
Heim >Backend-Entwicklung >PHP-Tutorial >So verwenden Sie den PHPSpider-Crawler
So verwenden Sie den PHPSpider-Crawler

- 小云云Original
- 2018-03-20 10:38:297045Durchsuche
In diesem Artikel erfahren Sie hauptsächlich, wie Sie den PHP-Crawler verwenden. Obwohl die Verwendung des Python-Crawlers sehr praktisch ist, ist die Verwendung des Framework-Crawlers tatsächlich viel effizienter.
1, schauen Sie sich zuerst die Struktur von PHPSpider an
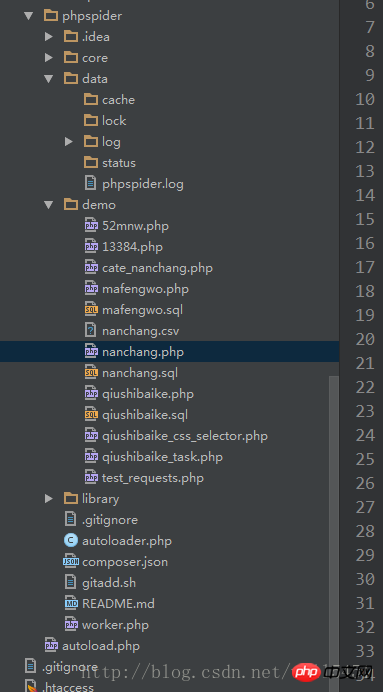
2, zum Beispiel: Ich habe zum Beispiel eine Kategorie von Nanchang gecrawlt News Network
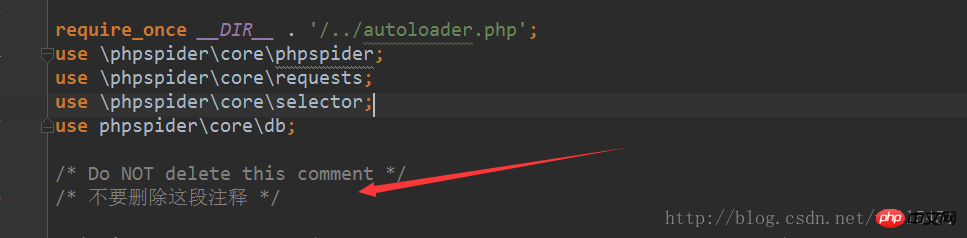
