
Heim >Backend-Entwicklung >PHP-Tutorial >Entwicklungsfall der Implementierung eines einfachen Crawlers in PHP
Entwicklungsfall der Implementierung eines einfachen Crawlers in PHP

- 小云云Original
- 2018-03-21 11:08:071744Durchsuche
Manchmal durchsuchen wir aufgrund der Arbeit und unserer eigenen Bedürfnisse verschiedene Websites, um die Daten zu erhalten, die wir benötigen. Daher sind Crawler entstanden. Das Folgende ist mein Prozess zur Entwicklung eines einfachen Crawlers und die Probleme, auf die ich gestoßen bin.
Um einen Crawler zu entwickeln, müssen Sie zunächst wissen, wofür Ihr Crawler verwendet werden soll. Ich möchte damit Artikel mit bestimmten Schlüsselwörtern auf verschiedenen Websites finden und deren Links erhalten, damit ich sie schnell lesen kann.
Je nach persönlichen Gewohnheiten muss ich zunächst eine Schnittstelle schreiben und meine Ideen klären.
1. Besuchen Sie verschiedene Websites. Dann brauchen wir ein URL-Eingabefeld.
2. Finden Sie Artikel mit bestimmten Schlüsselwörtern. Dann benötigen wir ein Eingabefeld für den Artikeltitel.
3. Holen Sie sich den Artikellink. Dann benötigen wir einen Anzeigecontainer für Suchergebnisse.
<p class="jumbotron" id="mainJumbotron">
<p class="panel panel-default">
<p class="panel-heading">文章URL抓取</p>
<p class="panel-body">
<p class="form-group">
<label for="article_title">文章标题</label>
<input type="text" class="form-control" id="article_title" placeholder="文章标题">
</p>
<p class="form-group">
<label for="website_url">网站URL</label>
<input type="text" class="form-control" id="website_url" placeholder="网站URL">
</p>
<button type="submit" class="btn btn-default">抓取</button>
</p>
</p>
<p class="panel panel-default">
<p class="panel-heading">文章URL</p>
<p class="panel-body">
<h3></h3>
</p>
</p>
</p>Fügen Sie den Code direkt hinzu und fügen Sie dann einige eigene Stilanpassungen hinzu, und die Benutzeroberfläche ist fertig:
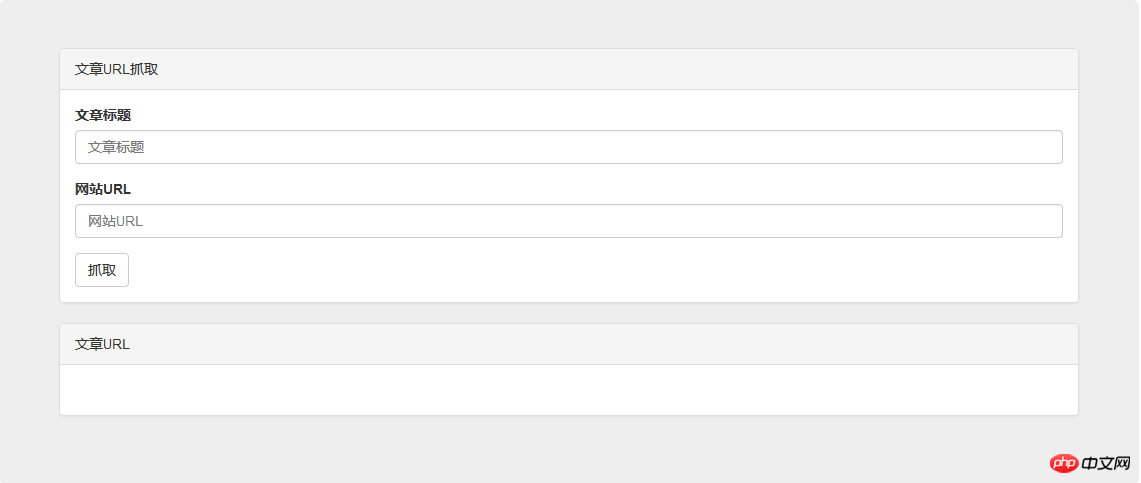
Dann besteht der nächste Schritt darin, die Funktion zu implementieren. Der erste Schritt besteht darin, den HTML-Code der Website zu erhalten um eins. Hier verwende ich Curl, um den HTML-Code zu erhalten:
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}Obwohl Sie den HTML-Code erhalten, werden Sie ihn bald erhalten Auf ein Problem stoßen, nämlich das Codierungsproblem. Dies kann dazu führen, dass Ihr nächster Schritt des Abgleichs vergeblich ist. Hier konvertieren wir den erhaltenen HTML-Inhalt einheitlich in die UTF8-Codierung:
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
得到网站的html,要获取文章的url,那么下一步就是要匹配该网页下的所有a标签,需要用到正则表达式,经过多次测试,最终得到一个比较靠谱的正则表达式,不管a标签下结构多复杂,只要是a标签的都不放过:(最关键的一步)
$pattern = '|<a[^>]*>(.*)</a>|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,它大概是这样的一个多维素组:
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "完整的a标签"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "与上面下标相对应的a标签中的内容"
}
}只要能得到这个数据,其他就完全可以操作啦,你可以遍历这个素组,找到你想要a标签,然后获取a标签相应的属性,想怎么操作就怎么操作啦,下面推荐一个类,让你更方便操作a标签:
$dom = new DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,把数据玩出新花样。
得到并匹配得出你想要的结果,下一步当然就是传回前端将他们显示出来啦,把接口写好,然后前端用js获取数据,用jquery动态添加内容显示出来:
var website_url = '你的接口地址';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<p><p>暂无该文章链接</p></p>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<p class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</p>';
}
}
}
$('#article_url').html(string);
});上最终效果图:
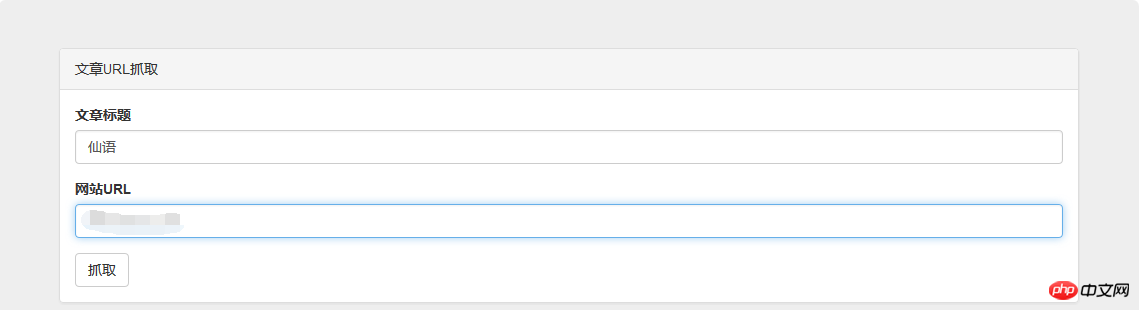

Das obige ist der detaillierte Inhalt vonEntwicklungsfall der Implementierung eines einfachen Crawlers in PHP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)