
Heim >Backend-Entwicklung >Python-Tutorial >Der DataFrame von Python implementiert Excel Merged Cells_Python
Der DataFrame von Python implementiert Excel Merged Cells_Python

- 不言Original
- 2018-04-02 16:19:2110036Durchsuche
Dieser Artikel stellt hauptsächlich den DataFrame in Python vor, um das Zusammenführen von Zellen in Excel zu implementieren. Er hat einen gewissen Referenzwert.
Ich stoße oft auf die Notwendigkeit, Zellen bei der Arbeit zusammenzuführen wird in Excel ausgegeben und einige der Zellen müssen zusammengeführt werden. In der folgenden Tabelle müssen beispielsweise die entsprechenden Zellen in den Spalten B und C basierend auf dem Wert von Spalte A

2. Definieren Sie eine my_mergewr_excel-Methode. Die Parameter sind: der Pfad zur Excel-Ausgabe, die Liste key_cols, die verwendet wird, um zu bestimmen, ob sie zusammengeführt werden muss, und die Liste, die verwendet wird, um anzugeben, welche Spalten von Zellen zusammengeführt werden müssen >3. Ändern Sie den MY_DataFrame Encapsulated als My_Module-Modul zur Wiederverwendung.
Der Zusammenführungsalgorithmus ist wie folgt:
1. Führen Sie eine Gruppenzählung und -sortierung gemäß der [Schlüsselspalte] der angegebenen Parameter durch und fügen Sie zwei Hilfsspalten CN und RN hinzu
3. Beurteilen Sie entsprechend der Gruppe, die zusammengeführt werden muss, die aktuelle Spalte. Ob sie sich im angegebenen Parameter [Spalte zusammenführen] befindet. Wenn ja, verwenden Sie Zusammenführen, um Excel-Zellen zu schreiben, andernfalls schreiben Sie einfach Excel Zellen normal.
4. Rufen Sie in der Spalte, die zusammengeführt werden muss, merge_range auf und schreiben Sie sofort CN-Zellen. Wenn RN>1, überspringen Sie die Zelle, da in RN=1 die Zelle vorhanden war Wenn erge_range wiederholt aufgerufen wird, wird beim Öffnen des Excel-Dokuments ein Fehler gemeldet.
Die Erklärung mit Bildern lautet wie folgt:
 Der spezifische Code lautet wie folgt:
Der spezifische Code lautet wie folgt:
# -*- coding: utf-8 -*-
"""
Created on 20170301
@author: ARK-Z
"""
import xlsxwriter
import pandas as pd
class My_DataFrame(pd.DataFrame):
def __init__(self, data=None, index=None, columns=None, dtype=None, copy=False):
pd.DataFrame.__init__(self, data, index, columns, dtype, copy)
def my_mergewr_excel(self,path,key_cols=[],merge_cols=[]):
# sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True):
self_copy=My_DataFrame(self,copy=True)
line_cn=self_copy.index.size
cols=list(self_copy.columns.values)
if all([v in cols for i,v in enumerate(key_cols)])==False: #校验key_cols中各元素 是否都包含与对象的列
print("key_cols is not completely include object's columns")
return False
if all([v in cols for i,v in enumerate(merge_cols)])==False: #校验merge_cols中各元素 是否都包含与对象的列
print("merge_cols is not completely include object's columns")
return False
wb2007 = xlsxwriter.Workbook(path)
worksheet2007 = wb2007.add_worksheet()
format_top = wb2007.add_format({'border':1,'bold':True,'text_wrap':True})
format_other = wb2007.add_format({'border':1,'valign':'vcenter'})
for i,value in enumerate(cols): #写表头
#print(value)
worksheet2007.write(0,i,value,format_top)
#merge_cols=['B','A','C']
#key_cols=['A','B']
if key_cols ==[]: #如果key_cols 参数不传值,则无需合并
self_copy['RN']=1
self_copy['CN']=1
else:
self_copy['RN']=self_copy.groupby(key_cols,as_index=False).rank(method='first').ix[:,0] #以key_cols作为是否合并的依据
self_copy['CN']=self_copy.groupby(key_cols,as_index=False).rank(method='max').ix[:,0]
#print(self)
for i in range(line_cn):
if self_copy.ix[i,'CN']>1:
#print('该行有需要合并的单元格')
for j,col in enumerate(cols):
#print(self_copy.ix[i,col])
if col in (merge_cols): #哪些列需要合并
if self_copy.ix[i,'RN']==1: #合并写第一个单元格,下一个第一个将不再写
worksheet2007.merge_range(i+1,j,i+int(self_copy.ix[i,'CN']),j, self_copy.ix[i,col],format_other) ##合并单元格,根据LINE_SET[7]判断需要合并几个
#worksheet2007.write(i+1,j,df.ix[i,col])
else:
pass
#worksheet2007.write(i+1,j,df.ix[i,j])
else:
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
#print(',')
else:
#print('该行无需要合并的单元格')
for j,col in enumerate(cols):
#print(df.ix[i,col])
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
wb2007.close()
self_copy.drop('CN', axis=1)
self_copy.drop('RN', axis=1)Rufvorwahl:
import My_Module
DF=My_DataFrame({'A':[1,2,2,2,3,3],'B':[1,1,1,1,1,1],'C':[1,1,1,1,1,1],'D':[1,1,1,1,1,1]})
DF
Out[120]:
A B C D
0 1 1 1 1
1 2 1 1 1
2 2 1 1 1
3 2 1 1 1
4 3 1 1 1
5 3 1 1 1
DF.my_mergewr_excel('000_2.xlsx',['A'],['B','C'])Der Effekt ist wie folgt:
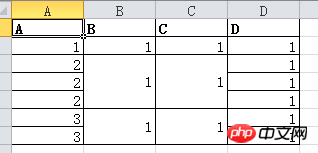 Außerdem können Sie die Zusammenführung der Spalten A und B einrichten:
Außerdem können Sie die Zusammenführung der Spalten A und B einrichten:
DF.my_mergewr_excel('000_2.xlsx',['A'],['A','B'])
Der Effekt ist wie folgt:
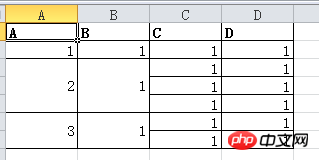
Das obige ist der detaillierte Inhalt vonDer DataFrame von Python implementiert Excel Merged Cells_Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!