Dieser Kommentar muss hinzugefügt werden, sonst wird ein Fehler gemeldet. Es gibt viele Methoden im Quellcode.
3, dann Crawler konfigurieren:
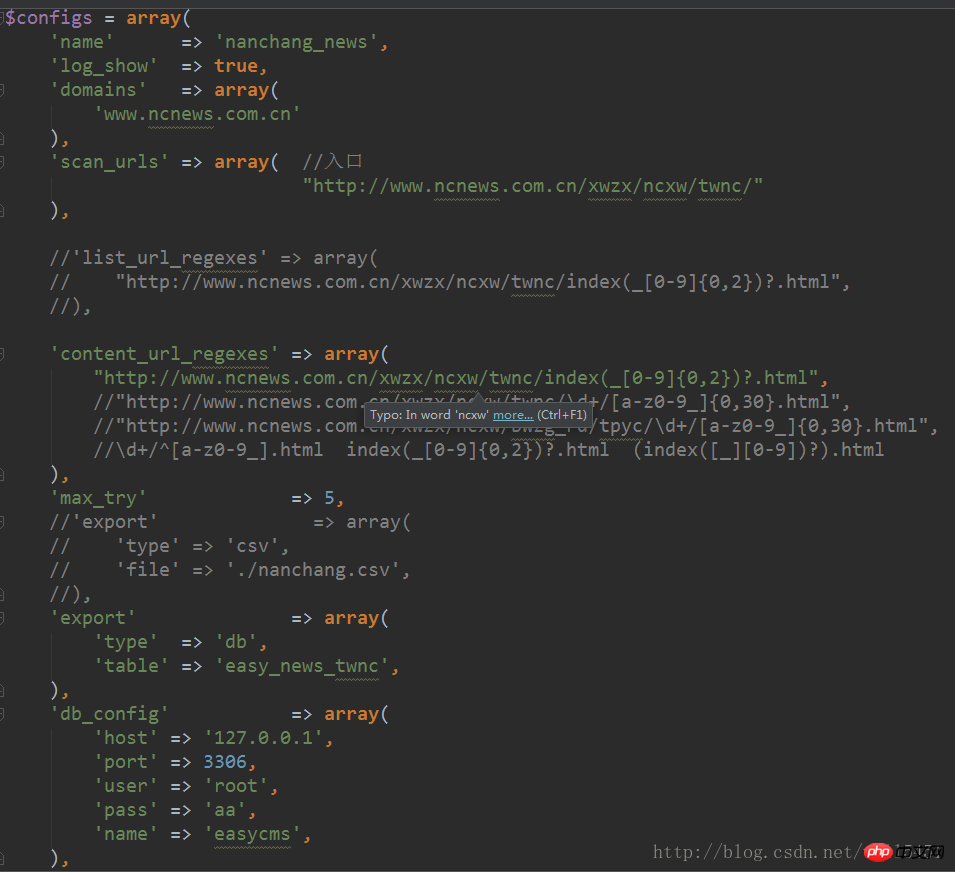

4, dann die Konfigurationsdatei einfügen Die Framework-Klassendatei und instanziieren:
Die on_scan_page hier ist die Eintrags-URL für das Crawling. Diese URLs entsprechen den von mir konfigurierten regulären content_url_regxes-Regeln, sodass im nachfolgenden Crawling-Prozess die Daten dieser Seiten gecrawlt werden
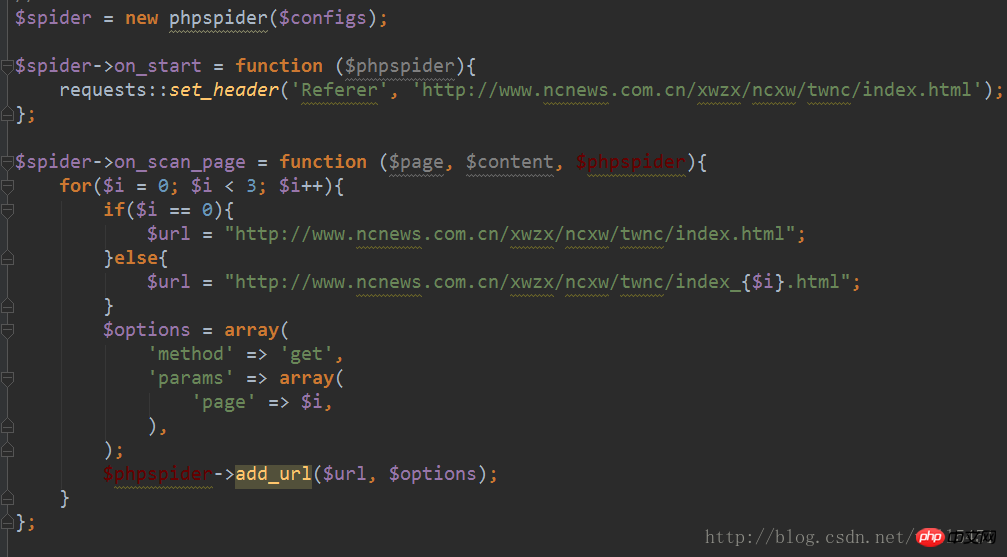
5, Rückrufverarbeitung für das übereinstimmende Feld durchführen:
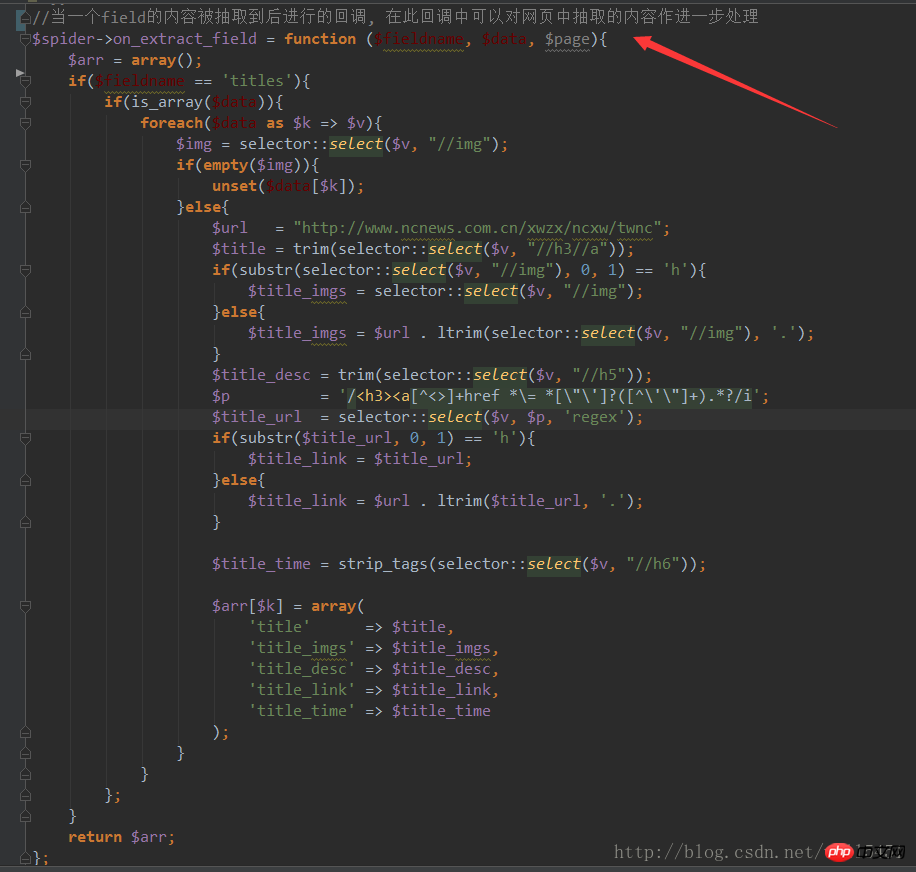
6, Crawling-Datenspeicherung durchführen Verarbeitung, ausführen
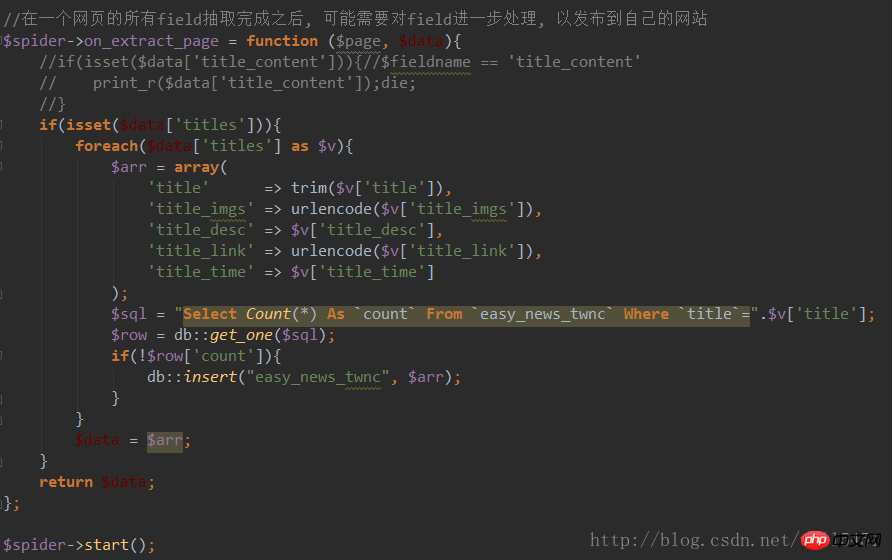
Das Obige ist nur ein einfaches Beispiel. Sie können auch Multiprozess-Crawling, Proxy-Crawling und viel Spaß durchführen.
Verwandte Empfehlungen:
Detaillierte Erklärung von CURL für den PHP-Webcrawler
So implementieren Sie den Crawler in PHP
Detaillierte Erklärung des NodeJS-Crawlers
Das obige ist der detaillierte Inhalt vonSo verwenden Sie den PHPSpider-Crawler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)