
Heim >Backend-Entwicklung >PHP-Tutorial >Detaillierte Erläuterung der drei Möglichkeiten zum Laden von Daten in Tensorflow
Detaillierte Erläuterung der drei Möglichkeiten zum Laden von Daten in Tensorflow

- 不言Original
- 2018-04-24 14:24:093545Durchsuche
In diesem Artikel werden hauptsächlich die drei Möglichkeiten zum Laden von Daten in Tensorflow ausführlich vorgestellt. Jetzt teile ich sie mit Ihnen und gebe sie als Referenz. Werfen wir gemeinsam einen Blick darauf
Es gibt drei Möglichkeiten, Tensorflow-Daten zu lesen:
Vorgeladene Daten: Vorgeladene Daten
Fütterung : Python generiert Daten und leitet die Daten dann an das Backend weiter.
Lesen aus Datei: Direkt aus der Datei lesen
Was sind die Unterschiede zwischen diesen drei Lesemethoden? Wir müssen zunächst wissen, wie TensorFlow (TF) funktioniert.
Der Kern von TF ist in C++ geschrieben. Der Vorteil besteht darin, dass es schnell läuft, der Nachteil ist jedoch, dass der Aufruf unflexibel ist. Python ist genau das Gegenteil, es vereint also die Vorteile beider Sprachen. Die Kernoperatoren und das Ausführungsframework für Berechnungen sind in C++ geschrieben und APIs werden für Python bereitgestellt. Python ruft diese APIs auf, entwirft das Trainingsmodell (Graph) und sendet dann das entworfene Diagramm zur Ausführung an das Backend. Kurz gesagt, die Rolle von Python ist Design und die Rolle von C++ ist Ausführen.
1. Vorladedaten:
import tensorflow as tf # 设计Graph x1 = tf.constant([2, 3, 4]) x2 = tf.constant([4, 0, 1]) y = tf.add(x1, x2) # 打开一个session --> 计算y with tf.Session() as sess: print sess.run(y)
2 , Python generiert Daten und leitet die Daten dann an das Backend weiter
import tensorflow as tf
# 设计Graph
x1 = tf.placeholder(tf.int16)
x2 = tf.placeholder(tf.int16)
y = tf.add(x1, x2)
# 用Python产生数据
li1 = [2, 3, 4]
li2 = [4, 0, 1]
# 打开一个session --> 喂数据 --> 计算y
with tf.Session() as sess:
print sess.run(y, feed_dict={x1: li1, x2: li2})
Hinweis: Hier sind x1, x2 nur Platzhaltersymbole Es gibt keinen spezifischen Wert. Wo kann ich den Wert beim Ausführen erhalten? Zu diesem Zeitpunkt müssen Sie den Parameter „feed_dict“ in sess.run () verwenden, um die von Python generierten Daten an das Backend weiterzuleiten und y zu berechnen.
Nachteile dieser beiden Lösungen:
1. Vorabladen: Betten Sie die Daten direkt in das Diagramm ein und übergeben Sie das Diagramm dann zur Ausführung an die Sitzung. Wenn die Datenmenge relativ groß ist, treten bei der Diagrammübertragung Effizienzprobleme auf.
2. Verwenden Sie Platzhalter, um Daten zu ersetzen und die Daten bei der Ausführung einzugeben.
Die ersten beiden Methoden sind sehr praktisch, aber bei großen Datenmengen sind sie sehr schwierig. Selbst beim Feeding stellt der Anstieg der Zwischenverknüpfungen keinen geringen Aufwand dar, z. B. bei der Datentypkonvertierung usw. Die beste Lösung besteht darin, die Dateilesemethode in Graph zu definieren und TF die Daten aus der Datei lesen und in einen verwendbaren Beispielsatz dekodieren zu lassen.
