
Heim >Backend-Entwicklung >Python-Tutorial >Tutorial zur Erkennung von Python-Verifizierungscodes: Graustufenverarbeitung, Binarisierung, Rauschunterdrückung und Tesserocr-Erkennung
Tutorial zur Erkennung von Python-Verifizierungscodes: Graustufenverarbeitung, Binarisierung, Rauschunterdrückung und Tesserocr-Erkennung

- 不言Original
- 2018-06-04 11:30:016572Durchsuche
Dieser Artikel stellt hauptsächlich das Tutorial zur Graustufenverarbeitung, Binärisierung, Rauschunterdrückung und Tesserocr-Erkennung zur Erkennung von Python-Verifizierungscodes vor. Jetzt kann ich es mit Ihnen teilen.
Vorwort
Ein unvermeidbares Problem beim Schreiben von Crawlern ist der Verifizierungscode. Es gibt mittlerweile etwa 4 Arten von Verifizierungscodes:
Bildklasse
Schiebeklasse
Klickklasse
Sprachtyp
Werfen wir heute einen Blick auf den Bildtyp? Die meisten dieser Verifizierungscodes sind eine Kombination aus Zahlen und Buchstaben, und in China werden auch chinesische Schriftzeichen verwendet. Auf dieser Basis werden Rauschen, Interferenzlinien, Verformung, Überlappung, unterschiedliche Schriftfarben und andere Methoden hinzugefügt, um die Erkennungsschwierigkeit zu erhöhen.
Entsprechend kann die Erkennung von Verifizierungscodes grob in die folgenden Schritte unterteilt werden:
Graustufenverarbeitung
Kontrast erhöhen (optional)
Binarisierung
Rauschunterdrückung
Neigungskorrektur-Segmentierungszeichen
Trainingsbibliothek einrichten
Anerkennung
Aufgrund ihres experimentellen Charakters werden die verwendeten Verifizierungscodes verwendet In diesem Artikel werden alle von Programmen generiert, anstatt echte Website-Bestätigungscodes stapelweise herunterzuladen. Dies hat den Vorteil, dass es eine große Anzahl von Datensätzen mit klaren Ergebnissen geben kann.
Wenn Sie Daten in einer realen Umgebung abrufen müssen, können Sie verschiedene Plattformen mit großem Code verwenden, um einen Datensatz für das Training zu erstellen.
Um den Verifizierungscode zu generieren, verwende ich die Claptcha-Bibliothek (lokaler Download). Natürlich ist auch die Captcha-Bibliothek (lokaler Download) eine gute Wahl.
Um den einfachsten rein digitalen, störungsfreien Verifizierungscode zu generieren, müssen Sie zunächst einige Änderungen an _drawLine in Zeile 285 von claptcha.py vornehmen. Ich lasse diese Funktion direkt None zurückgeben und dann Beginnen Sie mit der Generierung des Bestätigungscodes. Code:
from claptcha import Claptcha
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c.write('1.png')
Sie müssen hier auf den Schriftartenpfad von Ubuntu achten, Sie können auch andere Schriftarten online zur Verwendung herunterladen. Der Bestätigungscode wird wie folgt generiert:
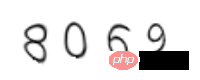
Es ist ersichtlich, dass der Bestätigungscode deformiert ist. Für diese Art des einfachsten Bestätigungscodes können Sie ihn direkt mit dem Open-Source-Code tesserocr von Google identifizieren.
Erste Installation:
apt-get install tesseract-ocr libtesseract-dev libleptonica-dev pip install tesserocr
Dann Erkennung starten:
from PIL import Image import tesserocr p1 = Image.open('1.png') tesserocr.image_to_text(p1) '8069\n\n'
Es ist ersichtlich, dass für diesen einfachen Verifizierungscode die Erkennungsrate bereits sehr hoch ist, ohne dass grundsätzlich etwas unternommen wird . Hoch. Interessierte Freunde können weitere Daten zum Testen verwenden, ich werde hier jedoch nicht auf Details eingehen.
Fügen Sie als Nächstes Rauschen zum Hintergrund des Bestätigungscodes hinzu, um Folgendes anzuzeigen:
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf",noise=0.4)
t,_ = c.write('2.png')
Generieren Sie den Bestätigungscode wie folgt:

Erkennung:
p2 = Image.open('2.png') tesserocr.image_to_text(p2) '8069\n\n'
Die Wirkung ist okay. Als nächstes generieren Sie eine alphanumerische Kombination:
c2 = Claptcha("A4oO0zZ2","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c2.write('3.png')
Generieren Sie den Bestätigungscode wie folgt:
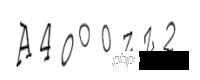
Der dritte ist der Kleinbuchstabe o, der vierte ist der Großbuchstabe O, der fünfte ist die Zahl 0, der sechste ist der Kleinbuchstabe z, der siebte ist der Großbuchstabe Z und der letzte ist die Nummer 2. Stimmt es, dass die menschlichen Augen bereits niedergekniet sind? Aber jetzt unterscheiden allgemeine Verifizierungscodes nicht strikt zwischen Groß- und Kleinbuchstaben. Mal sehen, wie die automatische Erkennung aussieht:
p3 = Image.open('3.png') tesserocr.image_to_text(p3) 'AMOOZW\n\n'
Natürlich ein Computer, der sogar knien kann mit dem menschlichen Auge ist nutzlos. In einigen Fällen, in denen die Interferenz gering und die Verformung nicht schwerwiegend ist, ist die Verwendung von tesserocr jedoch sehr einfach und bequem. Stellen Sie dann Zeile 285 der geänderten _drawLine von claptcha.py wieder her, um zu sehen, ob Interferenzlinien hinzugefügt werden.

p4 = Image.open('4.png') tesserocr.image_to_text(p4) ''
Es kann überhaupt nicht erkannt werden, nachdem eine Interferenzlinie hinzugefügt wurde. Gibt es also eine Möglichkeit, die Interferenzlinie zu entfernen? ?
Obwohl das Bild schwarzweiß aussieht, muss es dennoch in Graustufen verarbeitet werden. Andernfalls erhalten Sie mit der Funktion „load()“ ein RGB-Tupel eines bestimmten Pixels anstelle eines einzelnen Werts . Die Verarbeitung ist wie folgt:
def binarizing(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img
Das verarbeitete Bild ist wie folgt:

Sie können die Verarbeitung sehen. Anschließend wurde das Bild stark geschärft. Als nächstes habe ich versucht, die Interferenzlinien mithilfe der gängigen 4-Nachbarschafts- und 8-Nachbarschafts-Algorithmen zu entfernen. Der sogenannte X-Nachbarschaftsalgorithmus kann sich auf die Neun-Quadrat-Raster-Eingabemethode auf Mobiltelefonen beziehen. Die Taste 5 dient zur Beurteilung des Pixels nach oben, unten, links und rechts, und die Nachbarschaft 8 dient zur Beurteilung umlaufende 8 Pixel. Wenn die Anzahl von 255 unter diesen 4 oder 8 Punkten einen bestimmten Schwellenwert überschreitet, wird dieser Punkt als Rauschen beurteilt. Der Schwellenwert kann entsprechend der tatsächlichen Situation geändert werden.
def depoint(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w,h = img.size
for y in range(1,h-1):
for x in range(1,w-1):
count = 0
if pixdata[x,y-1] > 245:#上
count = count + 1
if pixdata[x,y+1] > 245:#下
count = count + 1
if pixdata[x-1,y] > 245:#左
count = count + 1
if pixdata[x+1,y] > 245:#右
count = count + 1
if pixdata[x-1,y-1] > 245:#左上
count = count + 1
if pixdata[x-1,y+1] > 245:#左下
count = count + 1
if pixdata[x+1,y-1] > 245:#右上
count = count + 1
if pixdata[x+1,y+1] > 245:#右下
count = count + 1
if count > 4:
pixdata[x,y] = 255
return img
Das verarbeitete Bild sieht wie folgt aus:

好像……根本没卵用啊?!确实是这样的,因为示例中的图片干扰线的宽度和数字是一样的。对于干扰线和数据像素不同的,比如Captcha生成的验证码:

从左到右依次是原图、二值化、去除干扰线的情况,总体降噪的效果还是比较明显的。另外降噪可以多次执行,比如我对上面的降噪后结果再进行依次降噪,可以得到下面的效果:

再进行识别得到了结果:
p7 = Image.open('7.png') tesserocr.image_to_text(p7) '8069 ,,\n\n'
另外,从图片来看,实际数据颜色明显和噪点干扰线不同,根据这一点可以直接把噪点全部去除,这里就不展开说了。
第一篇文章,先记录如何将图片进行灰度处理、二值化、降噪,并结合tesserocr来识别简单的验证码,剩下的部分在下一篇文章中和大家一起分享。
相关推荐:
Das obige ist der detaillierte Inhalt vonTutorial zur Erkennung von Python-Verifizierungscodes: Graustufenverarbeitung, Binarisierung, Rauschunterdrückung und Tesserocr-Erkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!