Allgemeinen effizienter als die von „in“, da IN keine Indizes verwendet. Die spezifische Verwendung hängt jedoch von der tatsächlichen Situation ab:
IN eignet sich für Situationen, in denen das Äußere vorhanden ist Der Tisch ist groß und der Innentisch ist klein; EXISTS eignet sich für Situationen, in denen das Erscheinungsbild klein, der Innenraum jedoch groß ist.
Der Unterschied zwischen in, nicht in, existiert und nicht existiert:
Lass uns zunächst über den Unterschied zwischen sprechen in und existiert :
exists: existiert, normalerweise gefolgt von einer Unterabfrage. Wenn die Unterabfrage die Anzahl der Zeilen zurückgibt, gibt „exists“ „true“ zurück.
wählen Sie * aus der Klasse aus, in der vorhanden ist (select'x"form stu where stu.cid=class.cid)
Wenn in und exist im Hinblick auf die Abfrageeffizienz verglichen werden, ist die Effizienz der in-Abfrage schneller als die der Abfrage Effizienz von exists
Die Unterabfrage nach exists(xxxxx) wird als korrelierte Unterabfrage bezeichnet. Sie gibt nicht den Wert der Liste zurück
gibt nur ein wahres oder falsches Ergebnis zurück (aus diesem Grund wird „x“ ausgewählt subquery Der Grund kann natürlich auch
alles auswählen) Das heißt, es kommt nur darauf an, ob die Daten in Klammern gefunden werden können und ob ein solcher Datensatz vorhanden ist.
Die Funktionsweise besteht darin, zuerst die Hauptabfrage auszuführen und dann die entsprechenden Ergebnisse in der Unterabfrage abzufragen. Wenn sie vorhanden ist und „true“ zurückgegeben wird,
wird ausgegeben und umgekehrt. Wenn false zurückgegeben wird, erfolgt keine Ausgabe, und die Unterabfrage wird dann basierend auf jeder Zeile in der Hauptabfrage abgefragt >Die Ausführungssequenz ist wie folgt: 1. Führen Sie zuerst eine externe Abfrage aus
2. Führen Sie eine Unterabfrage für jede Zeile in der externen Abfrage aus, und jedes Mal, wenn die Unterabfrage ausgeführt wird, wird sie auf die Zeit verweisen in der externen Abfrage
Der Wert der vorherigen Zeile. 3. Verwenden Sie die Ergebnisse der Unterabfrage, um die Ergebnismenge der äußeren Abfrage zu bestimmen.
Eine Unterabfrage.
in: Enthält Jungen im gleichen Alter wie alle Mädchen abfragen
wählen Sie * aus Stu, wobei Geschlecht='männlich' und Alter in( select age from stu where sex='female') Die Unterabfrage nachin() gibt die Ergebnismenge zurück. Mit anderen Worten, die Ausführungsreihenfolge unterscheidet sich von der von exist(). Die Unterabfrage generiert zuerst die Ergebnismenge und dann geht die Hauptabfrage zur Ergebnismenge, um eine Liste von Feldern zu finden, die die Anforderungen erfüllen. Andernfalls wird sie nicht ausgegeben >
not in und not Der Unterschied zwischen existiert:
not in Verwenden Sie not in nur, wenn das Feld nach dem Schlüsselwort select in der Unterabfrage eine Nicht-Null-Einschränkung hat oder eine solche aufweist Hinweis: Wenn die Tabelle in der Hauptabfrage groß ist, ist die Tabelle in der Unterabfrage klein, aber wenn viele Datensätze vorhanden sind, sollten Sie sie verwenden. Zum Beispiel: um die Klassen abzufragen, in denen es keine Schüler gibt , wählen Sie * aus der Klasse aus, in der „cid“ nicht enthalten ist (wählen Sie ein eindeutiges „cid“ aus stu)
Lösung: Wählen Sie * aus der Klasse aus
wobei cid nicht drin ist
(Wählen Sie die Ausführungsreihenfolge von unterschiedlichem cid aus stu aus, wobei cid nicht null ist)
nicht in ist: Eine Abfrage, die einen Datensatz in der Tabelle aufzeichnet (jeden Datensatz abfragen), erfüllt die Anforderungen. Wenn die Ergebnismenge nicht erfüllt ist, wird die Ergebnismenge zurückgegeben nicht übereinstimmt, wird der nächste Datensatz abgefragt, bis alle Datensätze in der Tabelle abgefragt sind. Mit anderen Worten: Um zu beweisen, dass es nicht gefunden werden kann, können wir es nur beweisen, indem wir alle Datensätze abfragen. Indizes werden nicht verwendet.
