
Heim >Datenbank >MySQL-Tutorial >SQL-Vergleich der Zeitdifferenz zwischen zwei benachbarten Datensätzen
SQL-Vergleich der Zeitdifferenz zwischen zwei benachbarten Datensätzen
- jackloveOriginal
- 2018-06-14 16:14:064811Durchsuche
Am Nachmittag habe ich gesehen, dass für das Projekt ein statistischer Bericht erstellt wurde. Die statistische Zeitdifferenz zwischen zwei benachbarten Datensätzen, die in der XX-Tabelle aufgezeichnet sind, beträgt
Die Daten in der Tabelle lauten wie folgt:
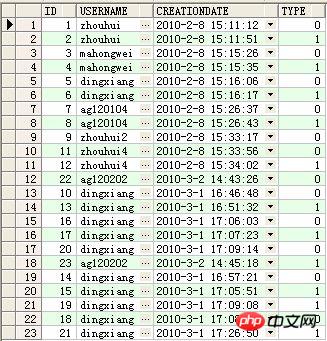
Es ist erforderlich, dass die Erstellungszeitdifferenz zwischen zwei benachbarten Datensätzen, wie dem 1. und 2. Datensatz, berechnet wird
d. h.
zhouhui 5 Sekunden
dingxiang 24 Sekunden
Die Nachfrage kam heraus und musste gelöst werden, und dann fand ich eine Lösung
Methode 1:
SQL-Code 
select t.username,(max( t.CREATIONDATE)-min( t.CREATIONDATE))*24*60*60,count(t.username)/2
from ofloginlog t
--where USERNAME = 'zhouhui '
Gruppe nach t.Benutzername
Statistiken zur Benutzer-Onlinezeit werden durch Gruppierung berechnet (d. h. die Differenz zwischen den beiden Datensätzen davor und danach)
Darstellung:

Erläuterung, dass das letzte Feld zum Zählen der Anzahl der Benutzeranmeldungen verwendet wird.
oracle Der Standardwert für die zweifache Subtraktion ist die Anzahl der Tage
oracle Der Standardwert für die zweifache Subtraktion ist Tage*24, was der Anzahl der Stundendifferenz entspricht
Oracle Die Anzahl der Tage für die Subtraktion zweier Zeitpunkte. Der Standardwert für die Subtraktion ist Tage*24*60, was der Anzahl der Minuten Differenz entspricht.
Der Standardwert für die Oracle-Subtraktion zwischen zwei Zeitpunkten ist Tage*24*60 *60, das ist die Anzahl der Sekunden Differenz
Methode 2:
SQL-Code
AuswählenBenutzername, Summe(b), Anzahl (Benutzername) / 2
* 24 * 60 * 60 as b
-
lag (type) over(partition by username order by
CREATIONDATE) lgtype, -
lag(CREATIONDATE) over(partition by username order by
CREATIONDATE) lgtime from ofloginlog t))
-
-- wobei USERNAME = 'zhouhui')
-
Gruppe nach Benutzername
Der Effekt ist derselbe und ich werde ihn hier nicht postenDas grundlegende SQL noch einmal überprüft haha20100520 Einige Änderungen in den Anforderungen erfordern, dass die Anzahl der Statistiken nicht dem entspricht Summe und Mittelwert von TYPE 1- und 0-Datensätzen, aber nur der Wert von TYPE=0, Die SQL-Gruppierung kann nicht so sein. Ich habe darüber nachgedacht und den SQL
SQL-Code
auswählen
g.Benutzername, g.Zeit
, h.Anzahl
von ( wählen t.Benutzername,
-
Boden((max(t.CREATIONDATE) - min(t.CREATIONDATE)) * 24 * 60 * 60) wie
Zeit von ofloginlog t, ofuser b
🎜>-
und t.username = b.username
gruppieren nach t.Benutzername) g,
(wählen t.Benutzername, Anzahl(t.Benutzername) als Anzahl
-
-
🎜> wobei g.username = H.Unername
-
Reihenfolge nach Anzahl
absteigend -
Abfrageergebnisse
Der Analysezeitunterschied ist der Unterschied zwischen den beiden Sätzen, und die Anzahl der Statistiken später ist nur die Anzahl Datensätze mit einer separaten Einschränkung von TYPE=0 sind inkonsistent, daher ist es schwierig, sie in einer Gruppe zu implementieren. Die Idee besteht darin, zuerst USERNAME und die Anzahl der Datensätze zu implementieren TYPE=0. Führen Sie die beiden Ergebnisse über die Inline-Beziehung von SELECT XX FROM A B 2 temporären Tabellen zusammen, um den zusammengeführten Ergebnissatz zu erhalten. In diesem Artikel wird der Zeitunterschied zwischen SQL und 2 erläutert. Bitte achten Sie auf die chinesische PHP-Website. Verwandte Empfehlungen: .net2.0-Verbindung Mysql5-Datenbankkonfiguration
Das obige ist der detaillierte Inhalt vonSQL-Vergleich der Zeitdifferenz zwischen zwei benachbarten Datensätzen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!