
Heim >Web-Frontend >js-Tutorial >Analysieren Sie die Prinzipien und die Syntax von JS-Regex
Analysieren Sie die Prinzipien und die Syntax von JS-Regex
- php中世界最好的语言Original
- 2018-03-29 16:17:431818Durchsuche
Dieses Mal werde ich Ihnen die Prinzipien und die Syntax des Parsens von JS-Regex vorstellen. Was sind die Vorsichtsmaßnahmen für das Parsen der Prinzipien und Syntax von JS-Regex?
Zhengze ist wie ein Leuchtturm, wenn man im Meer der Fäden ratlos ist. Zhengze ist wie ein Banknotendetektor Die Banknoten, die Sie einreichen, sind echt oder gefälscht, es kann Ihnen immer helfen, sie auf einen Blick zu erkennen; Regelmäßigkeit ist wie eine Taschenlampe, wenn Sie etwas finden müssen, kann es Ihnen immer helfen, das zu bekommen, was Sie wollen...
——Auszug aus Stinsons chinesischer Parallelsatzübung „Regular“
Nachdem wir einen literarischen Auszug gewürdigt haben, werden wir die regulären Regeln in JS formell klären. Der Hauptzweck dieses Artikels besteht darin, zu verhindern, dass ich einige reguläre Sätze vergesse Regeln zur Verwendung, also habe ich sie aussortiert und aufgeschrieben, um die Kenntnisse zu verbessern und sie als Referenz zu verwenden. Wenn es Fehler gibt, können Sie mich gerne aufklären .
Da dieser Artikel den Titel „Ein Drache“ trägt, muss er des „Drachen“ würdig sein, daher enthält er Regelmäßigkeitsprinzipien, Syntaxübersicht, Regelmäßigkeit in JS (ES5), ES6-Erweiterung der Regelmäßigkeit und Ideen Um die Regelmäßigkeit zu üben, versuche ich, diese Dinge so ausführlich wie möglich und auf einfache Weise zu erklären (als ob ich sie wirklich auf einfache Weise erklären könnte, dann lesen Sie den zweiten, dritten). und fünfte Teile, die im Grunde Ihren Bedürfnissen entsprechen. Wenn Sie die regulären Regeln in JS beherrschen möchten, dann folgen Sie besser meinen Ideen, hey hey hey!
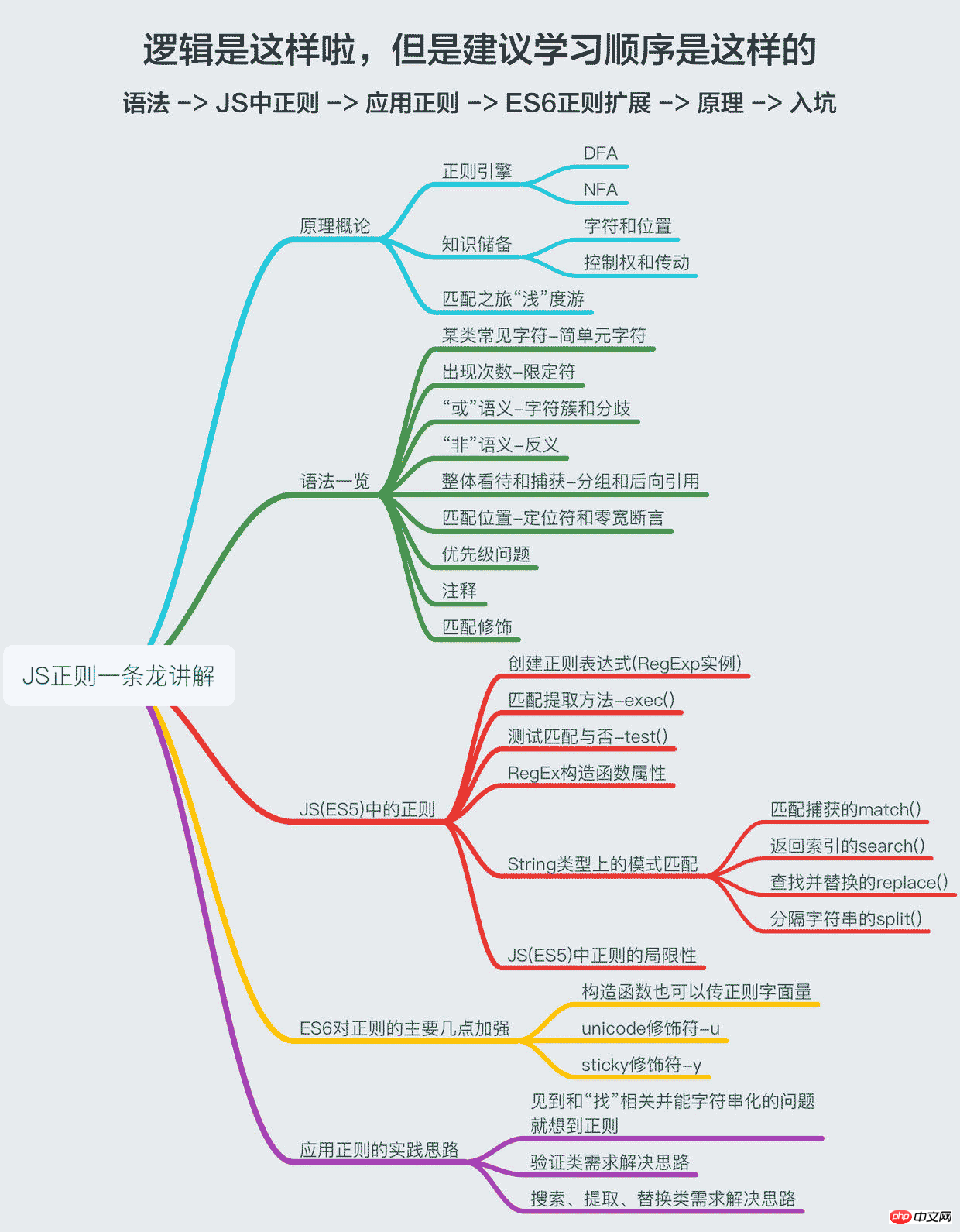
1. Einführung in die Prinzipien
Als ich anfing, reguläre Ausdrücke zu verwenden, fand ich es erstaunlich, wie der Computer sie nutzen kann ein Regulärer Ausdruck zum Abgleichen von Zeichenfolgen? Erst später stieß ich auf ein Buch mit dem Titel „Computational Theory“ und erkannte die Konzepte und Zusammenhänge zwischen Regelmäßigkeit, DFA und NFA, und plötzlich hatte ich eine gewisse Erleuchtung.
Aber wenn Sie reguläre Ausdrücke wirklich im Prinzip verstehen wollen, dann ist meiner Meinung nach der beste Weg:
1 Suchen Sie zunächst ein Buch speziell über reguläre Ausdrücke, O’REILLYs „There is one in“. die „Animal Story“-Reihe;
2. Implementieren Sie dann selbst eine reguläre Engine.
Der Schwerpunkt dieses Artikels liegt auf der Anwendung regulärer Ausdrücke in JS, daher wird das Prinzip nur kurz vorgestellt (da ich noch nie eine reguläre Engine geschrieben habe und nicht näher darauf eingehen werde), bis ungefähr " „Du täuschst“ neugierige Menschen wie mich. Für Babys, die Zweifel an Regelmäßigkeitsprinzipien haben, ist zweitens das Wissen über einige Grundkenntnisse der Prinzipien sehr hilfreich, um die Grammatik zu verstehen und Regelmäßigkeiten zu schreiben.
1. Regelmäßigkeit kann effektiv sein, weil es einen JS-Motor gibt Die so genannte Regularitäts-Engine kann als verstanden werden. Verwenden Sie einen Algorithmus, um eine Maschine basierend auf Ihrem regulären Ausdruck zu simulieren. Durch das Lesen der zu testenden Zeichenfolge springt sie schließlich zwischen diesen Zuständen „Endzustand“ (Happy End), dann „Say I Do“, andernfalls „Say You Are a Good Man“
. Durch die Umwandlung eines regulären Ausdrucks in eine Maschine, die das Ergebnis in einer begrenzten Anzahl von Schritten berechnen kann, wird eine Engine implementiert.
1. DFA (Deterministischer endlicher Automat) 2 Automat) Nichtdeterministischer endlicher Automat, die meisten davon sind NFA
Das „deterministische“ bedeutet hier, dass sich der Zustand dieser Maschine bei der Eingabe eines bestimmten Zeichens definitiv von a Springen nach b, „nicht“ ändern wird -deterministisch“ bedeutet, dass die Maschine für die Eingabe eines bestimmten Zeichens mehrere Sprungzustände haben kann; „endlich“ bedeutet hier, dass der Zustand begrenzt ist und in einer begrenzten Anzahl von Schritten gesprungen werden kann. Bestimmen Sie, ob eine bestimmte Zeichenfolge akzeptiert wird oder innerhalb weniger Sekunden eine gute Karte ausgegeben hat; der „Automat“ kann hier so verstanden werden, dass man, sobald die Regeln dieses Automaten festgelegt sind, sein eigenes Urteil bilden kann, ohne dass jemand darauf schaut.
Die DFA-Engine muss nicht zurückverfolgt werden, sodass die Matching-Effizienz im Allgemeinen hoch ist. Sie unterstützt jedoch keine Erfassungsgruppen und unterstützt daher weder umgekehrte Referenzen noch Referenzen in Form von $ Look-Arounds (Lookaround), Non-Greedy-Modus und andere einzigartige Funktionen der NFA-Engine.
Wenn Sie mehr über reguläre Ausdrücke, DFA und NFA erfahren möchten, können Sie „Computertheorie“ lesen und dann einen Automaten basierend auf einem bestimmten regulären Ausdruck zeichnen.
2. WissensreserveDieser Abschnitt ist sehr nützlich, um reguläre Ausdrücke zu verstehen, insbesondere was ein Zeichen und eine Position ist.
2.1 String im Sinne eines regulären Ausdrucks – n Zeichen, n+1 Positionen

In der Zeichenfolge „Lachen“ oben gibt es insgesamt 8 Zeichen, die Sie sehen können, und 9 Positionen, die nur kluge Leute sehen können. Angekommen. Warum brauchen wir Charaktere und Positionen? Weil der Standort angepasst werden kann.
Dann gehen wir weiter, um „besetzte Zeichen“ und „Nullbreite“ zu verstehen:
Wenn ein unterregulärer Ausdruck mit Zeichen und nicht mit Positionen übereinstimmt, wird er gespeichert im Endergebnis. Beispiel: /ha/ (trifft auf ha zu) belegt Zeichen; Der Inhalt wird nicht im Ergebnis gespeichert (tatsächlich kann er auch als Position betrachtet werden). Dann hat dieser Unterausdruck eine Breite von Null, z. B. /read(?=ing)/ (entspricht dem Lesen, fügt aber nur read in das Ergebnis ein . Die Syntax wird im Folgenden ausführlich beschrieben. (?=ing) ist eine Nullbreite und stellt im Wesentlichen eine Position dar.
Besitzende Zeichen schließen sich gegenseitig aus, die Breite Null schließt sich nicht gegenseitig aus. Das heißt, ein Zeichen kann nur mit einem Unterausdruck gleichzeitig übereinstimmen, eine Position kann jedoch mit mehreren Unterausdrücken mit der Breite Null gleichzeitig übereinstimmen. Beispielsweise kann /aa/ nicht mit a übereinstimmen. Das a in dieser Zeichenfolge kann nur mit dem ersten a des regulären Ausdrucks übereinstimmen, nicht aber gleichzeitig mit dem zweiten a (Unsinn). multiple Beispielsweise kann /bba/ mit a übereinstimmen. Obwohl es zwei b-Metazeichen gibt, die den Wortanfang im regulären Ausdruck angeben, können diese beiden b gleichzeitig mit der Position 0 (in diesem Beispiel) übereinstimmen.
Hinweis: Bei Zeichenfolgen sprechen wir von Zeichen und Positionen, bei regulären Ausdrücken hingegen von besetzten Zeichen und der Breite Null.
Kontrolle
bezieht sich darauf, welcher reguläre Unterausdruck (der aus einem gewöhnlichen Zeichen, Metazeichen oder einer Metazeichenfolge bestehen kann) mit der Zeichenfolge übereinstimmt und wo sich dann die Steuerung befindet.
Übertragung bezieht sich auf einen Mechanismus des regulären Motors. Das Übertragungsgerät ermittelt, wo in der Zeichenfolge das reguläre Spiel beginnt.
Wenn ein regulärer Ausdruck mit der Übereinstimmung beginnt, übernimmt normalerweise ein Unterausdruck die Kontrolle und versucht ab einer bestimmten Position in der Zeichenfolge eine Übereinstimmung herzustellen. Die Position, an der ein Unterausdruck mit der Übereinstimmung beginnt, ist die vorherige die Endposition eines erfolgreichen Spiels. Als Beispiel: read(?=ing)ingsbook entspricht reading book. Wir betrachten diesen regulären Ausdruck als fünf Unterausdrücke: read, (?=ing), ing, s und book can too read wird als Unterausdruck aus vier separaten Zeichen behandelt, aber wir behandeln es hier der Einfachheit halber so. read beginnt bei Position 0 und stimmt mit Position 4 überein. Das Folgende (?=ing) stimmt weiterhin ab Position 4 überein. Es wird festgestellt, dass auf Position 4 tatsächlich ing folgt, sodass behauptet wird, dass die Übereinstimmung erfolgreich ist, d. h Das Ganze (?=ing) stimmt mit der Position 4 überein (Sie können hier besser verstehen, was Nullbreite ist), und dann stimmt das folgende ing von Position 4 mit Position 7 überein, dann stimmt s mit Position 7 mit Position 8 überein , und die letzten Buchmatches ab Position 8. Bei Position 12 ist das gesamte Match abgeschlossen.
3. „Flache“ Matching-Reise (kann übersprungen werden) Nachdem wir so viel gesagt haben, betrachten wir uns Schritt für Schritt als einen normalen Motor in der kleinsten Einheit - - " „Charakter“ und „Position“ – Schauen wir uns den Prozess des regulären Matchings an und geben einige Beispiele.3.1 Grundlegende Übereinstimmung Regulärer Ausdruck: einfach
Quellzeichenfolge: So einfach
3.2 Nullbreiten-Matching
匹配过程:首先正则的^(表示字符串开始的位置)获取控制权,从位置0开始匹配,匹配成功,控制权交给(?=[aeiou]),这个子表达式要求该位置右边必须是元音小写字母中的一个,零宽子表达式相互间不互斥,所以从位置0开始尝试匹配,右侧是字符串的‘a',符合因此匹配成功,所以(?=[aeiou])匹配此处的位置0匹配成功,控制权交给[a-z]+,从位置0开始匹配,字符串‘apple'中的每个字符都匹配成功,匹配到字符串末尾,控制权交回正则的$,尝试匹配字符串结束位置,成功,至此,整个匹配完成。
3.3 贪婪匹配和非贪婪匹配
正则1:{.*}
正则2:{.*?}
源字符串:{233}
这里有两个正则,在限定符(语法会讲什么是限定符)后面加?符号表示忽略优先量词,也就是非贪婪匹配,这个栗子我剥得快一点。
首先开头的{匹配,两个正则都是一样的表现。
正则1的.*为贪婪匹配,所以一直匹配余下字符串'233}',匹配到字符串结束位置,只是每次匹配,都记录一个备选状态,为了以后回溯,每次匹配有两条路,选择了匹配这条路,但记一下这里还可以有不匹配这条路,如果前面死胡同了,可以退回来,此时控制权交还给正则的},去匹配字符串结束位置,失败,于是回溯,意思就是说前面的.*你吃的太多了,吐一个出来,于是控制权回给.*,吐出一个}(其实是用了前面记录的备选状态,尝试不用.*去匹配'}'),控制权再给正则的},这次匹配就成功了。
正则2的.*?为非贪婪匹配,尽可能少地匹配,所以匹配'233}'的每一个字符的时候,都是尝试不匹配,但是一但控制权交还给最后的}就发现出问题了,赶紧回溯乖乖匹配,于是每一个字符都如此,最终匹配成功。
云里雾里?这就对了!可以移步去下面推荐的博客看看:
想详细了解贪婪和非贪婪匹配原理以及获取更多正则相关原理,除了看书之外,推荐去一个CSDN的博客 雁过无痕-博客频道 - CSDN.NET ,讲解得很详细和透彻
二、语法一览
正则的语法相信许多人已经看过deerchao写的30分钟入门教程,我也是从那篇文字中入门的,deerchao从语法逻辑的角度以.NET正则的标准来讲述了正则语法,而我想重新组织一遍,以便于应用的角度、以JS为宿主语言来重新梳理一遍语法,这将便于我们把语言描述翻译成正则表达式。
下面这张一览图(可能需要放大),整理了常用的正则语法,并且将JS不支持的语法特性以红色标注出来了(正文将不会描述这些不支持的特性),语法部分的详细描述也将根据下面的图,从上到下,从左到右的顺序来梳理,尽量不啰嗦。
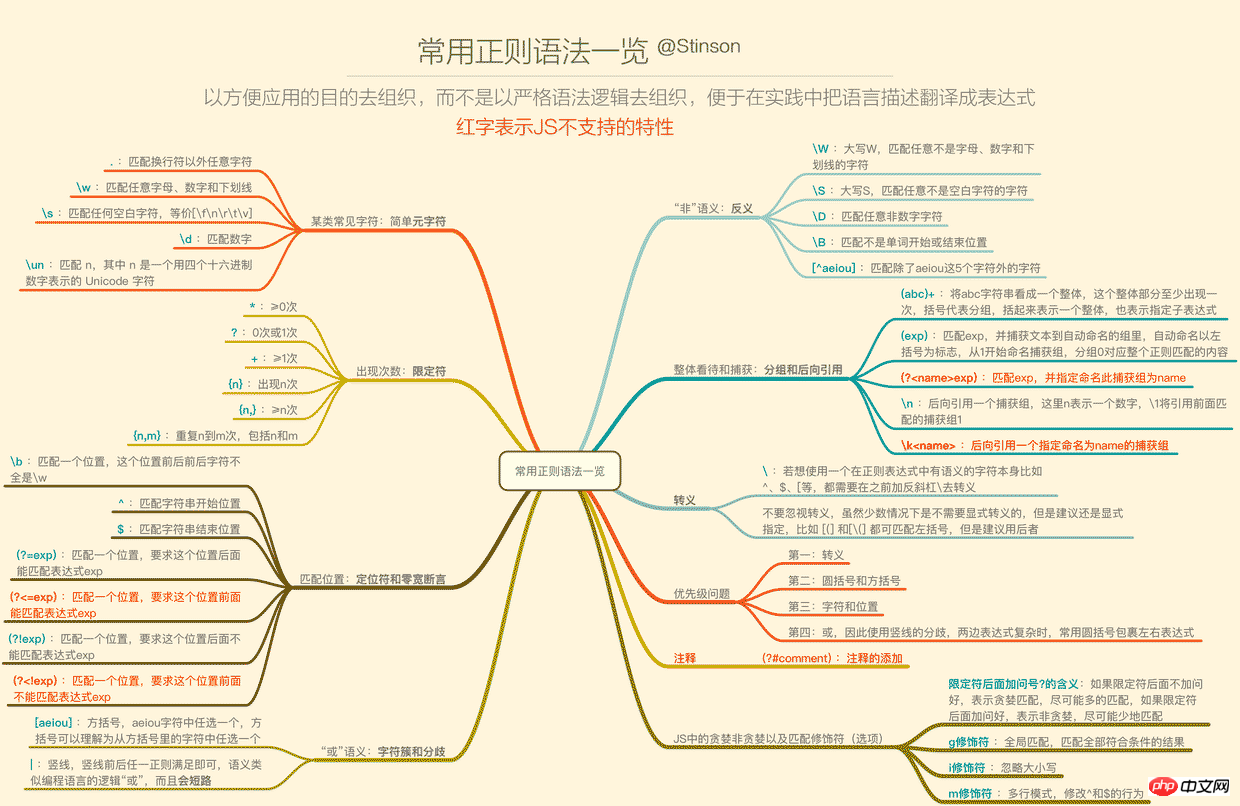
1. 要用某类常见字符——简单元字符
为什么这里要加简单2个字,因为在正则中,\d、\w这样的叫元字符,而{n,m}、(?!exp)这样的也叫元字符,所以元字符是在正则中有特定意义的标识,而这一小节讲的是简单的一些元字符。
.匹配除了换行符以外的任意字符,也即是[^\n],如果要包含任意字符,可使用(.|\n)
\w匹配任意字母、数字或者下划线,等价于[a-zA-Z0-9_],在deerchao的文中还指出可匹配汉字,但是\w在JS中是不能匹配汉字的
\s匹配任意空白符,包含换页符\f、换行符\n、回车符\r、水平制表符\t、垂直制表符\v
\d匹配数字
\un匹配n,这里的n是一个有4个十六进制数字表示的Unicode字符,比如\u597d表示中文字符“好”,那么超过\uffff编号的字符怎么表示呢?ES6的u修饰符会帮你。
2. 要表示出现次数(重复)——限定符
a*表示字符a连续出现次数 >= 0 次
a+表示字符a连续出现次数 >= 1 次
a? bedeutet, dass das Zeichen a 0 oder 1 Mal vorkommt
a{5} bedeutet, dass das Zeichen a 5 Mal hintereinander vorkommt
a{5,} stellt die Anzahl der aufeinanderfolgenden Vorkommen des Zeichens a >= 5 Mal dar.
a{5,10} stellt die Anzahl der aufeinanderfolgenden Vorkommen des Zeichens dar a von 5 bis 10 Mal, einschließlich 5 und 10
3. Passende Position – Locator und Nullbreitenbehauptung
Die Ausdrücke, die einer bestimmten Position entsprechen, sind alle Null- Breite, also Es besteht hauptsächlich aus zwei Teilen: Einer ist der Locator, der einer bestimmten Position entspricht, und der andere ist die Behauptung mit der Breite Null, die einer Position entspricht, die eine bestimmte Anforderung erfüllen muss.
Locators werden üblicherweise wie folgt verwendet:
b entspricht der Wortgrenzenposition. Die genaue Beschreibung lautet, dass sie mit einer Position übereinstimmt, die zuvor nicht durch w beschrieben werden kann und danach Zeichen, also kann so etwas wie u597dbabc mit „gutes ABC“ übereinstimmen.
^ entspricht der Startposition der Zeichenfolge, also Position 0. Wenn die Multiline-Eigenschaft des RegExp-Objekts festgelegt ist, stimmt ^ auch mit der Position nach „n“ oder „r“ überein.
$ entspricht der Endposition der Zeichenfolge. Wenn die Multiline-Eigenschaft des RegExp-Objekts festgelegt ist, entspricht $ auch der Position vor „n“ oder „r“
null Es gibt zwei breite Aussagen (unterstützt von JS):
(?=exp) entspricht einer Position, die mit dem Ausdruck übereinstimmen kann exp. Beachten Sie, dass dieser Ausdruck nur mit einer Position übereinstimmt, aber die Dinge auf der rechten Seite nicht in das Ergebnis eingefügt werden, wenn Sie beispielsweise read(?=ing) verwenden. um mit „reading“ übereinzustimmen, ist das Ergebnis „read“ und „ing“ ist
(?!exp), was nicht im Ergebnis enthalten ist, eine Position entspricht und die rechte Seite dieser Position kann nicht mit dem Ausdruck exp übereinstimmen
4 Möchten Sie die Bedeutung von „oder“ ausdrücken – Zeichencluster und Unterschiede
Wir drücken oft die Bedeutung aus Für „oder“ reicht beispielsweise jedes dieser Zeichen aus, und ein weiteres Beispiel ist die Übereinstimmung von 5 Zahlen oder 5 beliebigen Buchstaben usw. je nach Bedarf. Der Zeichencluster
kann verwendet werden, um eine „oder“-Semantik auf Zeichenebene auszudrücken, die jedes der Zeichen in eckigen Klammern darstellt:
[abc] steht für a , b Jedes der drei Zeichen, c, wenn die Buchstaben oder Zahlen aufeinander folgen, kann es durch - dargestellt werden, [b-f] steht für eines der Zeichen von b bis f
[(ab)(cd)] wird nicht verwendet, um die Zeichenfolge „ab“ oder „cd“ zu finden, sondern um eines der sechs Zeichen a, b, c, d, (,) zu finden, d. h. wenn Sie Wenn Sie die Anforderung „Übereinstimmung mit der Zeichenfolge ab oder cd“ ausdrücken möchten, können Sie dies nicht tun. Sie müssen ab|cd so schreiben. Aber hier müssen Sie die Klammern selbst logischerweise mit Backslashes maskieren. In eckigen Klammern werden die Klammern jedoch wie normale Zeichen behandelt. Trotzdem wird empfohlen,
- ab|cd abgeglichen wird stimmt mit der Zeichenfolge „ab“ oder „cd“ überein
- wird kurzgeschlossen. Erinnern Sie sich an den Kurzschluss des logischen ODER in der
- W, D, S, B. Die durch Großbuchstaben dargestellten Metazeichen sind die Antonyme des übereinstimmenden Inhalts, der den Kleinbuchstaben entspricht. Diese Metazeichen entsprechen „Zeichen außer Buchstaben, Zahlen, und Unterstriche“, „nicht numerische Zeichen“ und „nicht Leerzeichen“ in der Reihenfolge. „Zeichen“, „Nicht-Wort-Grenzposition“
- [^aeiou] steht für beliebig Zeichen außer a, e, i, o, u, die in eckigen Klammern stehen und am Anfang erscheinen. Das ^ an der Position bedeutet Ausschluss. Wenn ^ nicht am Anfang in eckigen Klammern steht, stellt es nur das ^-Zeichen selbst dar
Rückverweis
Tatsächlich haben Sie oben an einigen Stellen Klammern gesehen werden zur Gruppierung verwendet. Was in Klammern steht, ist eine Gruppe.上面讲的大部分是针对字符级别的,比如重复字母 “A” 5次,可以用A{5}来表示,但是如果想要字符串“ABC”重复5次呢?这个时候就需要用到括号。
括号的第一个作用,将括起来的分组当做一个整体看待,所以你可以像对待字符重复一样在一个分组后面加限定符,比如(ABC){5}。
分组匹配到的内容也就是这个分组捕获到的内容,从左往右,以左括号为标志,每个分组会自动拥有一个从1开始的编号,编号0的分组对应整个正则表达式,JS不支持捕获组显示命名。
括号的第二个作用,分组捕获到的内容,可以在之后通过\分组编号的形式进行后向引用。比如(ab|cd)123\1可以匹配“ab123ab”或者“cd123cd”,但是不能匹配“ab123cd”或“cd123ab”,这里有一对括号,也是第一对括号,所以编号为捕获组1,然后在正则中通过\1去引用了捕获组1的捕获的内容,这叫后向引用。
括号的第三个作用,改变优先级,比如abc|de和(abc|d)e表达的完全不是一个意思。
7. 转义
任何在正则表达式中有作用的字符都建议转义,哪怕有些情况下不转义也能正确,比如[]中的圆括号、^符号等。
8. 优先级问题
优先级从高到低是:
转义 \
括号(圆括号和方括号)(), (?:), (?=), []
字符和位置
竖线 |
9. 贪婪和非贪婪
在限定符中,除了{n}确切表示重复几次,其余的都是一个有下限的范围。
在默认的模式(贪婪)下,会尽可能多的匹配内容。比如用ab*去匹配字符串“abbb”,结果是“abbb”。
而通过在限定符后面加问号?可以进行非贪婪匹配,会尽可能少地匹配。用ab*?去匹配“abbb”,结果会是“a”。
不带问号的限定符也称匹配优先量词,带问号的限定符也称忽略匹配优先量词。
10. 修饰符(匹配选项)
其实正则的匹配选项有很多可选,不同的宿主语言环境下可能各有不同,此处就JS的修饰符作一个说明:
加g修饰符:表示全局匹配,模式将被应用到所有字符串,而不是在发现第一个匹配项时停止
加i修饰符:表示不区分大小写
加m修饰符:表示多行模式,会改变^和$的行为,上文已述
三、JS(ES5)中的正则
JS中的正则由引用类型RegExp表示,下面主要就RegExp类型的创建、两个主要方法和构造函数属性来展开,然后会提及String类型上的模式匹配,最后会简单罗列JS中正则的一些局限。
1. 创建正则表达式
一种是用字面量的方式创建,一种是用构造函数创建,我们始终建议用前者。
//创建一个正则表达式
var exp = /pattern/flags;
//比如
var pattern=/\b[aeiou][a-z]+\b/gi;
//等价下面的构造函数创建
var pattern=new RegExp("\\b[aeiou][a-z]+\\b","gi");
其中pattern可以是任意的正则表达式,flags部分是修饰符,在上文中已经阐述过了,有 g、i、m 这3个(ES5中)。
现在说一下为什么不要用构造函数,因为用构造函数创建正则,可能会导致对一些字符的双重转义,在上面的例子中,构造函数中第一个参数必须传入字符串(ES6可以传字面量),所以字符\ 会被转义成\,因此字面量的\b会变成字符串中的\\b,这样很容易出错,贼多的反斜杠。
2. RegExp上用来匹配提取的方法——exec()
var matches=pattern.exec(str); 接受一个参数:源字符串 返回:结果数组,在没有匹配项的情况下返回null
结果数组包含两个额外属性,index表示匹配项在字符串中的位置,input表示源字符串,结果数组matches第一项即matches[0]表示匹配整个正则表达式匹配的字符串,matches[n]表示于模式中第n个捕获组匹配的字符串。
要注意的是,第一,exec()永远只返回一个匹配项(指匹配整个正则的),第二,如果设置了g修饰符,每次调用exec()会在字符串中继续查找新匹配项,不设置g修饰符,对一个字符串每次调用exec()永远只返回第一个匹配项。所以如果要匹配一个字符串中的所有需要匹配的地方,那么可以设置g修饰符,然后通过循环不断调用exec方法。
//匹配所有ing结尾的单词
var str="Reading and Writing";
var pattern=/\b([a-zA-Z]+)ing\b/g;
var matches;
while(matches=pattern.exec(str)){
console.log(matches.index +' '+ matches[0] + ' ' + matches[1]);
}
//循环2次输出
//0 Reading Read
//12 Writing Writ
3. RegExp上用来测试匹配成功与否的方法——test()
var result=pattern.test(str);
接受一个参数:源字符串
返回:找到匹配项,返回true,没找到返回false
4. RegExp构造函数属性
RegExp构造函数包含一些属性,适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
RegExp.input或RegExp["$_"]:最近一次要匹配的字符串
RegExp.lastMatch或RegExp["$&"]:最近一次匹配项
RegExp.lastParen或RegExp["$+"]:最近一次匹配的捕获组
RegExp.leftContext或RegExp["$`"]:input字符串中lastMatch之前的文本
RegExp.rightContext或RegExp["$'"]:input字符串中lastMatch之后的文本
RegExp["$n"]:表示第n个捕获组的内容,n取1-9
5. String类型上的模式匹配方法
上面提到的exec和test都是在RegExp实例上的方法,调用主体是一个正则表达式,而以字符串为主体调用模式匹配也是最为常用的。
5.1 匹配捕获的match方法
在字符串上调用match方法,本质上和在正则上调用exec相同,但是match方法返回的结果数组是没有input和index属性的。
var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; //在String上调用match var matches=str.match(pattern); //等价于在RegExp上调用exec var matches=pattern.exec(str);
5.2 返回索引的search方法
接受的参数和match方法相同,要么是一个正则表达式,要么是一个RegExp对象。
//下面两个控制台输出是一样的,都是5 var str="I am reading."; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches=pattern.exec(str); console.log(matches.index); var pos=str.search(pattern); console.log(pos);
5.3 查找并替换的replace方法
var result=str.replace(RegExp or String, String or Function); 第一个参数(查找):RegExp对象或者是一个字符串(这个字符串就被看做一个平凡的字符串) 第二个参数(替换内容):一个字符串或者是一个函数 返回:替换后的结果字符串,不会改变原来的字符串
第一个参数是字符串
只会替换第一个子字符串
第一个参数是正则
指定g修饰符,则会替换所有匹配正则的地方,否则只替换第一处
第二个参数是字符串
可以使用一些特殊的字符序列,将正则表达式操作的值插进入,这是很常用的。
$n:匹配第n个捕获组的内容,n取0-9
$nn:匹配第nn个捕获组内容,nn取01-99
$`:匹配子字符串之后的字符串
$':匹配子字符串之前的字符串
$&:匹配整个模式得字符串
$$:表示$符号本身
第二个参数是一个函数
在只有一个匹配项的情况下,会传递3个参数给这个函数:模式的匹配项、匹配项在字符串中的位置、原始字符串
在有多个捕获组的情况下,传递的参数是模式匹配项、第一个捕获组、第二个、第三个...最后两个参数是模式的匹配项在字符串位置、原始字符串
这个函数要返回一个字符串,表示要替换掉的匹配项
5.4 分隔字符串的split
基于指定的分隔符将一个字符串分割成多个子字符串,将结果放入一个数组,接受的第一个参数可以是RegExp对象或者是一个字符串(不会被转为正则),第二个参数可选指定数组大小,确保数组不会超过既定大小。
6 JS(ES5)中正则的局限
JS(ES5)中不支持以下正则特性(在一览图中也可以看到):
匹配字符串开始和结尾的\A和\Z锚 向后查找(所以不支持零宽度后发断言) 并集和交集类 原子组 Unicode支持(\uFFFF之后的) 命名的捕获组 单行和无间隔模式 条件匹配 注释
四、ES6对正则的主要加强
ES6对正则做了一些加强,这边仅仅简单罗列以下主要的3点,具体可以去看ES6
1. 构造函数可以传正则字面量了
ES5中构造函数是不能接受字面量的正则的,所以会有双重转义,但是ES6是支持的,即便如此,还是建议用字面量创建,简洁高效。
2. u修饰符
加了u修饰符,会正确处理大于\uFFFF的Unicode,意味着4个字节的Unicode字符也可以被支持了。
// \uD83D\uDC2A是一个4字节的UTF-16编码,代表一个字符
/^\uD83D/u.test('\uD83D\uDC2A')
// false,加了u可以正确处理
/^\uD83D/.test('\uD83D\uDC2A')
// true,不加u,当做两个unicode字符处理
加了u修饰符,会改变一些正则的行为:
.原本只能匹配不大于\uFFFF的字符,加了u修饰符可以匹配任何Unicode字符
Unicode字符新表示法\u{码点}必须在加了u修饰符后才是有效的
使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符
使一些反义元字符对于大于\uFFFF的字符也生效
3. y修饰符
y修饰符的作用与g修饰符类似,也是全局匹配,开始从位置0开始,后一次匹配都从上一次匹配成功的下一个位置开始。
不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始。
所以/a/y去匹配"ba"会匹配失败,因为y修饰符要求,在剩余位置第一个位置(这里是位置0)开始就要匹配。
ES6对正则的加强,可以看这篇
五、应用正则的实践思路
应用正则,一般是要先想到正则(废话),只要看到和“找”相关的需求并且这个源是可以被字符串化的,就可以想到用正则试试。
一般在应用正则有两类情况,一是验证类问题,另一类是搜索、提取、替换类问题。验证,最常见的如表单验证;搜索,以某些设定的命令加关键词去搜索;提取,从某段文字中提取什么,或者从某个JSON对象中提取什么(因为JSON对象可以字符串化啊);替换,模板引擎中用到。
1. 验证类问题
验证类问题是我们最常遇到的,这个时候其实源字符串长什么样我们是不知道,鬼知道萌萌哒的用户会做出什么邪恶的事情来,推荐的方式是这样的:
首先用白话描述清楚你要怎样的字符串,描述好了之后,就开脑洞地想用户可能输入什么奇怪的东西,就是自己举例,拿一张纸可举一大堆的,有接受的和不接受的(这个是你知道的),这个过程中可能你会去修改之前的描述;
把你的描述拆解开来,翻译成正则表达式;
测试你的正则表达式对你之前举的例子的判断是不是和你预期一致,这里就推荐用在线的JS正则测试去做,不要自己去一遍遍写了。
2. 搜索、提取、替换类问题
这类问题,一般我们是知道源文本的格式或者大致内容的,所以在解决这类问题时一般已经会有一些测试的源数据,我们要从这些源数据中提取出什么、或者替换什么。
找到这些手上的源数据中你需要的部分;
观察这些部分的特征,这些部分本身的特征以及这些部分周围的特征,比如这部分前一个符号一定是一个逗号,后一个符号一定是一个冒号,总之就是找规律;
考察你找的特征,首先能不能确切地标识出你要的部分,不会少也不会多,然后考虑下以后的源数据也是如此么,以后会不会这些特征就没有了;
组织你对要找的这部分的描述,描述清楚经过你考察的特征;
翻译成正则表达式;
测试。
Endlich habe ich mehr als 10.000 Wörter mit Erklärungen zur JS-Regelmäßigkeit geschrieben. Nachdem ich es geschrieben habe, habe ich festgestellt, dass meine Kenntnisse in Regelmäßigkeit einen Schritt nach vorne gemacht haben, daher empfehle ich Ihnen, dies regelmäßig zu tun Es ist sehr nützlich, und die Bereitschaft, es zu teilen, ist für mich und andere von großem Nutzen. Vielen Dank an alle, die es lesen können.
Ich glaube, dass Sie die Methode beherrschen, nachdem Sie den Fall in diesem Artikel gelesen haben. Weitere spannende Informationen finden Sie in anderen verwandten Artikeln auf der chinesischen PHP-Website!
Empfohlene Lektüre:
Entspricht der Bank Kartennummer, die vom Benutzer-Luhn-Algorithmus eingegeben wurde
Das obige ist der detaillierte Inhalt vonAnalysieren Sie die Prinzipien und die Syntax von JS-Regex. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse