
Heim >Backend-Entwicklung >Python-Tutorial >Pandas-Methode zum Filtern von Daten basierend auf einer Kombination mehrerer Spalten
Pandas-Methode zum Filtern von Daten basierend auf einer Kombination mehrerer Spalten

- 不言Original
- 2018-06-04 16:33:056510Durchsuche
Dieser Artikel stellt hauptsächlich die Methode von Pandas vor, Daten anhand der Kombination mehrerer Spalten zu filtern. Jetzt kann ich ihn mit Ihnen teilen.
Lass uns mit Bildern reden
Eine Datei:

Zum Beispiel möchte ich die Daten herausfiltern, deren drei Spalten „Typ des Entwurfsbrunnens“, „Typ des in Auftrag gegebenen Brunnens“ und „Typ des aktuellen Brunnens“ alle 11 sind. Die Ergebnisse sind wie folgt:
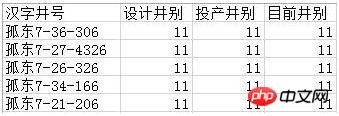
Natürlich können die Filterbedingungen hier frei an die Bedürfnisse des Benutzers angepasst werden. Der Code lautet wie folgt:
# -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.csv是那个大文件,有很多很多行 df1 = pd.read_csv(u'input.csv', encoding='gbk') #加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码 #这里的筛选条件可以根据用户需要进行修改 outfile = df1[(df1[u'设计井别']=='11') & (df1[u'投产井别']=='11') &(df1[u'目前井别']=='11')] outfile.to_csv('outfile.csv', index=False, encoding='gbk')
Manchmal haben wir auch die gegenteilige Anforderung und müssen das „Design“ löschen Bohrlochkategorie“, „Produktionsbohrlochkategorie“ und „aktuelle Bohrlochkategorie“ „Die Zeilen, in denen die drei Datenspalten alle 11 sind, haben folgende Auswirkung:

Der Code lautet wie folgt:
#input.csv是那个大文件,有很多很多行 df1 = pd.read_csv(u'input.csv', encoding='gbk') df2 = pd.read_csv(u'outfile.csv', encoding='gbk') #加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码 index = ~df1[u'汉字井号'].isin(df2[u'汉字井号']) df4 = df1[index] df4.to_csv('outfile1.csv', index=False, encoding='gbk')
Verwandte Empfehlungen:
Methode zur Auswahl von Zeilen und Spalten basierend auf Pandas-Daten Beispiele,
Grundlagen der Pandas-Datenverarbeitung filtern bestimmte Zeilen oder geben Spaltendaten an
Das obige ist der detaillierte Inhalt vonPandas-Methode zum Filtern von Daten basierend auf einer Kombination mehrerer Spalten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!