
Heim >Backend-Entwicklung >PHP-Tutorial >Zhihu-Benutzerdaten-Crawling und -Analyse auf Millionenebene des PHP-Crawlers
Zhihu-Benutzerdaten-Crawling und -Analyse auf Millionenebene des PHP-Crawlers

- 不言Original
- 2018-04-20 11:58:201910Durchsuche
Der Inhalt dieses Artikels befasst sich mit dem Crawlen und Analysieren von Zhihu-Benutzerdaten durch den PHP-Crawler. Jetzt kann ich ihn mit Ihnen teilen.
In diesem Artikel werden hauptsächlich relevante Informationen zum Crawlen und Analysieren von Zhihu-Benutzerdaten auf PHP-Millionenebene vorgestellt folgende
Vorbereitung vor der Entwicklung
Installieren des Linux-Systems (Ubuntu14 .04 ), installieren Sie ein Ubuntu unter der virtuellen VMWare-Maschine;
-
Installieren Sie PHP5.6 oder höher; >
Installieren Sie MySQL5.5 oder höher; -
Installieren Sie Curl und pcntl-Erweiterungen.
Verwenden Sie die Curl-Erweiterung von PHP, um Seitendaten abzurufen
Dieses Programm erfasst Zhihu-Benutzerdaten. Um auf die persönliche Seite des Benutzers zugreifen zu können, muss der Benutzer vor dem Zugriff angemeldet sein. Wenn wir auf der Browserseite auf einen Benutzer-Avatar-Link klicken, um die persönliche Center-Seite des Benutzers aufzurufen, können wir die Informationen des Benutzers sehen, weil der Browser Ihnen beim Klicken auf den Link dabei hilft, die lokalen Cookies zusammenzubringen und zu senden auf eine neue Seite, sodass Sie die persönliche Center-Seite des Benutzers aufrufen können. Daher müssen Sie vor dem Zugriff auf die persönliche Seite die Cookie-Informationen des Benutzers abrufen und diese dann bei jeder Curl-Anfrage mitbringen. Um Cookie-Informationen zu erhalten, habe ich mein eigenes Cookie verwendet. Sie können Ihre Cookie-Informationen auf der Seite sehen:
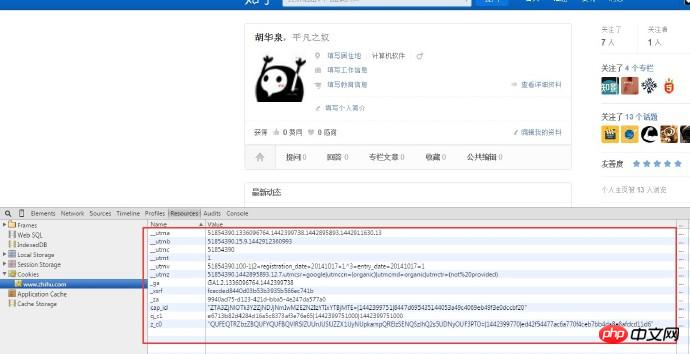 Anfangsbeispiel:
Anfangsbeispiel:
|
1 2 3 4 5 6 7 8 9 |
$url = 'http://www.zhihu.com/people/mora-hu/about'; //此处mora-hu代表用户ID $ch = curl_init($url); //初始化会话 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); //设置请求COOKIE curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $result = curl_exec($ch); return $result; //抓取的结果 |
Führen Sie den obigen Code aus, um die persönliche Center-Seite des mora-hu-Benutzers abzurufen. Mithilfe dieses Ergebnisses und der anschließenden Verarbeitung der Seite mithilfe regulärer Ausdrücke können Sie den Namen, das Geschlecht und andere Informationen erhalten, die Sie erfassen müssen.
1. Anti-Hotlinking von Bildern
Bei der Regularisierung der zurückgegebenen Ergebnisse und der Ausgabe persönlicher Informationen wurde festgestellt, dass der Avatar des Benutzers ausgegeben wurde auf der Seite kann nicht geöffnet werden. Nachdem ich die Informationen überprüft hatte, fand ich heraus, dass es daran lag, dass Zhihu die Bilder vor Hotlinking geschützt hatte. Die Lösung besteht darin, beim Anfordern eines Bildes einen Verweis im Anforderungsheader zu fälschen.