nicht vorhanden: Wenn die Hauptabfragetabelle nur wenige Datensätze und die Unterabfragetabelle viele Datensätze enthält und Indizes vorhanden sind.Zum Beispiel: Um diese Klassen ohne Schüler abzufragen, wählen Sie * aus Klasse2 aus
wo nicht vorhanden
(wählen Sie * von stu1, wobei stu1.cid =class2.cid)
not exists的执行顺序是:在表中查询,是根据索引查询的,如果存在就返回true,如果不存在就返回false,不会每条记录都去查询。
之所以要多用not exists,而不用not in,也就是not exists查询的效率远远高与not in查询的效率。
实例:
exists,not exists的使用方法示例,需要的朋友可以参考下。
学生表:create table student ( id number(8) primary key, name varchar2(10),deptment number(8) )
选课表:create table select_course ( ID NUMBER(8) primary key, STUDENT_ID NUMBER(8) foreign key (COURSE_ID) references course(ID), COURSE_ID NUMBER(8) foreign key (STUDENT_ID) references student(ID) )
课程表:create table COURSE ( ID NUMBER(8) not null, C_NAME VARCHAR2(20), C_NO VARCHAR2(10) )
student表的数据: ID NAME DEPTMENT_ID ---------- --------------- ----------- 1 echo 1000 2 spring 2000 3 smith 1000 4 liter 2000
course表的数据: ID C_NAME C_NO ---------- -------------------- -------- 1 数据库 data1 2 数学 month1 3 英语 english1
select_course表的数据: ID STUDENT_ID COURSE_ID ---------- ---------- ---------- 1 1 1 2 1 2 3 1 3 4 2 1 5 2 2 6 3 2
1.查询选修了所有课程的学生id、name:(即这一个学生没有一门课程他没有选的。)
分析:如果有一门课没有选,则此时(1)select * from select_course sc where sc.student_id=ts.id
and sc.course_id=c.id存在null,
这说明(2)select * from course c 的查询结果中确实有记录不存在(1查询中),查询结果返回没有选的课程,
此时select * from t_student ts 后的not exists 判断结果为false,不执行查询。
SQL> select * from t_student ts where not exists (select * from course c where not exists (select * from select_course sc where sc.student_id=ts.id and sc.course_id=c.id));
ID NAME DEPTMENT_ID ---------- --------------- ----------- 1 echo 1000
2.查询没有选择所有课程的学生,即没有全选的学生。(存在这样的一个学生,他至少有一门课没有选),
分析:只要有一个门没有选,即select * from select_course sc where student_id=t_student.id and course_id
=course.id 有一条为空,即not exists null 为true,此时select * from course有查询结果(id为子查询中的course.id ),
因此select id,name from t_student 将执行查询(id为子查询中t_student.id )。
SQL> select id,name from t_student where exists
(select * from course where not exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
2 spring
3 smith
4 liter
3.查询一门课也没有选的学生。(不存这样的一个学生,他至少选修一门课程),
分析:如果他选修了一门select * from course结果集不为空,not exists 判断结果为false;
select id,name from t_student 不执行查询。
SQL> select id,name from t_student where not exists
(select * from course where exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
4 liter
4.查询至少选修了一门课程的学生。
SQL> select id,name from t_student where exists
(select * from course where exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
1 echo
2 spring
3 smith本文介绍了SQL中EXISTS的用法 ,更多相关内容请关注php中文网。
相关推荐:
Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
Das obige ist der detaillierte Inhalt vonVerwendung von EXISTS in SQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!