
Heim >Backend-Entwicklung >Python-Tutorial >Einige Tipps zur Implementierung der Datentypkonvertierung in Pandas
Einige Tipps zur Implementierung der Datentypkonvertierung in Pandas

- 不言Original
- 2018-05-07 11:44:007764Durchsuche
Dieser Artikel stellt hauptsächlich einige Techniken zur Datentypkonvertierung in Pandas vor. Er hat einen gewissen Referenzwert. Jetzt können Freunde in Not darauf verweisen.
Vorwort
Pandas ist ein wichtiges Datenanalysetool in Python. Bei der Verwendung von Pandas für die Datenanalyse ist es sehr wichtig, sicherzustellen, dass der richtige Datentyp verwendet wird, da sonst einige unvorhersehbare Fehler auftreten können.
Datentypen in Pandas: Datentypen sind im Wesentlichen die internen Strukturen, die Programmiersprachen verwenden, um zu verstehen, wie Daten gespeichert und bearbeitet werden. Ein Programm muss beispielsweise verstehen, dass man zwei Zahlen addieren kann, beispielsweise 5 + 10, um 15 zu erhalten. Wenn es sich um zwei Zeichenfolgen wie „cat“ und „hat“ handelt, können Sie diese auch verketten (hinzufügen), um „cathat“ zu erhalten. Shangxuetang·Baizhan-Programmierer Herr Chen wies darauf hin, dass ein potenziell verwirrender Aspekt der Pandas-Datentypen darin bestehe, dass es gewisse Überschneidungen zwischen den Datentypen von Pandas, Python und Numpy gebe.
Meistens müssen Sie sich keine Gedanken darüber machen, ob Sie einen Pandas-Typ explizit in den entsprechenden NumPy-Typ umwandeln sollten. Im Allgemeinen können Sie die Standardeinstellungen int64 und float64 von Pandas verwenden. Der einzige Grund, warum ich diese Tabelle einfüge, besteht darin, dass Sie manchmal Numpy-Typen zwischen Codezeilen oder während Ihrer eigenen Analyse sehen.
Datentypen gehören zu den Dingen, die Sie nicht interessieren, bis Sie auf einen Fehler oder ein unerwartetes Ergebnis stoßen. Aber es ist auch das Erste, was Sie überprüfen sollten, wenn Sie neue Daten zur weiteren Analyse in Pandas laden.
Der Autor verwendet Pandas schon seit einiger Zeit, aber ich mache bei einigen kleineren Problemen immer noch Fehler. Als ich auf die Quelle zurückblickte, stellte ich fest, dass einige Feature-Spalten nicht von der Art sind, mit denen Pandas umgehen kann Daten. Daher werden in diesem Artikel einige Tipps zum Konvertieren der grundlegenden Datentypen von Python in Datentypen erläutert, die von Pandas verarbeitet werden können.
Datentypen, die jeweils von Pandas, Numpy und Python unterstützt werden
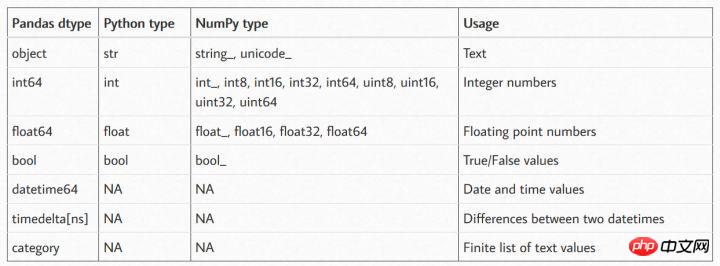
Aus der obigen Tabelle Es ist ersichtlich, dass Pandas die am häufigsten vorkommenden Datentypen unterstützt. In einigen Fällen können Numpy-Datentypen in Pandas-Datentypen konvertiert werden.
Einführen tatsächlicher Daten zur Analyse
Der Datentyp ist etwas, das Sie möglicherweise nicht groß interessiert, bis Sie das falsche Ergebnis erhalten, also in Ein Beispiel von Hier wird die tatsächliche Datenanalyse vorgestellt, um das Verständnis zu vertiefen.
import numpy as np import pandas as pd data = pd.read_csv('data.csv', encoding='gbk') #因为数据中含有中文数据 data
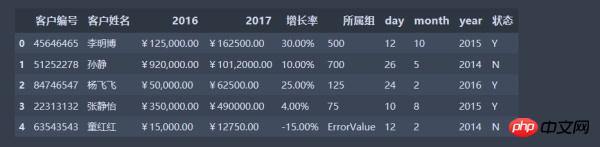
Die Daten werden jetzt geladen, wenn Sie jetzt einige Operationen an den Daten durchführen möchten, z Fügen Sie die entsprechenden Elemente in den Spalten 2016 und 2017 hinzu.
