
Heim >Backend-Entwicklung >Python-Tutorial >Beispiel für die Verwendung von Python zur Ausgabe von PDF in TXT
Beispiel für die Verwendung von Python zur Ausgabe von PDF in TXT

- 不言Original
- 2018-04-23 15:16:592326Durchsuche
Das Folgende ist ein Beispiel für die Verwendung von Python zur Ausgabe von PDF-Dateien in TXT. Es hat einen guten Referenzwert und ich hoffe, dass es für alle hilfreich ist. Lass uns einen Blick darauf werfen
Ein Klassenkamerad hat mich vor einer Woche danach gefragt. Da ich schon einmal am Huawei-Wettbewerb teilgenommen habe, habe ich mir den Wettbewerb angesehen und herausgefunden, dass ich das pdfminer-Paket verwenden muss. Also habe ich es installiert und der Installationsprozess war sehr einfach:
sudo pip install pdfminer;
Es gab keine Fehler in der Mitte. Wie man es nennt, ich habe die PDFMiner-Bibliothek nicht sehr gut studiert, also habe ich Baidu gestartet ...
Offizielle Dokumentation: http://www .unixuser .org/~euske/python/pdfminer/index.html
Komplett in Python geschrieben. (Gilt für Version 2.4 oder neuer)
PDF-Dokumente analysieren, analysieren und konvertieren.
Unterstützung der PDF-1.7-Spezifikation. (Fast)
CJK-Sprache und vertikale Schreibskriptunterstützung.
Unterstützung für verschiedene Schriftarten (Type1, TrueType, Type3 und CID).
Basisverschlüsselung (RC4)-Unterstützung.
PDF- und HTML-Konvertierung.
Extraktion der Gliederung (TOC).
Tag-Inhaltsextraktion.
Erstellen Sie das ursprüngliche Layout neu, indem Sie Textblöcke gruppieren.
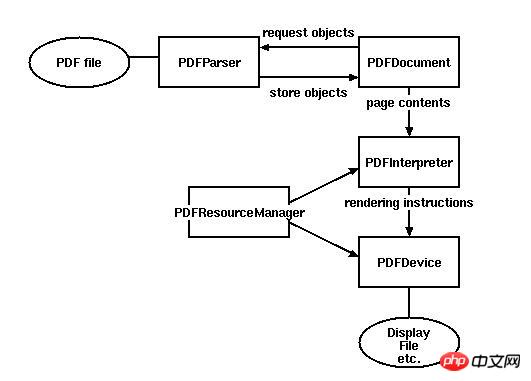
Einige Grundklassen
PDFParser: Daten aus einer Datei abrufen
PDFDocument: Die erhaltenen Daten speichern, und PDFParser ist interlated
PDFPageInterpreter verarbeitet den Seiteninhalt
PDFDevice übersetzt ihn in das von Ihnen benötigte Format
PDFResourceManager wird zum Speichern gemeinsamer Ressourcen wie Schriftarten oder Bilder verwendet.
Einfache Implementierung
Test.pdf lesen und als Output.txt ausgeben:
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
fp = open('test.pdf', 'rb')
#来创建一个pdf文档分析器
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
document = PDFDocument(parser)
# 检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建一个PDF资源管理器对象来存储共赏资源
rsrcmgr=PDFResourceManager()
# 设定参数进行分析
laparams=LAParams()
# 创建一个PDF设备对象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 创建一个PDF解释器对象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 处理每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('output.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')
Verwandte Empfehlungen:
Python-Methode zum Konvertieren von PDF in Bilder
Das obige ist der detaillierte Inhalt vonBeispiel für die Verwendung von Python zur Ausgabe von PDF in TXT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!