Nachdem Sie den regulären Ausdruck verwendet haben, um den Link zum Bild zu erhalten, senden Sie eine weitere Anfrage. Geben Sie diesmal die Quelle der Bildanfrage an und geben Sie an, dass die Anfrage von der Zhihu-Website weitergeleitet wird. Konkrete Beispiele sind wie folgt:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
function getImg($url, $u_id)
{
if (file_exists('./images/' . $u_id . ".jpg"))
{
return "images/$u_id" . '.jpg';
}
if (empty($url))
{
return '';
}
$context_options = array(
'http' =>
array(
'header' => "Referer:http://www.zhihu.com"//带上referer参数
)
);
$context = stream_context_create($context_options);
$img = file_get_contents('http:' . $url, FALSE, $context);
file_put_contents('./images/' . $u_id . ".jpg", $img);
return "images/$u_id" . '.jpg';
} |
2. Weitere Benutzer crawlen
Nachdem Sie Ihre persönlichen Daten erfasst haben, müssen Sie auf die Follower- und Follower-Liste des Benutzers zugreifen, um weitere Benutzerinformationen zu erhalten. Dann besuchen Sie Schicht für Schicht. Sie können sehen, dass es auf der persönlichen Center-Seite zwei Links wie folgt gibt:
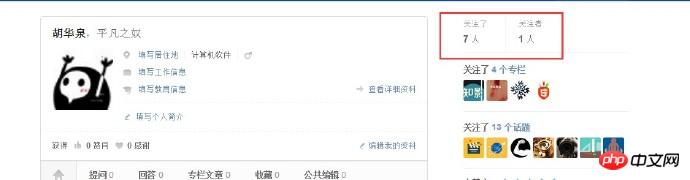
Hier gibt es zwei Links, einer ist zum Folgen, der andere ist für Follower, mit " „Folgen“-Link als Beispiel. Verwenden Sie den regulären Abgleich, um den entsprechenden Link abzugleichen. Nachdem Sie die URL erhalten haben, verwenden Sie Curl, um das Cookie abzurufen und eine weitere Anfrage zu senden. Nachdem Sie die Listenseite gecrawlt haben, der der Benutzer gefolgt ist, können Sie die folgende Seite erhalten:
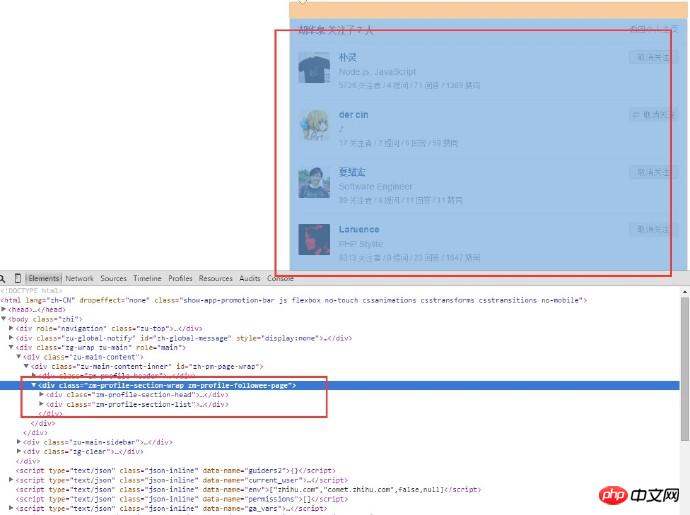
Analysieren Sie den HTML-Code des Seitenstruktur: Da wir nur die Benutzerinformationen abrufen müssen, müssen wir nur den p-Inhalt dieses Teils einrahmen, und der Benutzername ist vollständig darin enthalten. Es ist ersichtlich, dass die URL der Seite, der der Benutzer folgt, lautet:

Die URL verschiedener Benutzer ist fast gleich, der Unterschied liegt im Benutzernamen. Verwenden Sie den regulären Abgleich, um die Benutzernamenliste abzurufen, buchstabieren Sie die URLs einzeln und senden Sie dann die Anforderungen einzeln (einzeln ist natürlich langsamer, es gibt unten eine Lösung, die später besprochen wird). Wiederholen Sie nach dem Aufrufen der Seite des neuen Benutzers die obigen Schritte und fahren Sie in dieser Schleife fort, bis Sie die gewünschte Datenmenge erreicht haben.
