
Heim >Backend-Entwicklung >Python-Tutorial >So schreiben Sie ein vollständiges Crawler-Framework
So schreiben Sie ein vollständiges Crawler-Framework

- 零到壹度Original
- 2018-03-30 11:28:404803Durchsuche
Dieser Artikel zeigt Ihnen hauptsächlich, wie Sie eine Anforderungsmethode für ein Crawler-Framework vollständig schreiben. Er hat einen guten Referenzwert und ich hoffe, dass er für alle hilfreich sein wird. Folgen wir dem Herausgeber, um einen Blick darauf zu werfen. Ich hoffe, es kann allen helfen.
Crawler-Framework generieren:
1. Erstellen Sie ein Scrapy-Crawler-Projekt
2 Scrapy-Crawler wird im Projekt generiert
3. Konfigurieren Sie den Spider-Crawler
4. Führen Sie den Crawler aus und rufen Sie die Webseite ab
Spezifische Vorgänge:
1. Erstellen Sie ein Projekt
Definieren Sie ein Projekt mit dem Namen: python123demo
Methode:
In cmd, d: Geben Sie das Laufwerk d ein, cd pycodes Geben Sie die Datei pycodes ein
Dann geben Sie
scrapy startproject python123demo
Eine Datei wird in Pycodes generiert:


_init_.py erfordert keine Benutzereingabe


2. Erzeugen Sie einen Scrapy-Crawler im Projekt
Führen Sie einen Befehl aus, um den Crawler-Namen und die gecrawlte Website zu generieren
Crawler generieren:

Generieren Sie einen Namen. Die Spinne
für Demo kann nur demo.py generieren, ihr Inhalt ist:

name = 'demo' Der aktuelle Crawler-Name ist demo
allowed_domains = " Crawlen Sie die Links unter dem Domänennamen der Website. Der Domänenname wird von eingegeben cmd-Befehlskonsole
start_urls = [] Gecrawlte Startseite
parse() wird verwendet, um die Antwort zu verarbeiten und den Inhalt zu analysieren, um eine zu bilden Wörterbuch und entdecken Sie neue URL-Crawling-Anfragen
3. Konfigurieren Sie den generierten Spider-Crawler entsprechend unseren Anforderungen
Speichern die analysierte Seite in eine Datei
Ändern Sie die demo.py-Datei

4. Führen Sie den Crawler aus und rufen Sie die Webseite ab
Öffnen Sie cmd und geben Sie die Befehlszeile zum Crawlen ein

Dann erschien auf meinem Computer ein Fehler
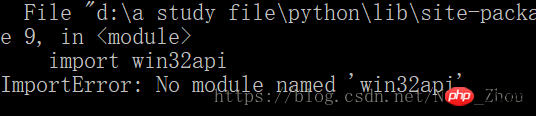
Um dieses Problem auf dem Windows-System zu lösen, Sie müssen das Py32Win-Modul installieren, aber die direkte Installation der Exe über den offiziellen Website-Link führt zu Hunderten von Fehlern. Der bequemere Weg ist
pip3 install pypiwin32
Dies ist die Lösung für py3
Hinweis: Wenn Sie das verwenden pip install pypiwin32-Befehl für die py3-Version, ein Fehler tritt auf
Nachdem die Installation abgeschlossen ist, führen Sie den Crawler erneut aus, Erfolg! Werfen Sie Blumen!
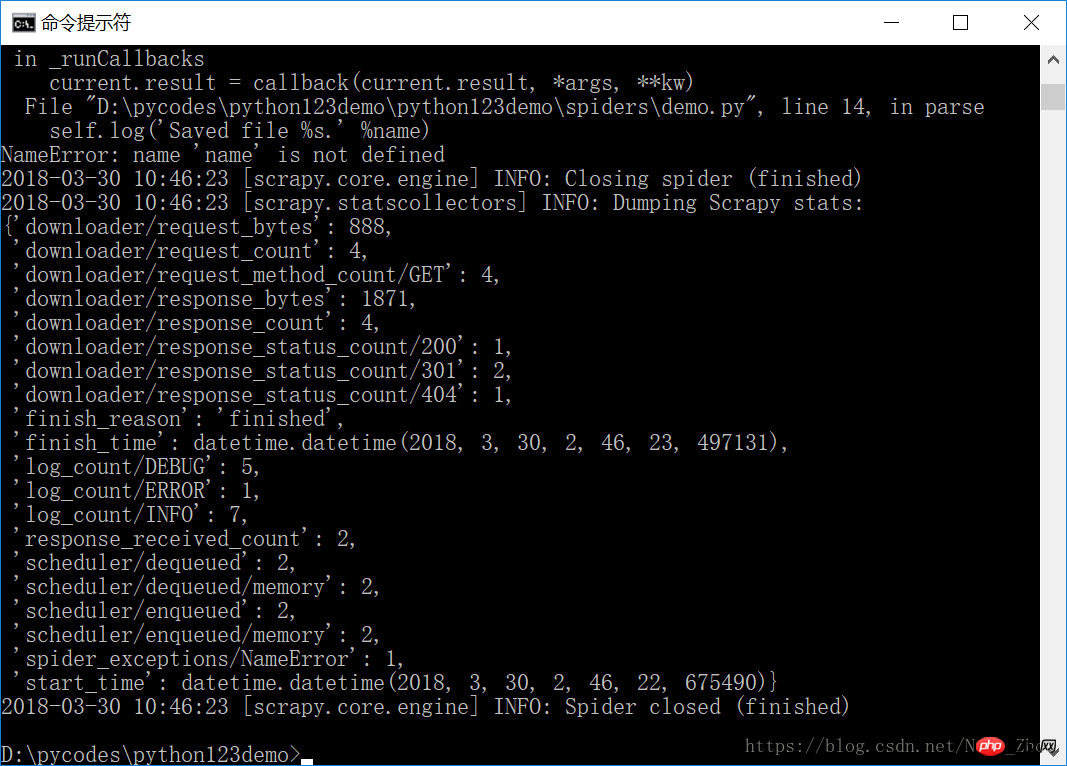
Die erfasste Seite wird in der Datei demo.html gespeichert

Der vollständige Code, der demo.py entspricht:

Die beiden Versionen sind gleichwertig:

Das obige ist der detaillierte Inhalt vonSo schreiben Sie ein vollständiges Crawler-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!