3. Aus der Datei lesen, einfach ausgedrückt, das Diagramm des Datenlesemoduls einrichten
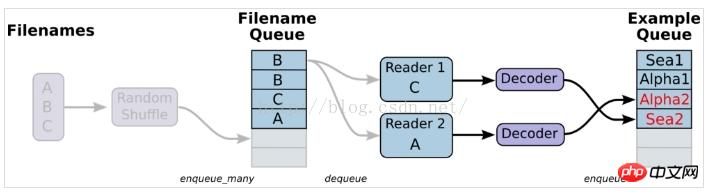
1. Bereiten Sie Daten vor und erstellen Sie drei Dateien, A.csv, B.csv, C.csv
$ echo -e "Alpha1,A1\nAlpha2,A2\nAlpha3,A3" > A.csv $ echo -e "Bee1,B1\nBee2,B2\nBee3,B3" > B.csv $ echo -e "Sea1,C1\nSea2,C2\nSea3,C3" > C.csv
2 >
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
#example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
print example.eval(),label.eval()
coord.request_stop()
coord.join(threads)
Hinweis: tf.train.shuffle_batch wird hier nicht verwendet, was dazu führt, dass die generierten Samples und Labels nicht einander entsprechen und nicht in der richtigen Reihenfolge sind. Die generierten Ergebnisse lauten wie folgt: Alpha1 A2Lösung: Verwenden Sie tf.train.shuffle_batch, dann können die generierten Ergebnisse übereinstimmen.Alpha3 B1
Bee2 B3
Sea1 C2
Sea3 A1
Alpha2 A3
Bee1 B2
Bee3 C1
Sea2 C3
Alpha1 A2
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
3. Einzelner Reader, mehrere Beispiele, hauptsächlich implementiert durch tf.train.shuffle_batch
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
Erklärung: In der folgenden Schreibweise sind die extrahierten Batch_Size-Samples, Features und Labels ebenfalls nicht synchron #-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print example_batch.eval(), label_batch.eval()
coord.request_stop()
coord.join(threads)
Erklärung: Das Ausgabeergebnis lautet wie folgt: Es ist ersichtlich, dass keine Übereinstimmung zwischen Merkmal und Beschriftung besteht['Alpha1' 'Alpha2' 'Alpha3' 'Bee1 ' 'Bee2'] ['B3' 'C1' 'C2' 'C3' 'A1']4. Mehrere Leser, mehrere Beispiele['Alpha2' 'Alpha3' 'Bee1' 'Bee2' 'Bee3'] ['C1' 'C2' ' C3' 'A1' 'A2']
['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Sea1'] ['C2' 'C3' 'A1' 'A2' 'A3']
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
Die Funktionen tf.train.batch und tf.train.shuffle_batch sind einzelne Leser liest, kann aber Multithread sein. tf.train.batch_join und tf.train.shuffle_batch_join können mehrere Leser zum Lesen einrichten, und jeder Leser verwendet einen Thread. Was die Effizienz der beiden Methoden betrifft, so haben mit einem einzigen Reader zwei Threads die Geschwindigkeitsbegrenzung erreicht. Wenn mehrere Leser vorhanden sind, erreichen 2 Leser das Limit. Es bedeutet also nicht, dass mehr Threads schneller sind oder dass noch mehr Threads die Effizienz verringern. #-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
#num_epoch: 设置迭代数
filename_queue = tf.train.string_input_producer(filenames, shuffle=False,num_epochs=3)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=1)
#初始化本地变量
init_local_op = tf.initialize_local_variables()
with tf.Session() as sess:
sess.run(init_local_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop():
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
except tf.errors.OutOfRangeError:
print('Epochs Complete!')
finally:
coord.request_stop()
coord.join(threads)
coord.request_stop()
coord.join(threads)
Denken Sie bei der Iterationssteuerung daran, tf.initialize_local_variables() hinzuzufügen. Das offizielle Website-Tutorial erklärt es nicht, aber wenn es nicht initialisiert wird, wird beim Ausführen ein Fehler gemeldet. 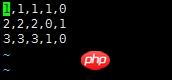
说明:对于该数据,前三列代表的是feature,因为是分类问题,后两列就是经过one-hot编码之后得到的label
使用队列读取该csv文件的代码如下:
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value,record_defaults=record_defaults)
features = tf.pack([col1, col2, col3])
label = tf.pack([col4,col5])
example_batch, label_batch = tf.train.shuffle_batch([features,label], batch_size=2, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
输出结果如下:
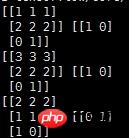
说明:
record_defaults = [[1], [1], [1], [1], [1]]
代表解析的模板,每个样本有5列,在数据中是默认用‘,'隔开的,然后解析的标准是[1],也即每一列的数值都解析为整型。[1.0]就是解析为浮点,['null']解析为string类型
相关推荐:
TensorFlow入门使用 tf.train.Saver()保存模型
关于Tensorflow中的tf.train.batch函数
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der drei Möglichkeiten zum Laden von Daten in Tensorflow. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)