Daten['2016'] + Daten['2017'] #Selbstverständlich
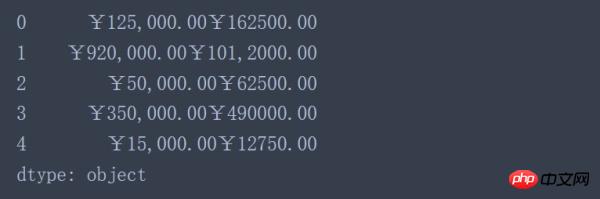
Den Ergebnissen nach zu urteilen, gibt es wie erwartet keine entsprechende Addition numerischer Werte. Dies liegt daran, dass die Hinzufügung von Objekttypen in Pandas der Hinzufügung von Zeichenfolgen in Python entspricht.
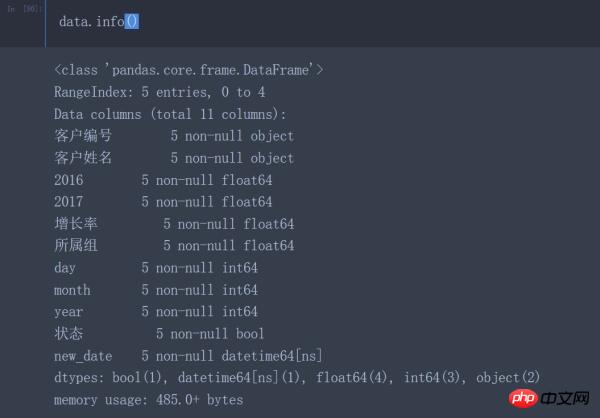
data.info() #Bevor Sie die Daten verarbeiten, sollten Sie die relevanten Informationen der geladenen Daten überprüfen
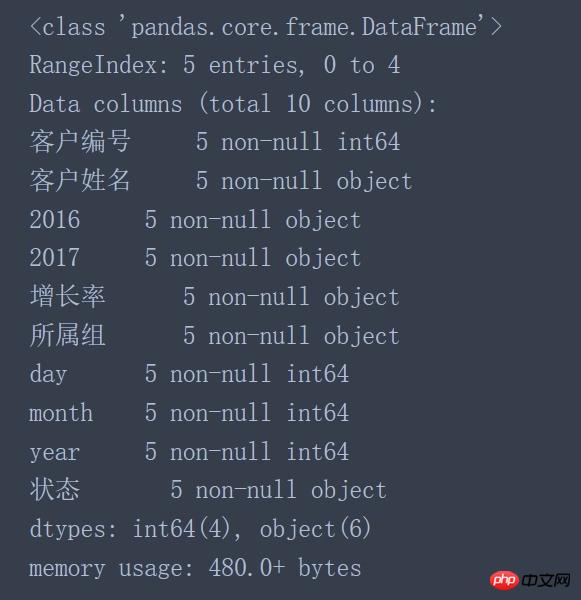
Nachdem Sie die relevanten Informationen zum Laden von Daten gelesen haben, können Sie die folgenden Probleme feststellen:
Der Datentyp der Kundennummer ist int64 statt Objekttyp
Der Datentyp der Spalten 2016 und 2017 ist ein Objekt statt eines numerischen Typs (int64, float64)
Der Datentyp der Wachstumsrate und der Gruppe sollte sein numerischer Typ statt Objekttyp
Die Datentypen von Jahr, Monat und Tag sollten vom Typ datetime64 statt vom Objekttyp sein
Es gibt drei Grundlegende Methoden für die Datentypkonvertierung in Pandas:
Verwenden Sie die Funktion astype() für die erzwungene Typkonvertierung
Benutzerdefinierte Funktion für die Datentypkonvertierung
-
Verwenden Sie die von Pandas bereitgestellten Funktionen wie to_numeric(), to_datetime()
Verwenden Sie die Funktion astype() für die Typkonvertierung
Der einfachste Weg, den Datentyp der Datenspalte zu konvertieren, ist die Verwendung der astype()-Funktion
data['客户编号'].astype('object') data['客户编号'] = data['客户编号'].astype('object') #对原始数据进行转换并覆盖原始数据列
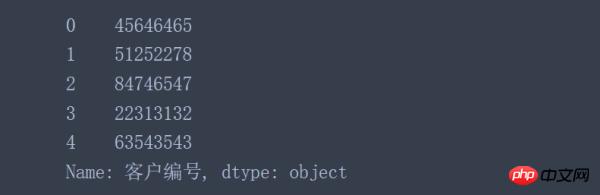
Sehen Sie sich die obigen Ergebnisse an. Es klingt gut. Hier sind ein paar Beispiele, bei denen die Funktion astype() mit Spaltendaten funktioniert, aber fehlschlägt
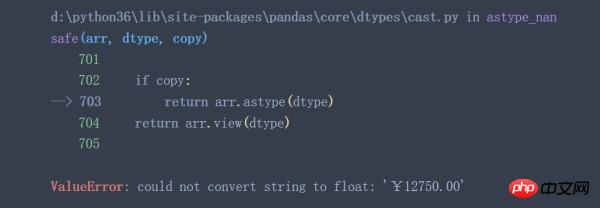
data['2017'].astype('float')
data['所属组'].astype('int')
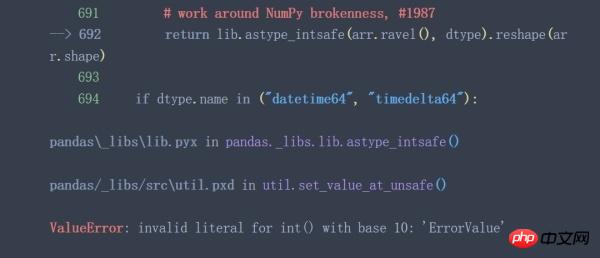
从上面两个例子可以看出,当待转换列中含有不能转换的特殊值时(例子中¥,ErrorValue等)astype()函数将失效。有些时候astype()函数执行成功了也并不一定代表着执行结果符合预期(神坑!)
data['状态'].astype('bool')
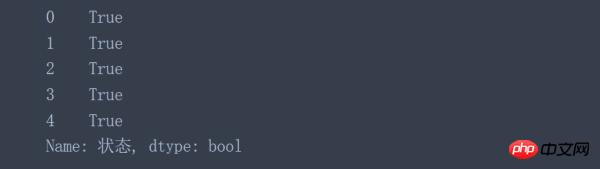
乍一看,结果看起来不错,但仔细观察后,会发现一个大问题。那就是所有的值都被替换为True了,但是该列中包含好几个N标志,所以astype()函数在该列也是失效的。
总结一下astype()函数有效的情形:
数据列中的每一个单位都能简单的解释为数字(2, 2.12等)
数据列中的每一个单位都是数值类型且向字符串object类型转换
如果数据中含有缺失值、特殊字符astype()函数可能失效。
使用自定义函数进行数据类型转换
该方法特别适用于待转换数据列的数据较为复杂的情形,可以通过构建一个函数应用于数据列的每一个数据,并将其转换为适合的数据类型。
对于上述数据中的货币,需要将它转换为float类型,因此可以写一个转换函数:
def convert_currency(value): """ 转换字符串数字为float类型 - 移除 ¥ , - 转化为float类型 """ new_value = value.replace(',', '').replace('¥', '') return np.float(new_value)
现在可以使用Pandas的apply函数通过covert_currency函数应用于2016列中的所有数据中。
data['2016'].apply(convert_currency)
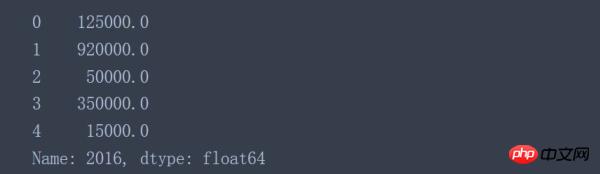
该列所有的数据都转换成对应的数值类型了,因此可以对该列数据进行常见的数学操作了。如果利用lambda表达式改写一下代码,可能会比较简洁但是对新手不太友好。
data['2016'].apply(lambda x: x.replace('¥', '').replace(',', '')).astype('float')
当函数需要重复应用于多个列时,个人推荐使用第一种方法,先定义函数还有一个好处就是可以搭配read_csv()函数使用(后面介绍)。
#2016、2017列完整的转换代码 data['2016'] = data['2016'].apply(convert_currency) data['2017'] = data['2017'].apply(convert_currency)
同样的方法运用于增长率,首先构建自定义函数
def convert_percent(value): """ 转换字符串百分数为float类型小数 - 移除 % - 除以100转换为小数 """ new_value = value.replace('%', '') return float(new_value) / 100
使用Pandas的apply函数通过covert_percent函数应用于增长率列中的所有数据中。
data['增长率'].apply(convert_percent)
使用lambda表达式:
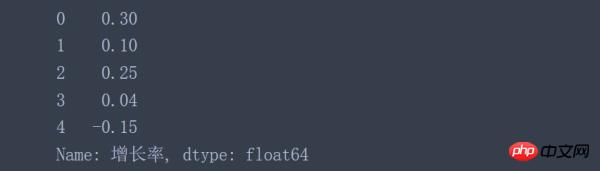
data['增长率'].apply(lambda x: x.replace('%', '')).astype('float') / 100
结果都相同:
为了转换状态列,可以使用Numpy中的where函数,把值为Y的映射成True,其他值全部映射成False。
data['状态'] = np.where(data['状态'] == 'Y', True, False)
同样的你也可以使用自定义函数或者使用lambda表达式,这些方法都可以完美的解决这个问题,这里只是多提供一种思路。
利用Pandas的一些辅助函数进行类型转换
Pandas的astype()函数和复杂的自定函数之间有一个中间段,那就是Pandas的一些辅助函数。这些辅助函数对于某些特定数据类型的转换非常有用(如to_numeric()、to_datetime())。所属组数据列中包含一个非数值,用astype()转换出现了错误,然而用to_numeric()函数处理就优雅很多。
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)

可以看到,非数值被替换成0.0了,当然这个填充值是可以选择的,具体文档见
pandas.to_numeric - pandas 0.22.0 documentation
Pandas中的to_datetime()函数可以把单独的year、month、day三列合并成一个单独的时间戳。
pd.to_datetime(data[['day', 'month', 'year']])
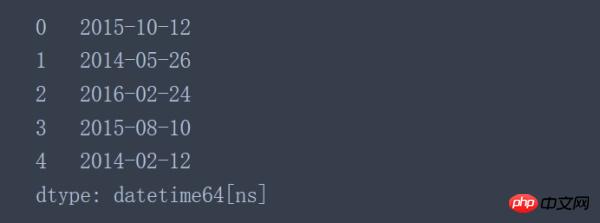
完成数据列的替换
data['new_date'] = pd.to_datetime(data[['day', 'month', 'year']]) #新产生的一列数据 data['所属组'] = pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
到这里所有的数据列都转换完毕,最终的数据显示:
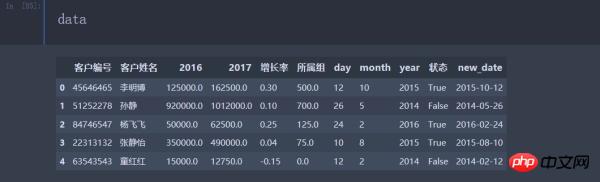
在读取数据时就对数据类型进行转换,一步到位
data2 = pd.read_csv("data.csv",
converters={
'客户编号': str,
'2016': convert_currency,
'2017': convert_currency,
'增长率': convert_percent,
'所属组': lambda x: pd.to_numeric(x, errors='coerce'),
'状态': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')
在这里也体现了使用自定义函数比lambda表达式要方便很多。(大部分情况下lambda还是很简洁的,笔者自己也很喜欢使用)
Zusammenfassung
Der erste Schritt beim Betrieb eines Datensatzes besteht darin, sicherzustellen, dass der richtige Datentyp festgelegt ist, und dann können die Daten eingegeben werden analysiert und visualisiert Für andere Vorgänge bietet Pandas viele sehr praktische Funktionen. Mit diesen Funktionen ist es sehr praktisch, die Daten zu analysieren.
Verwandte Empfehlungen:
Pandas implementiert die Auswahl von Zeilen spezifischer Indizes
Das obige ist der detaillierte Inhalt vonEinige Tipps zur Implementierung der Datentypkonvertierung in Pandas. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!