
Heim >Web-Frontend >js-Tutorial >So verwenden Sie Superagent und Cheerio mit dem NodeJS-Crawler
So verwenden Sie Superagent und Cheerio mit dem NodeJS-Crawler
- 亚连Original
- 2018-06-01 14:38:382585Durchsuche
Dieser Artikel stellt hauptsächlich das Wissen über Superagent und Cheerio für die erste Testversion des NodeJS-Crawlers vor. Er ist sehr gut und hat Referenzwert.
Vorwort
Ich habe in den letzten Tagen angefangen, NodeJS zu lernen und habe einen Crawler geschrieben: https://github.com/leichangchun/node-crawlers/tree /master/superagent_cheerio_demo zum Crawlen der Homepage des Blogparks. Hier finden Sie eine kurze Zusammenfassung des Artikeltitels, des Benutzernamens, der Anzahl der Lesevorgänge, der Anzahl der Empfehlungen und des Benutzeravatars.
Verwenden Sie diese Punkte:
1. Das Kernmodul des Knotens – Dateisystem
2. Das Drittanbietermodul, das für http-Anfragen verwendet wird – Superagent
3. Ein Drittanbietermodul zum Parsen von DOM – cheerio
Detaillierte Erklärungen und APIs verschiedener Module finden Sie unter den einzelnen Links. In der Demo gibt es nur einfache Verwendungen.
Vorbereitungsarbeiten
Verwenden Sie npm, um Abhängigkeiten zu verwalten. Die Abhängigkeitsinformationen werden in package.json
//安装用到的第三方模块 cnpm install --save superagent cheerio
gespeichert Stellen Sie vor, was benötigt wird. Verwendetes Funktionsmodul
//引入第三方模块,superagent用于http请求,cheerio用于解析DOM const request = require('superagent'); const cheerio = require('cheerio'); const fs = require('fs');
Seite anfordern + analysieren
Wenn Sie zum Inhalt auf der Homepage des Blogs crawlen möchten Park, Sie müssen zuerst die Homepage-Adresse anfordern. Hier verwenden wir Superagent, um http-Anfragen zu stellen:
request.get(url)
.end(error,res){
//do something
}Initiieren Sie eine Get-Anfrage an die angegebene URL Wenn die Anfrage falsch ist, wird ein Fehler zurückgegeben (wenn kein Fehler vorliegt, ist der Fehler null) oder undefiniert), res sind die zurückgegebenen Daten.
Nachdem wir den HTML-Inhalt erhalten haben, müssen wir Cheerio zum Parsen des DOM verwenden. Cheerio muss zuerst den Ziel-HTML laden und ihn dann analysieren. Die API ist der JQuery sehr ähnlich API. Ich bin mit jquery vertraut und kann sehr schnell loslegen. Schauen Sie sich direkt das Codebeispiel an
//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
})Speicherdaten
Nach dem Parsen des obigen DOM wurden die erforderlichen Informationsinhalte gespleißt und die Das Bild wurde über die URL abgerufen. Speichern Sie es jetzt, speichern Sie den Inhalt in einer TXT-Datei im angegebenen Verzeichnis und laden Sie das Bild in das angegebene Verzeichnis herunter.
Erstellen Sie zuerst das Verzeichnis und verwenden Sie das NodeJS-Kerndateisystem
//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}Sobald Sie das Verzeichnis angegeben haben, können Sie den Inhalt der TXT-Datei bereits dort schreiben. Verwenden Sie einfach writeFile()
//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}, um den Link des Bildes zu erhalten Sie müssen Superagent verwenden, um das Bild herunterzuladen und lokal zu speichern. Superagent kann direkt einen Antwortstrom zurückgeben und dann mit der NodeJS-Pipeline zusammenarbeiten, um den Bildinhalt direkt an den lokalen Ort zu schreiben
//下载爬到的图片
function downloadImg() {
imgs.forEach((imgUrl,index) => {
//获取图片名
let imgName = imgUrl.split('/').pop();
//下载图片存放到指定目录
let stream = fs.createWriteStream(`./imgs/${imgName}`);
let req = request.get('https:' + imgUrl); //响应流
req.pipe(stream);
console.log(`开始下载图片 https:${imgUrl} --> ./imgs/${imgName}`);
} )
}Wirkung
Führen Sie die Demo aus und sehen Sie, welche Wirkung die Daten haben normal heruntergeklettert
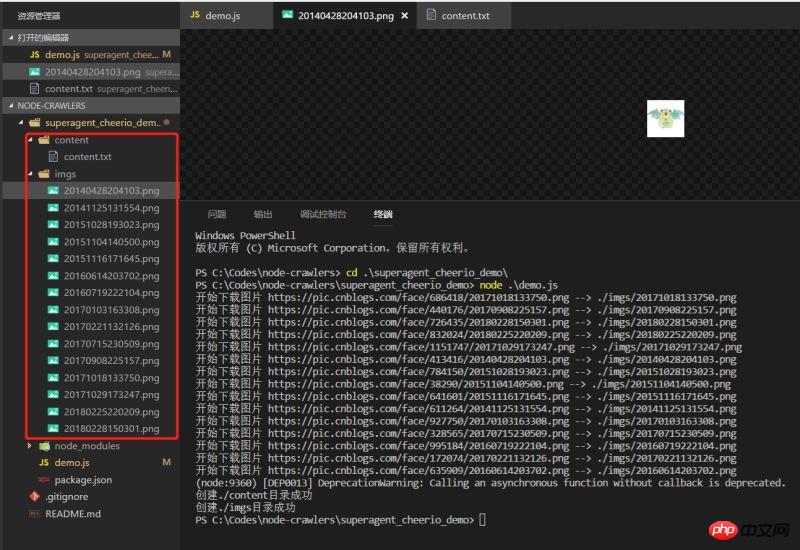
Eine sehr einfache Demo, die vielleicht nicht so streng ist, aber immer der erste kleine Schritt in Richtung Knoten.
Ich habe das Obige für Sie zusammengestellt und hoffe, dass es Ihnen in Zukunft hilfreich sein wird.
Verwandte Artikel:
Beispiele für dynamische Routing-Umleitung und Navigationsschutz von Vue
Lösen Sie das Fehlerproblem nach Verwendung des vue.js-Routings
Das obige ist der detaillierte Inhalt vonSo verwenden Sie Superagent und Cheerio mit dem NodeJS-Crawler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse