
Heim >Backend-Entwicklung >Python-Tutorial >Grundlagen der Pandas-Datenverarbeitung: Filtern Sie Daten in bestimmten Zeilen oder bestimmten Spalten
Grundlagen der Pandas-Datenverarbeitung: Filtern Sie Daten in bestimmten Zeilen oder bestimmten Spalten

- 不言Original
- 2018-05-03 13:31:4222197Durchsuche
In diesem Artikel werden hauptsächlich die Grundlagen der Pandas-Datenverarbeitung und relevante Informationen zum Filtern von Daten in bestimmten Zeilen oder Spalten vorgestellt
Die beiden Hauptdatenstrukturen von Pandas sind: Serien ( entspricht einer Datenstruktur in einer Zeile oder Spalte) und DataFrame (entspricht einer tabellarischen Datenstruktur mit mehreren Zeilen und Spalten).
Zum leichteren Verständnis wird in diesem Artikel eine Analogie zur Excel- oder SQL-Operation von Zeilen oder Spalten erstellt
1. Neuindizierung: Neuindizierung und ix
Wie im vorherigen Artikel vorgestellt, ist der Standardzeilenindex nach dem Lesen der Daten 0, 1, 2, 3 ... solche Sequenznummern. Der Spaltenindex entspricht dem Feldnamen (d. h. der ersten Datenzeile). Eine Neuindizierung bedeutet hier, dass Sie den Standardindex nach Ihren Wünschen ändern können.
1.1 Serie
Zum Beispiel: data=Series([4,5,6],index=['a','b','c']), der Zeilenindex ist a,b,c.
Wir verwenden data.reindex(['a','c','d','e']), um den Index zu ändern und die Ausgabe ist:
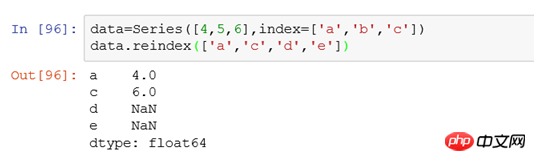
Es versteht sich, dass wir, nachdem wir den Index mithilfe von Reindex festgelegt haben, den entsprechenden Wert in den Originaldaten entsprechend dem Index abgleichen und der nicht übereinstimmende Wert NaN ist.
1.2 DataFrame
(1) Zeilenindexänderung: Der DataFrame-Zeilenindex ist derselbe wie bei Series
(2) Spaltenindexänderung: Der Spaltenindex verwendet reindex(columns=[ 'm1','m2','m3']), verwenden Sie die Parameterspalten, um die Änderung des Spaltenindex anzugeben. Das Ändern der Logik ähnlich dem Zeilenindex entspricht der Verwendung eines neuen Spaltenindex, um ihn an die Originaldaten anzupassen. Wenn keine Übereinstimmung vorliegt, legen Sie NaN
fest >
(3) Um Zeilen- und Spaltenindizes gleichzeitig zu ändern, können Sie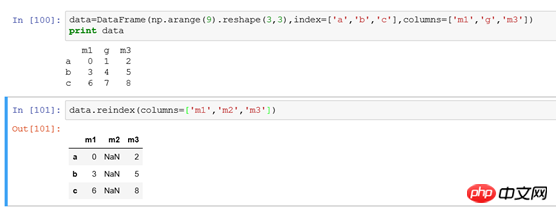
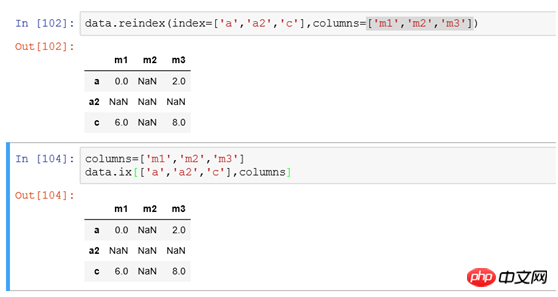 verwenden. 2. Verwerfen Sie die Spalten auf der angegebenen Achse (für Laien: Zeilen oder Spalten löschen) :drop
verwenden. 2. Verwerfen Sie die Spalten auf der angegebenen Achse (für Laien: Zeilen oder Spalten löschen) :drop
Wählen Sie anhand des Index aus, welche Zeile oder Spalte gelöscht werden soll
data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'3. Auswahl und Filterung (für Laien bedeutet das Filtern von Abfragen nach Bedingungen in SQL)
Weil es eine gibt Zeilen- und Spaltenindex in Python, es ist bequemer, Daten zu filtern3.1 Series
(1) Wählen Sie nach Zeilenindex aus, z. B.
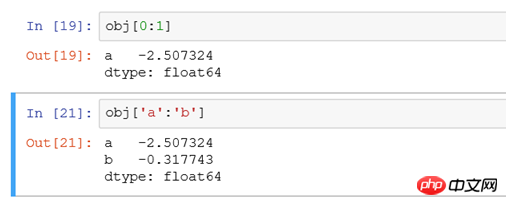
obj['b'] ist äquivalent zu ist äquivalent zu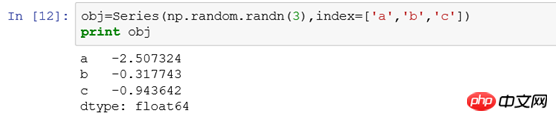 , und die Ergebnisse werden in der Reihenfolge b, a, c angezeigt. Dies ist der Unterschied zwischen obj[. 0:1] und obj['a':'b'] ist wie folgt:
, und die Ergebnisse werden in der Reihenfolge b, a, c angezeigt. Dies ist der Unterschied zwischen obj[. 0:1] und obj['a':'b'] ist wie folgt:
#Ersteres beinhaltet nicht das Ende, und letzteres beinhaltet das Ende select * from tb where xid='b'obj['b','a','c']select * from tb where xid in ('a','b','c')
 (1) Wählen Sie eine einzelne Zeile mit ix oder xs aus:
(1) Wählen Sie eine einzelne Zeile mit ix oder xs aus:
Wenn Sie den Zeilendatensatz mit Index b filtern, verwenden Sie die folgenden drei Methoden
(2) Wählen Sie mehrere Zeilen aus: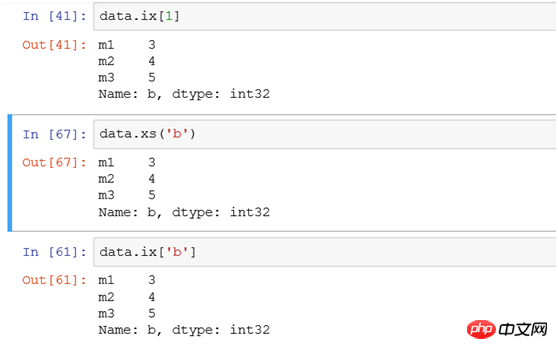 Filtern Sie den Index als a, b Die zweizeilige Aufzeichnungsmethode
Filtern Sie den Index als a, b Die zweizeilige Aufzeichnungsmethode
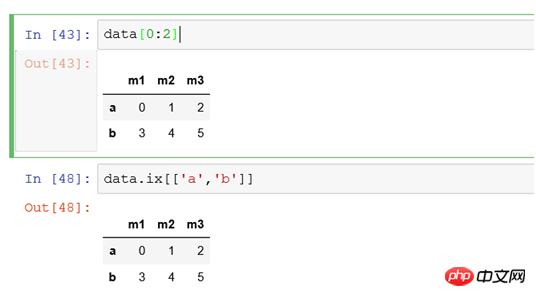 data[0:2 ] repräsentiert die Datensätze von der ersten bis zur zweiten Zeile. Die erste Zeile beginnt standardmäßig bei 0 zu zählen, mit Ausnahme der 2 am Ende.
data[0:2 ] repräsentiert die Datensätze von der ersten bis zur zweiten Zeile. Die erste Zeile beginnt standardmäßig bei 0 zu zählen, mit Ausnahme der 2 am Ende.
(3) Wählen Sie eine einzelne Spalte
Alle Zeilendatensatzdaten in Spalte m1 filtern
(4) Wählen Sie mehrere Spalten aus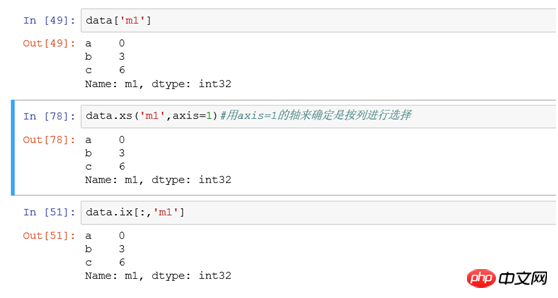 Filtern Sie die beiden Spalten von m1 und m3 und zeichnen Sie die Daten in allen Zeilen auf
Filtern Sie die beiden Spalten von m1 und m3 und zeichnen Sie die Daten in allen Zeilen auf
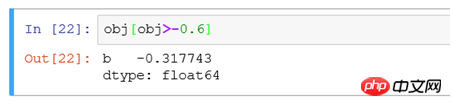
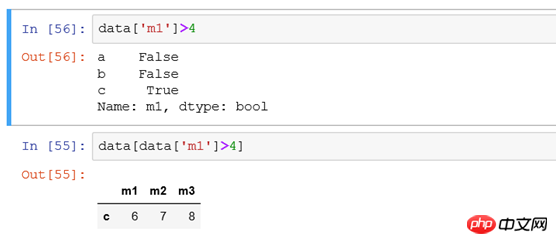
 (5) Filtern Sie Zeilen oder Spalten entsprechend der Größenbedingung des Werts.
(5) Filtern Sie Zeilen oder Spalten entsprechend der Größenbedingung des Werts.
Das Herausfiltern aller Datensätze mit einem Spaltenwert größer als 4 entspricht beispielsweise der Auswahl von * aus der TB-Spalte Name>4
(6) Wenn Sie alle Datensätze mit einem Spaltenwert größer als 4 filtern und nur einige Spalten anzeigen
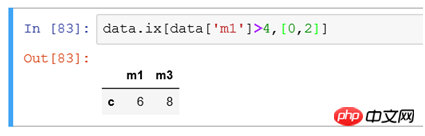
Verwenden Sie Bedingungen, um Filtern Sie Zeilen und verwenden Sie [0,2], um Daten in der ersten und dritten Spalte zu filtern
Verwandte Empfehlungen:
Wählen Sie Zeilen und Spalten basierend auf Pandas-Datenbeispielmethoden aus
Python3-Pandas zum Lesen von MySQL-Daten und Einfügen von
Das obige ist der detaillierte Inhalt vonGrundlagen der Pandas-Datenverarbeitung: Filtern Sie Daten in bestimmten Zeilen oder bestimmten Spalten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!