
Heim >Backend-Entwicklung >Python-Tutorial >Pytorch + Visdom behandelt einfache Klassifizierungsprobleme
Pytorch + Visdom behandelt einfache Klassifizierungsprobleme

- 不言Original
- 2018-06-04 16:07:163508Durchsuche
Dieser Artikel stellt hauptsächlich vor, wie Pytorch + Visdom mit einfachen Klassifizierungsproblemen umgeht. Er hat einen gewissen Referenzwert. Jetzt können Freunde in Not darauf verweisen.
Umgebung 🎜>
System: Win 10Grafikkarte: GTX965M
CPU: i7-6700HQ
Python 3.61
Pytorch 0.3
Paketreferenz
import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim
Datenaufbereitung
use_gpu = True ones = np.ones((500,2)) x1 = torch.normal(6*torch.from_numpy(ones),2) y1 = torch.zeros(500) x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2) y2 = y1 +1 x3 = torch.normal(-6*torch.from_numpy(ones),2) y3 = y1 +2 x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2) y4 = y1 +3 x = torch.cat((x1, x2, x3 ,x4), 0).float() y = torch.cat((y1, y2, y3, y4), ).long()Die Visualisierung ist wie folgt:
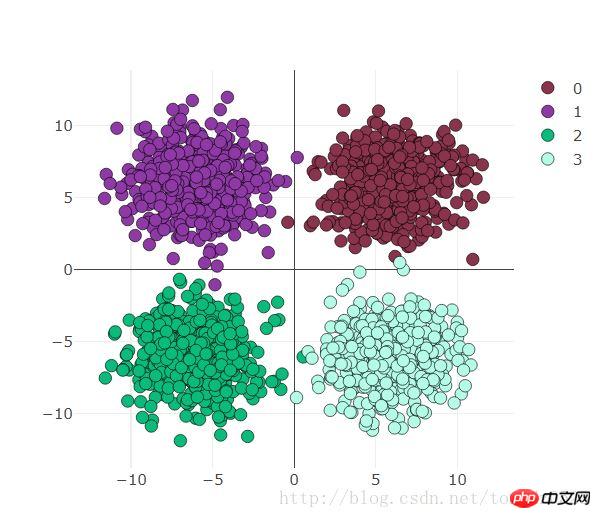
Visdom-Visualisierungsvorbereitung
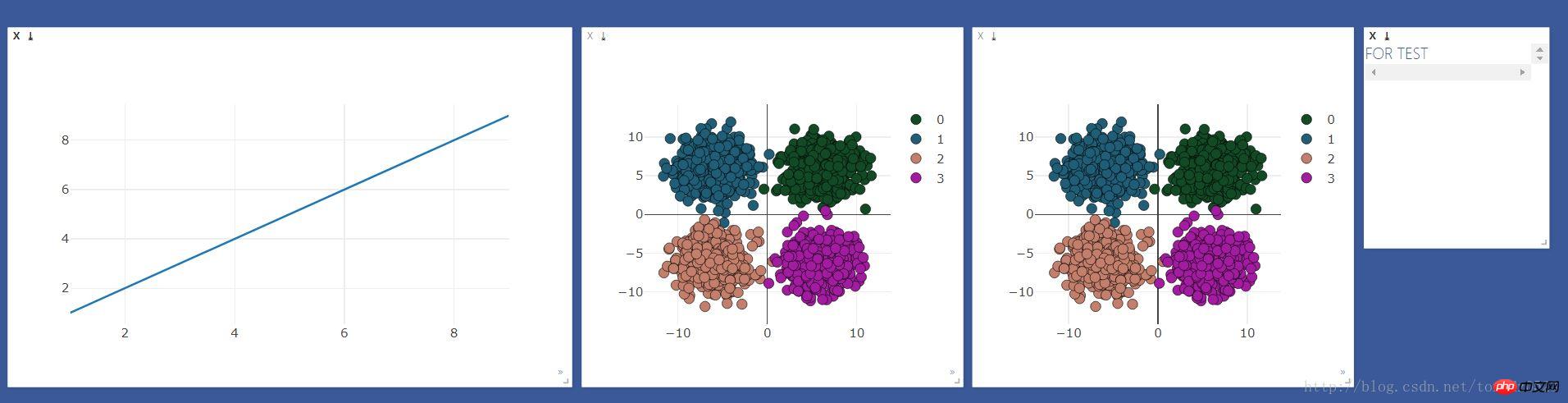
Erstellen Sie zunächst die Fenster, die beobachtet werden müssenviz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
)
Der Effekt ist wie folgt:
Logistische Regressionsverarbeitung
Eingabe 2, Ausgabe 4logstic = nn.Sequential( nn.Linear(2,4) )GPU- oder CPU-Auswahl:
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")
Optimierer- und Verlustfunktion:
loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)Training 2000 Mal:
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()
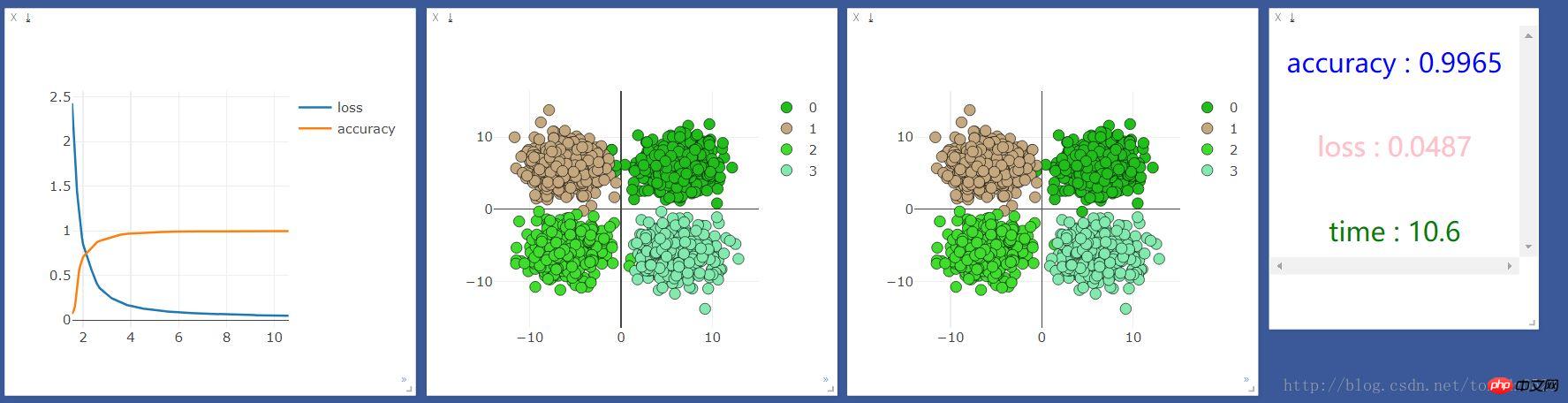
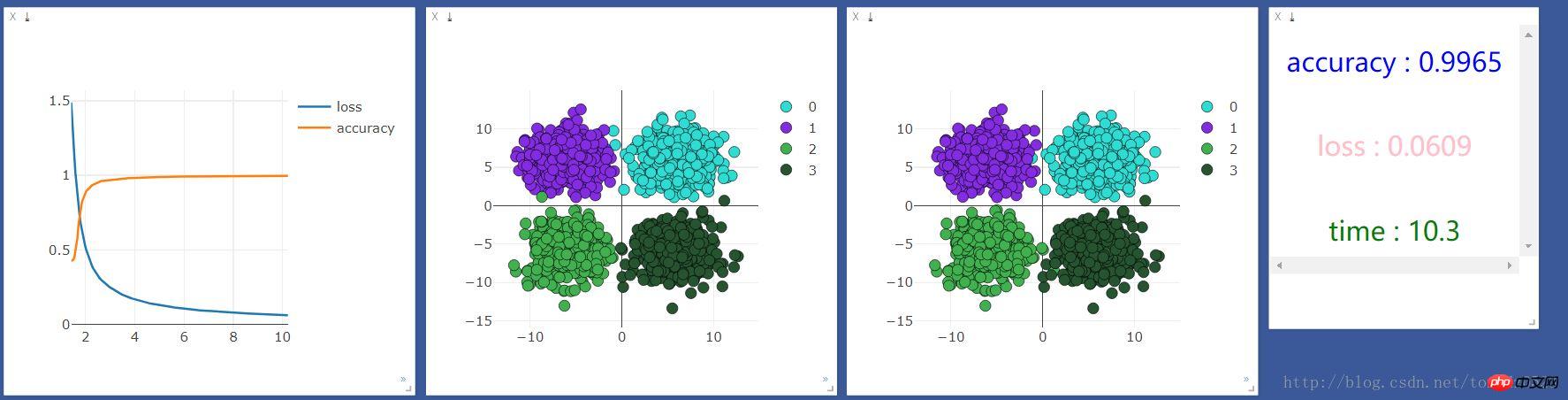
Nach Training, Beobachtung und Visualisierung:
