
Heim >Backend-Entwicklung >PHP-Tutorial >3 Möglichkeiten zur Implementierung der Datenerfassung in PHP
3 Möglichkeiten zur Implementierung der Datenerfassung in PHP

- 小云云Original
- 2018-03-27 11:56:451687Durchsuche
Was ist Sammlung? Dabei geht es darum, mithilfe von PHP-Programmen Informationen von anderen Websites in unsere eigene Datenbank und Website zu erfassen. In diesem Artikel werden hauptsächlich drei Methoden zur Datenerfassung in PHP vorgestellt, in der Hoffnung, allen zu helfen.
PHP-Produktions- und Erfassungstechnologie:
Vom unteren Socket bis zur Dateioperationsfunktion auf hoher Ebene gibt es insgesamt drei Methoden, um die Erfassung zu erreichen.
1. Verwenden Sie die Socket-Technologie zum Sammeln:
Socket-Sammlung ist die unterste Ebene. Sie stellt lediglich eine lange Verbindung her, und dann müssen wir die HTTP-Protokollzeichenfolge selbst erstellen, um die Anfrage zu senden.
Wenn Sie beispielsweise den Inhalt dieser Seite erhalten möchten, verwenden Sie http://tv.youku.com/?spm=a2hww.20023042.topNav.5~1~3!2~A Socket wie folgt schreiben:
<?php
//连接,$error错误编号,$errstr错误的字符串,30s是连接超时时间
$fp=fsockopen("www.youku.com",80,$errno,$errstr,30);
if(!$fp) die("连接失败".$errstr);
//构造http协议字符串,因为socket编程是最底层的,它还没有使用http协议
$http="GET /?spm=a2hww.20023042.topNav.5~1~3!2~A HTTP/1.1\r\n"; // \r\n表示前面的是一个命令
$http.="Host:www.youku.com\r\n"; //请求的主机
$http.="Connection:close\r\n\r\n"; // 连接关闭,最后一行要两个\r\n
//发送这个字符串到服务器
fwrite($fp,$http,strlen($http));
//接收服务器返回的数据
$data='';
while (!feof($fp)) {
$data.=fread($fp,4096); //fread读取返回的数据,一次读取4096字节
}
//关闭连接
fclose($fp);
var_dump($data);
?>Das gedruckte Ergebnis sieht wie folgt aus, einschließlich der zurückgegebenen Header-Informationen und des Quellcodes der Seite:

2. Verwenden Sie curl_a eine Reihe von Funktionen
curl kapselt das HTTP-Protokoll in viele Funktionen. Sie können die entsprechenden Parameter direkt übergeben , was die Schwierigkeit beim Schreiben von HTTP-Protokollzeichenfolgen verringert.
Voraussetzung: Die Curl-Erweiterung muss in php.ini aktiviert sein.
//生成一个curl对象 $curl=curl_init(); //设置URL和相应的选项 curl_setopt($curl, CURLOPT_URL, "http://www.youku.com"); curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以字符串返回,而不是直接输出。 //执行curl操作 $data=curl_exec($curl); var_dump($data);
Das gedruckte Ergebnis ist wie folgt, einschließlich nur des Quellcodes der Seite: 
3. File_get_contents (oberste Ebene) direkt verwenden
Voraussetzung: Legen Sie die URL-Adresse fest, die das Öffnen eines Netzwerks in php.ini ermöglicht.

//使用file_get_contents()
$data=file_get_contents("http://www.youku.com");
var_dump($data);
Auswahl von 3 Methoden
Die oben genannten drei Methoden werden hauptsächlich für die Kommunikation zwischen Netzwerken verwendet. Unter diesen werden die beiden letzteren häufiger verwendet: Wenn Sie große Datenmengen stapelweise erfassen möchten, verwenden Sie die zweite [CURL], die eine gute Leistung und Stabilität bietet .
Verwenden Sie die dritte Methode, wenn Sie gelegentlich, aber nicht häufig, ein paar Anfragen senden.
Erweiterung: Wie kann man das Anti-Leeching von Bildern durchbrechen?
Zum Beispiel sind die Bilder auf der 7060-Website vor Hotlinking geschützt: Die Bilder sind auf seiner Website zu sehen, aber außerhalb der Website nicht zugänglich.
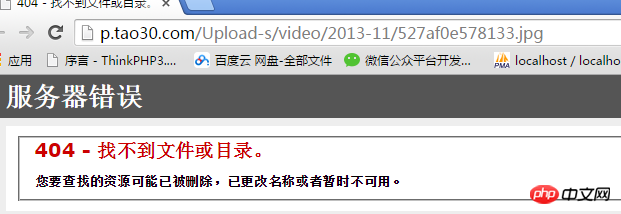
Prinzip: Im HTTP-Protokoll gibt es ein Referrerelement, das die Quelladresse der Anfrage darstellt stellt fest, ob diese Anfrage nicht von dieser Website stammt, wird sie herausgefiltert:
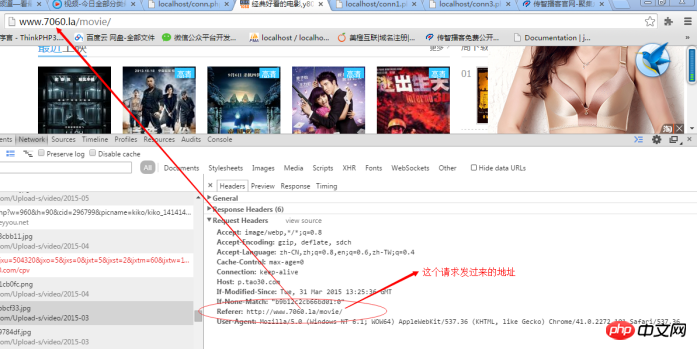
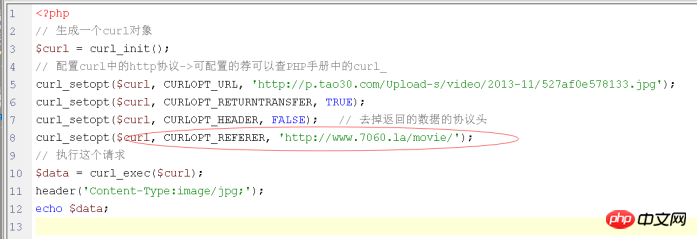
Lösung: Simulieren Sie es selbst beim Senden von HTTP Nur Referrer:
Erweiterung: Bei einigen Datenerfassungen müssen Sie sich zuerst anmelden. Sie können die Simulation verwenden Testsimulation zum Anmelden. Sammlung unter Status:
a. Nach der Anmeldung wird im COOKIE des Browsers SESSIONID
angezeigt .b. 发PHP发HTTP协议时,把浏览器中的SESSIONID放到PHP的HTTP协议请求里,这样就在以登录的状态发请求。
总结:所有客户端发过来的数据都可以被模拟,所以服务器上的程序必须要必要的地方过滤客户端的数据。
什么时候用以上东西?接口开发时、采集时。
二、数据采集
例如我要采集这个url里的所有美国电影的信息,
http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html
则先要知道电影所在的节点的结构,我们使用firebug查看。
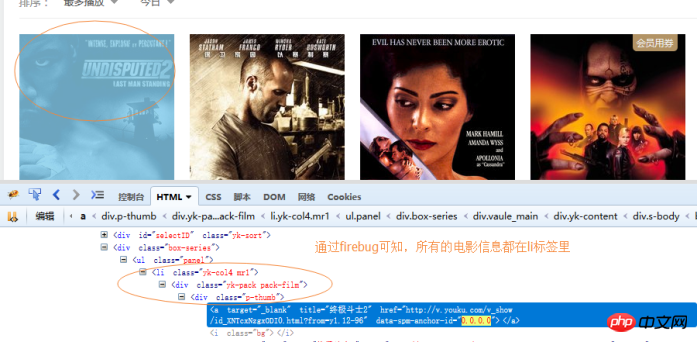
然后开始写代码:完整代码如下
/**
* 发一个GET请求获取数据
*/
function get($url)
{
global $curl;
// 配置curl中的http协议->可配置的荐可以查PHP手册中的curl_
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($curl, CURLOPT_HEADER, FALSE);
// 执行这个请求
return curl_exec($curl);
}
// 生成一个curl对象
$curl = curl_init();
$url='http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html';
$data=get($url);
// 匹配电影所在位置
$list_preg = '/<li class="yk-col4 mr1">.+<\/li>/Us';
// 匹配img标签上的src和alt
$img_preg = '/<img class="quic" _src="(.*)" src="(.*)" alt="(.*)" \/>/U';
//匹配电影的url
$video_preg='/<a href="(.*)" title="(.*)" target="(.*)"><\/a>/U';
//把所有的li存到$list里,$list是个二维数组
preg_match_all($list_preg,$data,$list);
//var_dump($list);
foreach ($list[0] as $k => $v) { //这里$v就是每一个li标签
/* 获取图片及电影名称
preg_match($img_preg,$v,$img); //把匹配到的图片的信息存到$img里
var_dump($img);
*/
/*获取电影地址
preg_match($video_preg,$v,$video); //把匹配到的电影的信息存到$video里
var_dump($video);
*/
preg_match($img_preg,$v,$img);
preg_match($video_preg,$v,$video);
echo $img[0].'<a href="'.$video[1].'">'.$video[2].'</a>';
}测试:
打印$list;

打印$img

打印$video

最终效果:
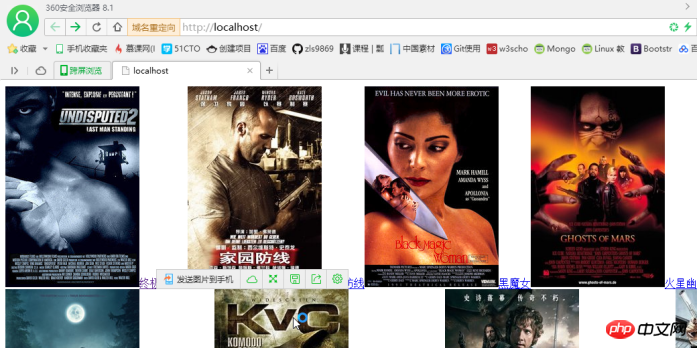
如果需要把图片拷贝到硬盘上,则在foreach循环里加上以下代码:
$imgData = get($img[1]);
// 把图片文件写到硬盘上【下载】
// 因为操作系统是GBK的,所以要把UTF8转成GBK
is_dir('./youkuimg/') ? '': mkdir('./youkuimg/');
file_put_contents('./youkuimg/'.mb_convert_encoding($img[3], 'gbk', 'utf-8').'.jpg', $imgData);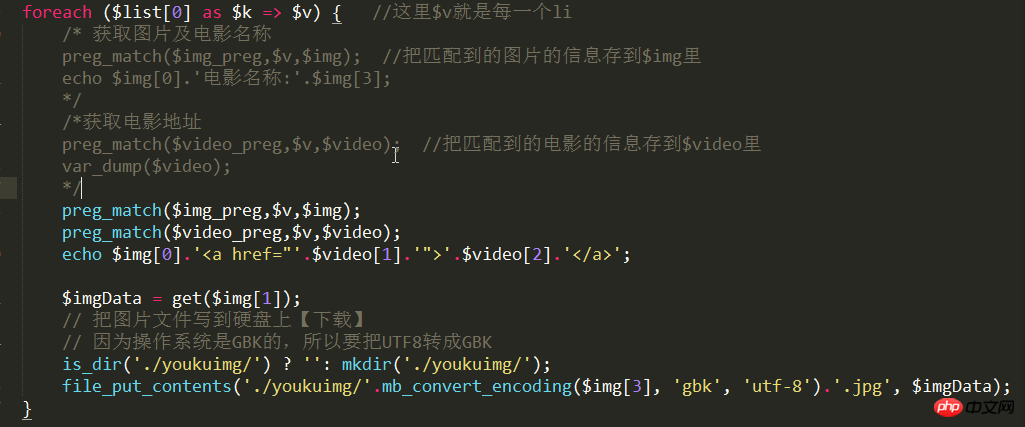
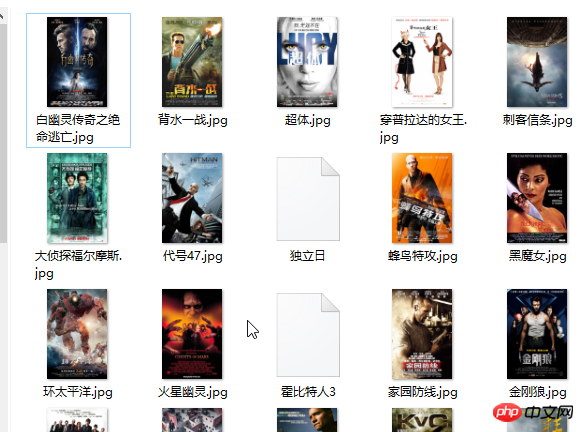
效果如下:在当前目录下的youkuimg目录下就会有下载好的图片。
my github: https://github.com/lensh
Das obige ist der detaillierte Inhalt von3 Möglichkeiten zur Implementierung der Datenerfassung in PHP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)