3. Anzahl der Linux-Statistikdateien
Nachdem das Skript eine Weile ausgeführt wurde, müssen Sie sehen, wie viele Bilder vorhanden sind Beim Vergleich der Datenmenge ist es etwas langsam, den Ordner zu öffnen und die Anzahl der Bilder anzuzeigen. Das Skript wird in der Linux-Umgebung ausgeführt, sodass Sie Linux-Befehle verwenden können, um die Anzahl der Dateien zu zählen:
1 |
ls-l | grep"^-"wc -l |
Unter diesen ist ls -l eine lange Listenausgabe von Dateiinformationen im Verzeichnis (die Dateien hier können Verzeichnisse, Links, Gerätedateien usw. sein); grep „^-“ filtert die langen Listenausgabeinformationen, „ ^-“ behält nur bei. Wenn bei allgemeinen Dateien nur das Verzeichnis beibehalten wird, ist es „^d“; wc -l ist die Anzahl der Zeilen mit statistischen Ausgabeinformationen. Das Folgende ist ein laufendes Beispiel:
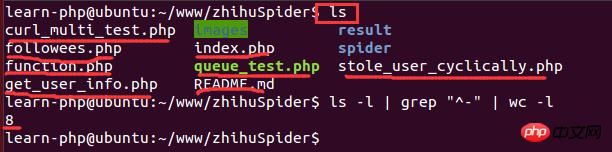
4. Verarbeitung doppelter Daten beim Einfügen in MySQL
Programm läuft Nach einiger Zeit wurde festgestellt, dass viele Benutzerdaten dupliziert waren und daher beim Einfügen doppelter Benutzerdaten verarbeitet werden mussten. Die Lösung lautet wie folgt:
1) Überprüfen Sie, ob die Daten bereits in der Datenbank vorhanden sind, bevor Sie sie in die Datenbank einfügen.
2) Fügen Sie einen eindeutigen Index hinzu und verwenden Sie INSERT INTO...ON DUPLICATE SCHLÜSSEL-UPDATE...
3) Fügen Sie einen eindeutigen Index hinzu, verwenden Sie INSERT INGNORE INTO beim Einfügen...
4) Fügen Sie einen eindeutigen Index hinzu, verwenden Sie REPLACE INTO beim Einfügen...
Die erste Lösung Es ist die einfachste, aber auch die am wenigsten effiziente Lösung und wird daher nicht übernommen. Die Ausführungsergebnisse der zweiten und vierten Lösung sind die gleichen. Der Unterschied besteht darin, dass INSERT INTO ... ON DUPLICATE KEY UPDATE direkt aktualisiert wird, während REPLACE INTO zuerst die alten Daten löscht und dann die neuen einfügt . Während dieses Vorgangs muss der Index neu verwaltet werden, daher ist die Geschwindigkeit langsam. Also habe ich die zweite Option zwischen zwei und vier gewählt. Die dritte Option, INSERT INGNORE, ignoriert Fehler, die beim Ausführen der INSERT-Anweisung auftreten, und ignoriert keine Syntaxprobleme, sondern ignoriert die Existenz des Primärschlüssels. In diesem Fall ist die Verwendung von INSERT INGNORE besser. Angesichts der Anzahl der doppelten Daten, die in der Datenbank aufgezeichnet werden müssen, wurde schließlich die zweite Lösung in das Programm übernommen.
5. Verwenden Sie curl_multi, um eine Multithread-Seitenerfassung zu erreichen
Zu Beginn wurden ein einzelner Prozess und ein einzelner Curl zum Erfassen verwendet Nachdem ich die ganze Nacht aufgelegt und gecrawlt hatte, überlegte ich, ob ich mehrere Benutzer gleichzeitig anfordern könnte, wenn ich eine neue Benutzerseite betrete Ich habe das Gute an curl_multi entdeckt. Funktionen wie „curl_multi“ können mehrere URLs gleichzeitig anfordern, anstatt sie einzeln anzufordern. Dies ähnelt der Funktion eines Prozesses im Linux-System, mehrere Threads zur Ausführung zu öffnen. Das Folgende ist ein Beispiel für die Verwendung von curl_multi zum Implementieren eines Multithread-Crawlers:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
$mh = curl_multi_init(); //返回一个新cURL批处理句柄
for ($i = 0; $i < $max_size; $i++)
{
$ch = curl_init(); //初始化单个cURL会话
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch); //向curl批处理会话中添加单独的curl句柄
}
$user_arr = array();
do {
//运行当前 cURL 句柄的子连接
while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM);
if ($cme != CURLM_OK) {break;}
//获取当前解析的cURL的相关传输信息
while ($done = curl_multi_info_read($mh))
{
$info = curl_getinfo($done['handle']);
$tmp_result = curl_multi_getcontent($done['handle']);
$error = curl_error($done['handle']);
$user_arr[] = array_values(getUserInfo($tmp_result));
//保证同时有$max_size个请求在处理
if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list))
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch);
$i++;
}
curl_multi_remove_handle($mh, $done['handle']);
}
if ($active)
curl_multi_select($mh, 10);
} while ($active);
curl_multi_close($mh);
return $user_arr; |
6. HTTP 429 Too Many Requests
Mit der Funktion „curl_multi“ können Sie mehrere Anfragen gleichzeitig senden, während des Ausführungsprozesses jedoch 200 Anfragen werden gleichzeitig gesendet. Zu diesem Zeitpunkt wurde festgestellt, dass viele Anfragen nicht zurückgegeben werden konnten, dh es wurde ein Paketverlust festgestellt. Verwenden Sie zur weiteren Analyse die Funktion „curl_getinfo“, um die Informationen zu den einzelnen Anforderungshandles auszudrucken. Eines der Felder ist „http_code“, das den von der Anforderung zurückgegebenen HTTP-Statuscode darstellt. Ich habe gesehen, dass der http_code vieler Anfragen 429 war. Dieser Rückkehrcode bedeutet, dass zu viele Anfragen gesendet wurden. Ich vermutete, dass Zhihu einen Anti-Crawler-Schutz implementiert hatte, also habe ich ihn auf anderen Websites getestet und festgestellt, dass es beim gleichzeitigen Senden von 200 Anfragen kein Problem gab, was meine Vermutung bestätigte Die Anzahl der einmaligen Anfragen ist begrenzt. Also reduzierte ich die Anzahl der Anfragen weiter und stellte fest, dass es bei 5 keinen Paketverlust gab. Es zeigt, dass Sie in diesem Programm nur bis zu 5 Anfragen gleichzeitig senden können, obwohl es nicht viele sind, aber eine kleine Verbesserung.
7. Verwenden Sie Redis, um besuchte Benutzer zu speichern
Beim Erfassen von Benutzern wurde festgestellt, dass einige Benutzer bereits besucht wurden. Darüber hinaus wurden seine Follower und folgenden Benutzer bereits abgerufen, obwohl die wiederholte Datenverarbeitung auf Datenbankebene erfolgt, das Programm weiterhin Curl zum Senden von Anforderungen verwendet, sodass das Senden wiederholter Anforderungen einen hohen Netzwerkaufwand verursacht. Eine andere Sache ist, dass die zu erfassenden Benutzer für die nächste Ausführung vorübergehend an einem Ort gespeichert werden müssen. Später stellte ich fest, dass dem Programm mehrere Prozesse hinzugefügt werden müssen Beim Programmieren teilen sich Unterprozesse den Programmcode und die Funktionsbibliothek, aber die vom Prozess verwendeten Variablen unterscheiden sich völlig von denen, die von anderen Prozessen verwendet werden. Variablen zwischen verschiedenen Prozessen sind getrennt und können nicht von anderen Prozessen gelesen werden, sodass Arrays nicht verwendet werden können. Deshalb habe ich darüber nachgedacht, den Redis-Cache zu verwenden, um verarbeitete und zu erfassende Benutzer zu speichern. Auf diese Weise wird der Benutzer jedes Mal, wenn die Ausführung abgeschlossen ist, in eine bereits_request_queue-Warteschlange verschoben, und die zu erfassenden Benutzer (dh die Liste der Follower und verfolgten Benutzer jedes Benutzers) werden in die request_queue und dann davor verschoben Bei jeder Ausführung wird der Benutzer in die Warteschlange „ready_request_queue“ verschoben und dann ermittelt, ob er sich in der Warteschlange „bereits_request_queue“ befindet. Wenn ja, fahren Sie mit der nächsten fort, andernfalls fahren Sie mit der Ausführung fort.
Beispiel für die Verwendung von Redis in PHP:
|
1 2 3 4 5 6 7 8 |
<?php
$redis = new Redis();
$redis->connect('127.0.0.1', '6379');
$redis->set('tmp', 'value');
if ($redis->exists('tmp'))
{
echo $redis->get('tmp') . "\n";
} |
8. Verwenden Sie die pcntl-Erweiterung von PHP, um Multiprozess zu implementieren
Nachdem die Funktion „curl_multi“ zum Implementieren von Multithreading zum Erfassen von Benutzerinformationen verwendet wurde, wurde das Programm ausgeführt Für eine Nacht betragen die endgültigen Daten 10 W. Da ich mein ideales Ziel immer noch nicht erreichen konnte, optimierte ich weiter und entdeckte später, dass es in PHP eine PCNTL-Erweiterung gibt, die eine Multiprozessprogrammierung ermöglichen kann. Hier ist ein Beispiel für Multiprogrammierung:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//PHP多进程demo
//fork10个进程
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
echo "child process $i running\n";
//子进程执行完毕之后就退出,以免继续fork出新的子进程
exit($i);
}
}
//等待子进程执行完毕,避免出现僵尸进程
while (pcntl_waitpid(0, $status) != -1) {
$status = pcntl_wexitstatus($status);
echo "Child $status completed\n";
} |
9、在Linux下查看系统的cpu信息
实现了多进程编程之后,就想着多开几条进程不断地抓取用户的数据,后来开了8调进程跑了一个晚上后发现只能拿到20W的数据,没有多大的提升。于是查阅资料发现,根据系统优化的CPU性能调优,程序的最大进程数不能随便给的,要根据CPU的核数和来给,最大进程数最好是cpu核数的2倍。因此需要查看cpu的信息来看看cpu的核数。在Linux下查看cpu的信息的命令:
1 |
cat /proc/cpuinfo |
Die Ergebnisse lauten wie folgt:
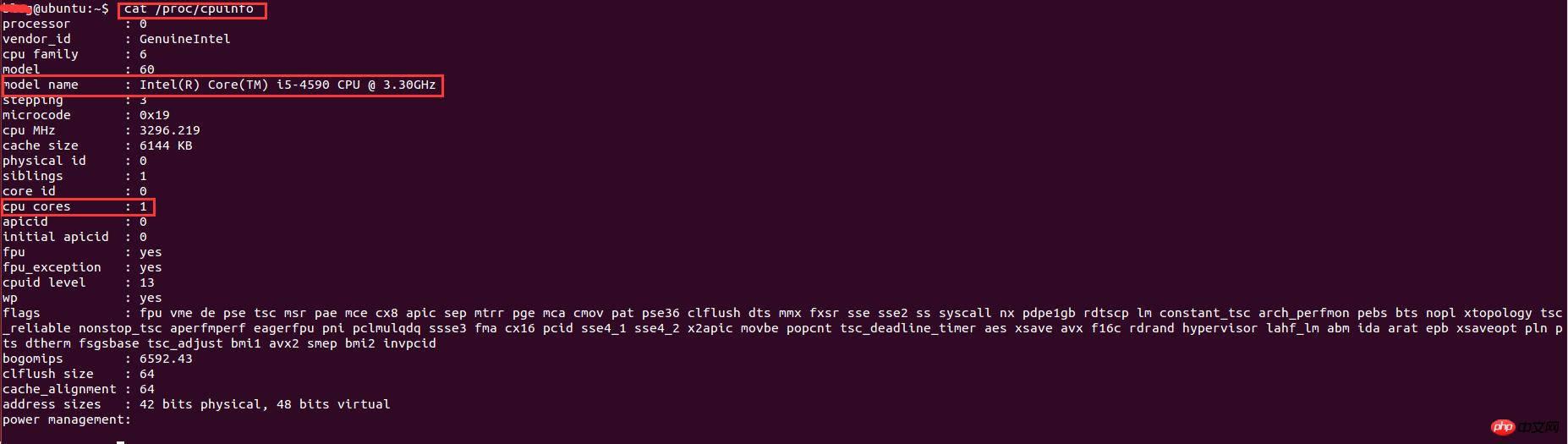
Unter diesen steht der Modellname für Informationen zum CPU-Typ und die CPU-Kerne für die Anzahl der CPU-Kerne. Die Anzahl der Kerne beträgt hier 1. Da es unter einer virtuellen Maschine ausgeführt wird, ist die Anzahl der zugewiesenen CPU-Kerne relativ gering, sodass nur 2 Prozesse geöffnet werden können. Das Endergebnis war, dass an nur einem Wochenende 1,1 Millionen Benutzerdaten erfasst wurden.
10. Redis- und MySQL-Verbindungsprobleme bei der Multiprozessprogrammierung
Unter Multiprozessbedingungen, nachdem das Programm eine Zeit lang ausgeführt wurde Nach einiger Zeit werden Daten gefunden. Sie können nicht in die Datenbank eingefügt werden und es wird ein Fehler gemeldet, dass zu viele MySQL-Verbindungen vorliegen. Dasselbe gilt für Redis.
Der folgende Code kann nicht ausgeführt werden:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<?php
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
$redis = PRedis::getInstance();
// do something
exit;
}
} |
Der Hauptgrund ist, dass jeder untergeordnete Prozess beim Erstellen eine identische Kopie des übergeordneten Prozesses geerbt hat. Objekte können kopiert werden, erstellte Verbindungen können jedoch nicht in mehrere kopiert werden. Das Ergebnis ist, dass jeder Prozess dieselbe Redis-Verbindung verwendet und sein eigenes Ding ausführt, was schließlich zu unerklärlichen Konflikten führt.
Lösung: >Das Programm kann nicht vollständig garantieren, dass der übergeordnete Prozess vor dem Fork-Prozess keine Redis-Verbindungsinstanz erstellt. Daher kann dieses Problem nur durch den untergeordneten Prozess selbst gelöst werden. Stellen Sie sich vor, wenn die im untergeordneten Prozess erhaltene Instanz nur mit dem aktuellen Prozess zusammenhängt, besteht dieses Problem nicht. Die Lösung besteht also darin, die statische Methode der Redis-Klasseninstanziierung leicht zu ändern und sie an die aktuelle Prozess-ID zu binden.
Der transformierte Code lautet wie folgt:
|
1 2 3 4 5 6 7 8 9 10 |
<?php
public static function getInstance() {
static $instances = array();
$key = getmypid();//获取当前进程ID
if ($empty($instances[$key])) {
$inctances[$key] = new self();
}
return $instances[$key];
} |
11. PHP-Statistik-Skriptausführungszeit
Da ich wissen möchte, wie viel Zeit jeder Prozess benötigt, habe ich eine Funktion geschrieben, um die Skriptausführungszeit zu zählen :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function microtime_float()
{
list($u_sec, $sec) = explode(' ', microtime());
return (floatval($u_sec) + floatval($sec));
}
$start_time = microtime_float();
//do something
usleep(100);
$end_time = microtime_float();
$total_time = $end_time - $start_time;
$time_cost = sprintf("%.10f", $total_time);
echo "program cost total " . $time_cost . "s\n"; |
Das Obige ist der gesamte Inhalt dieses Artikels als Referenz. Ich hoffe, er wird für Ihr Studium hilfreich sein.
Verwandte Empfehlungen:
Verwenden Sie den PHP-Crawler, um die Immobilienpreise in Nanjing zu analysieren
Das obige ist der detaillierte Inhalt vonZhihu-Benutzerdaten-Crawling und -Analyse auf Millionenebene des PHP-Crawlers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)