if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
.format(accuracy,loss.data[0],time.time()-start_time),win =text)
Wir laufen Wenn Sie es zuerst einmal auf der CPU ausführen, sind die Ergebnisse wie folgt:
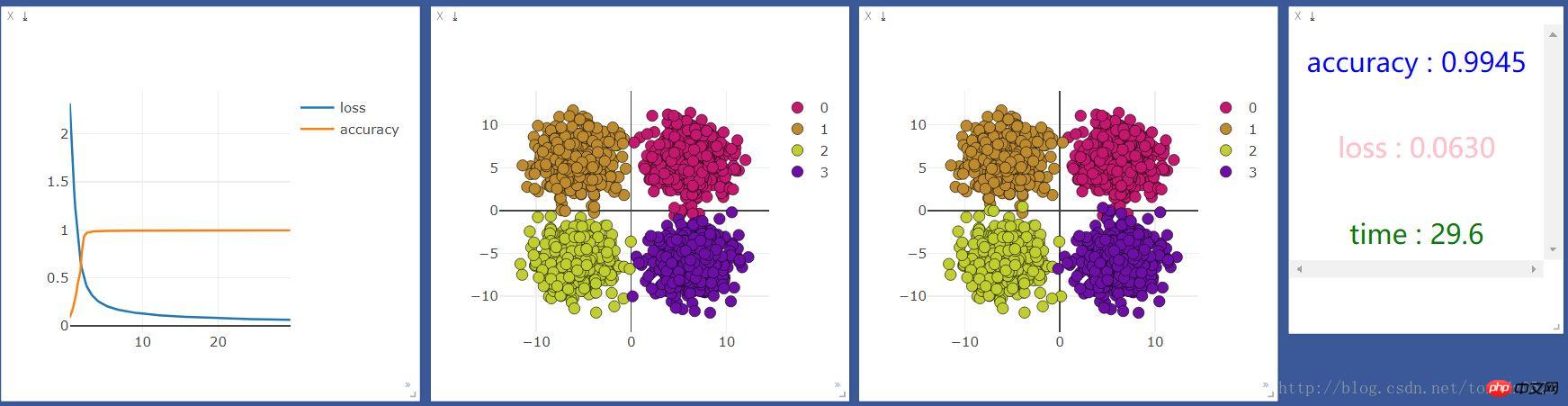

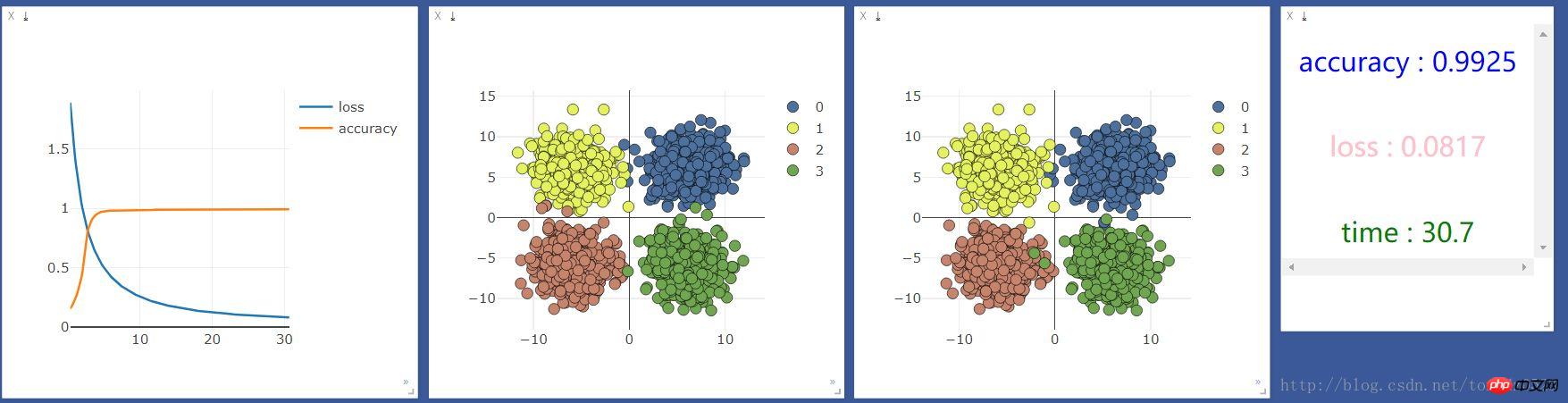
Fügen Sie eine neuronale Ebene hinzu:
net = nn.Sequential( nn.Linear(2, 10), nn.ReLU(), #激活函数 nn.Linear(10, 4) )Fügen Sie eine 10-Einheiten-neuronale Ebene hinzu und prüfen Sie, ob sich der Effekt ändert Verbesserung:
Ein Beispiel für den Aufbau eines einfachen neuronalen Netzwerks zur Implementierung von Regression und Klassifizierung auf PyTorch
Detaillierte Erläuterung des PyTorch Batch-Trainings und des Optimierungsvergleichs
Das obige ist der detaillierte Inhalt vonPytorch + Visdom behandelt einfache Klassifizierungsprobleme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!