
Heim >Backend-Entwicklung >PHP-Tutorial >Detaillierte Erläuterung von 5 Redis-Datenstrukturen
Detaillierte Erläuterung von 5 Redis-Datenstrukturen

- 小云云Original
- 2018-03-12 15:17:485777Durchsuche
In diesem Artikel teilen wir Ihnen hauptsächlich detaillierte Erklärungen zu 5 Redis-Datenstrukturen mit. Wir hoffen, dass die Fälle und Codes im Artikel allen helfen können.
2.1.1 Globaler Befehl
1 Alle Schlüssel anzeigen key*
2 Gesamtzahl der Schlüssel dbsize (der Befehl „dbsize“ berechnet nicht die Gesamtzahl Anzahl der Schlüssel) Durchlaufen Sie alle Schlüssel, erhalten Sie jedoch direkt die Gesamtzahl der in Redis integrierten Schlüssel. Die Zeitkomplexität beträgt O (1), während der Befehl „keys“ alle Schlüssel durchläuft und die Zeitkomplexität O (n) beträgt Bei einer großen Anzahl von Schlüsseln ist die Verwendung der Zeile in der oben genannten Umgebung verboten)
3 Überprüfen Sie, ob der Schlüssel existiert. Der Schlüssel gibt 1 zurück, wenn er existiert, und 0, wenn er nicht existiert
4 Schlüssel löschen del key Gibt die Anzahl der erfolgreich gelöschten Schlüssel zurück. Wenn sie nicht vorhanden sind, geben Sie 0 zurück
5 Schlüsselablauf Ablaufschlüssel Sekunden Der TTL-Befehl gibt die verbleibende Ablaufzeit -1 zurück Für den Schlüssel ist keine Ablaufzeit festgelegt -2 Der Schlüssel existiert nicht
6 Schlüsseldatentyp Strukturtyp Schlüsselrückgabetyp, existiert nicht und gibt keine zurück
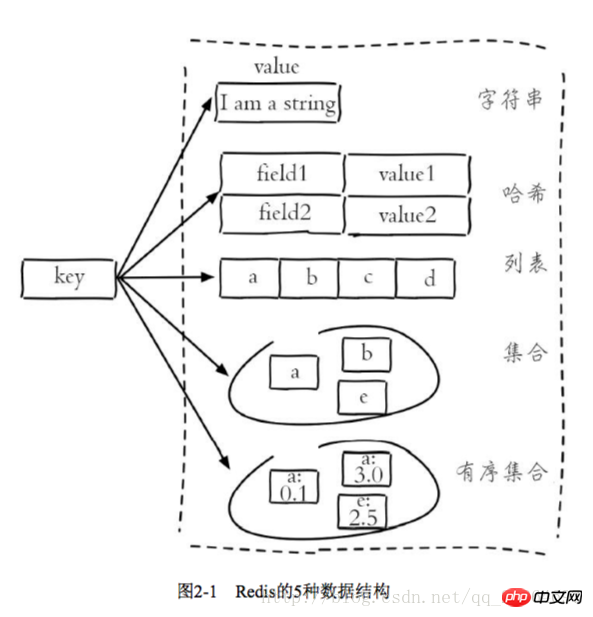
2.1.2 Datenstruktur und interne Codierung
Jede Datenstruktur verfügt über eine eigene zugrunde liegende interne Codierungsimplementierung, und es handelt sich um mehrere Implementierungen, sodass Redis im entsprechenden Szenario die entsprechende interne Codierung auswählt
Jede Datenstruktur verfügt über mehr als zwei interne Kodierungsimplementierungen. Beispielsweise umfasst die Listendatenstruktur die interne Kodierung, Sie können die interne Kodierung über den Objektkodierungsbefehl
Redis‘ Design abfragen zwei Vorteile: Erstens kann es die interne Codierung verbessern, ohne externe Datenstrukturen und Befehle zu beeinträchtigen. Zweitens können mehrere interne Codierungsimplementierungen ihre jeweiligen Vorteile in unterschiedlichen Szenarien entfalten. Ziplist spart beispielsweise Speicher, aber wenn viele Listenelemente vorhanden sind, nimmt die Leistung ab. Zu diesem Zeitpunkt konvertiert Redis die interne Implementierung des Listentyps basierend auf den Konfigurationsoptionen 2.1 in Linkedlist .3 Single-Thread-Architektur
 Redis verwendet eine Single-Threaded-Architektur und I/O-Multi-Road-Wiederverwendungsmodelle, um leistungsstarke Speicherdatenbankdienste zu erreichen
Redis verwendet eine Single-Threaded-Architektur und I/O-Multi-Road-Wiederverwendungsmodelle, um leistungsstarke Speicherdatenbankdienste zu erreichen
1 führend ein einzelnes Thread-Modell
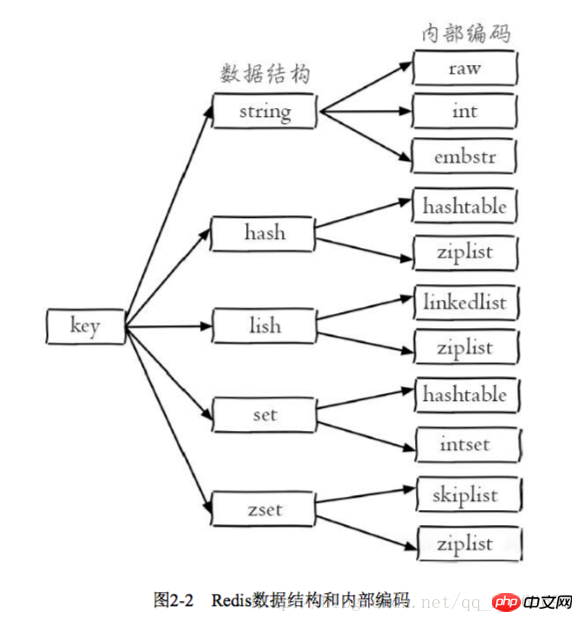
2 Warum kann ein einzelner Thread so schnell laufen
Erstens, reiner Speicherzugriff, Redis legt alle Daten in den Speicher, und die Antwort des Speichers Die Zeit beträgt etwa 100 Nanosekunden, was eine wichtige Grundlage für Redis ist, um einen Zugriff auf 10.000 Ebenen pro Sekunde zu erreichen.
Drei einzelne Threads vermeiden den Verbrauch von Threadwechseln und Race Conditions
Single Thread bringt mehrere Vorteile mit sich: Erstens vereinfacht Single Thread die Implementierung von Datenstrukturen und Algorithmen. Zweitens vermeidet Single-Threading den Verbrauch, der durch Thread-Wechsel und Race-Bedingungen verursacht wird. Es gibt jedoch Anforderungen für die Ausführung jedes Befehls. Wenn die Ausführungszeit eines bestimmten Befehls zu lang ist, führt dies dazu, dass andere Befehle blockiert werden. Redis ist eine Datenbank für schnelle Ausführungsszenarien 🎜> 2.2 String
Der String-Typ von Redis ist die Basis für mehrere andere Typen. Der Wert kann ein String (einfacher oder komplexer JSON, XML) oder eine Zahl (Ganzzahl, Gleitkomma) sein. , Binär (Bilder, Audio, Video), der Maximalwert darf 512 MB nicht überschreiten > 1 Allgemeine Befehle
1 Stellen Sie die Ablaufzeit des zweiten Schlüsselwerts in Millisekunden ein > Anwendungsszenarien: Da Redis ein Single-Threaded-Befehlsverarbeitungsmechanismus: Wenn mehrere Clients gleichzeitig den Setnx-Schlüsselwert ausführen, kann entsprechend den Merkmalen nur ein Client ihn erfolgreich festlegen, was als Implementierungslösung für verteilte Sperren verwendet werden kann
2 Holen Sie sich den Wert get key, wenn er nicht existiert, und geben Sie Null zurück
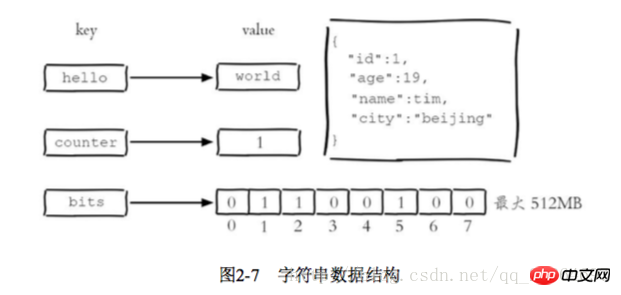 3 Legen Sie den Wert mset key value in Stapeln fest
3 Legen Sie den Wert mset key value in Stapeln fest
4 Holen Sie sich den Wert mget key in Batches 🎜>
Die Schlüssel existieren nicht, entsprechend dem Wert 0 ist das Rückgabeergebnis 1
und derBy (selbst erhöhende angegebene Zahl), derby Die angegebene Zahl subtrahieren), incrbyfloat (Gleitkommazahl erhöhen)
5 Teil der Zeichenfolge abrufen GetRANGE Key Start End
2.2.2 Interne Codierung
Die interne Codierung der Zeichenfolge Es gibt drei Typen: Die lange Ganzzahl EMBSTR von 8 Bytes ist kleiner als eine Zeichenfolge, die 39 Bytes entspricht. Rohdaten Eine Zeichenfolge, die größer als 39 Bytes ist. Redis entscheidet anhand des Typs und der Länge des aktuellen Werts, welche interne Codierungsimplementierung verwendet werden soll
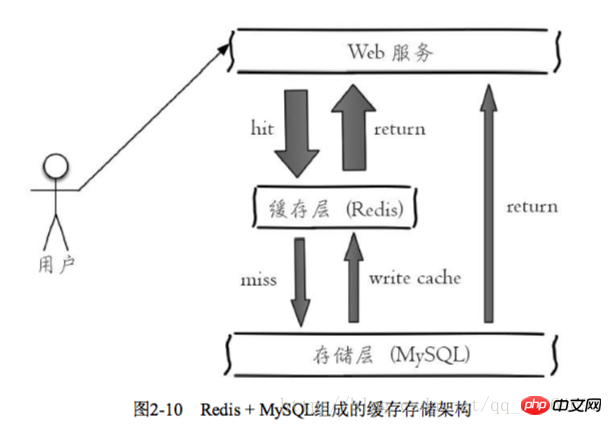
2.2.3 Typische Nutzungsszenarien
. Da Redis über die Funktion verfügt, Parallelität zu unterstützen, kann Caching normalerweise dazu beitragen, das Lesen und Schreiben zu beschleunigen und den Back-End-Druck zu verringern.
: Benennungsmethode für Schlüsselnamen: Firmenname: Objektname: ID: [ Attribut] als Schlüsselname
Pseudocode-Implementierung:
2 zählend
Entwicklungstipps: Anti-Cheating, Zählen nach verschiedenen Dimensionen, die Datenquelle der Daten ist dauerhaft
UserInfo getUserInfo(long id){
userRedisKey="user:info:"+id
value=redis.get(userRedisKey);
UserInfo userInfo;
if(value!=null){
userInfo=deserialize(value)
}else{
userInfo=mysql.get(id)
if(userInfo!=null)
redis.setex(userRedisKey,3600,serizelize(userInfo))
} return userInfo
}
>
long incrVideoCounter(long id){
key="video:playCount:"+id;
return redis.incr(key)
}
4 Geschwindigkeitsbegrenzung
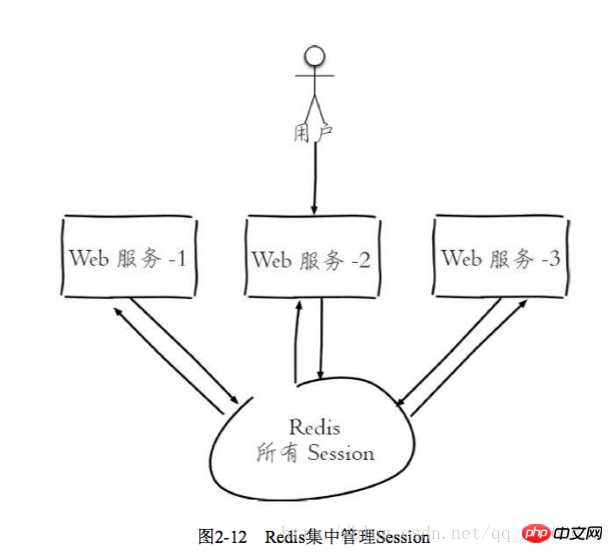 Einige Websites beschränken eine IP-Adresse, auf die nicht innerhalb einer Sekunde zugegriffen werden kann. Sie können auch ähnliche Ideen verwenden. Dies bedeutet, dass der Schlüsselwert selbst eine Schlüssel-Wert-Paarstruktur ist
Einige Websites beschränken eine IP-Adresse, auf die nicht innerhalb einer Sekunde zugegriffen werden kann. Sie können auch ähnliche Ideen verwenden. Dies bedeutet, dass der Schlüsselwert selbst eine Schlüssel-Wert-Paarstruktur ist
2.3.1 Befehl 
phoneNum="13800000000";
key="shortMsg:limit:"+phoneNum;
isExists=redis.set(key,1,"EX 60",NX);
if(isExists !=null ||redis.incr(key)<=5){
通过
}else{
限速
}
6 Bestimmen Sie, ob das Feld existiert. Hexisten-Schlüsselfeld
7 Holen Sie sich alle Feld-Hkeys-Schlüssel
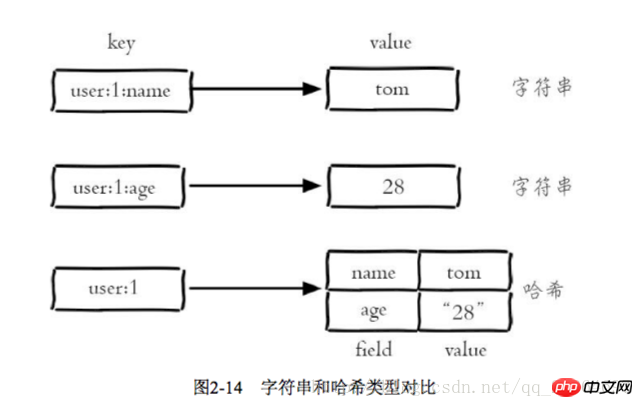
Entwicklungstipps: Wenn Sie sicherstellen möchten, dass Sie alle Feldwerte abrufen, können Sie den Befehl hscan verwenden, um den Hash-Typ schrittweise zu durchlaufen >
2.3.2 Interne Codierung
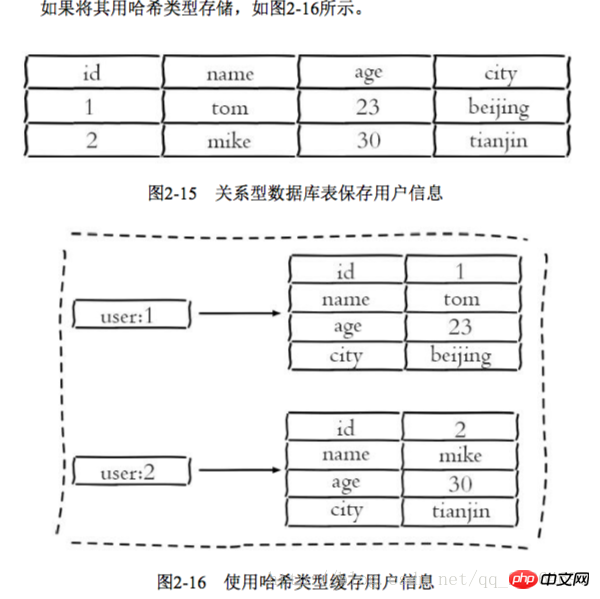
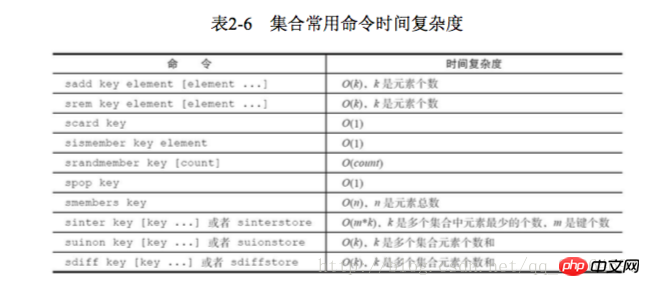
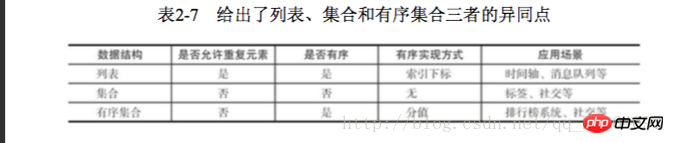
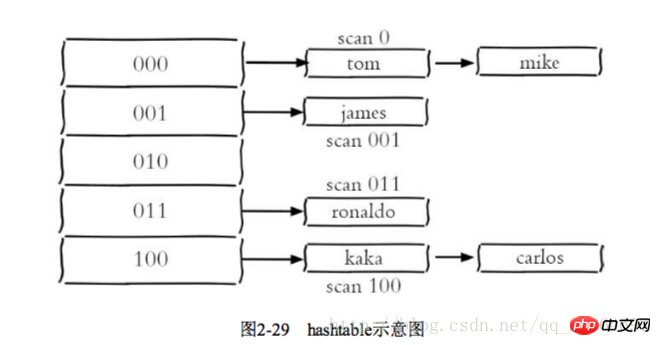
哈希类型和关系型数据库两点不同: 1 哈希类型是稀疏的,而关系型数据库是完全结构化的 2 关系型数据库可以做复杂的查询,而Redis去模拟关系型复杂查询开发困难,维护成本高 三种方法缓存用户信息 1 原声字符串类型:每个属性一个键 优点:简单直观,每个属性都支持更新操作 缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以一般不会在生产环境用 2 序列化字符串类型:将用户信息序列化后用一个键保存 优点:简化编程,如果合理的使用序列化可以提高内存的使用效率 缺点:序列化和反序列化有一定的开销,同时每次更新属性,都需要把数据取出来反序列化,更新后再序列化到Redis中 3 哈希类型:每个用户属性使用一对field-value,但是只用一个键保存 优点:简单直观,如果使用合理,可以减少内存空间的使用 缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多的内存 2.4 列表 列表类型用来存储多个有序的字符串,一个列表最多存储2的32次方-1个元素,列表是一种比较灵活的数据结构,它可以灵活的充当栈和队列的角色,在实际开发上有很多应用场景 列表有两个特点:第一、列表中的元素是有序的,这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表。第二、列表中的元素可以是重复的 2.4.1 命令 1 添加操作 1.1 从右边往左插入元素 rpush key value 1.2 从左往右插入元素 lpush key value 1.3 向某个元素前或者后插入元素 linsert key before|after pivot value 2 查找 1 获取指定范围内的元素列表 lrange key start end Indexindizes haben zwei Eigenschaften: Erstens sind die Indexindizes 0-n-1 von links nach rechts und -1--n von rechts nach links. Zweitens enthält die Endoption von lrange sich selbst, dies ist nicht der Fall Das Gleiche gilt für viele Programmiersprachen, die kein Ende enthalten. 2 Holen Sie sich den Element-Lindex-Schlüsselindex 3 Holen Sie sich die Länge des Listen-LLen-Schlüssels 3 Löschen 1 Öffnen Sie das Element auf der linken Seite der Liste, lpop-Taste 2 Öffnen Sie die rpop-Taste 5 Blockierungsvorgang brpop blpop key timeout 1 Die Liste ist leer: Wenn Timeout = 3, wartet der Client bis zur Rückkehr. Wenn Timeout = 0, blockiert der Client und wartet. Wenn Daten hinzugefügt werden, kehrt der Client sofort zurück 2 Die Liste ist nicht leer: Der Client gibt sofort zurück lpush+brpop=Message Queue(Message Queue) 2.5 Sammlung Anders als Listen sind dort nicht zulässig sind doppelte Elemente und die Elemente in der Menge sind ungeordnet 2.5.1 Befehle 1 Operationen innerhalb der Menge 1.1 Add Elemente Sadd-Schlüsselelement 1.2 Element löschen SREM-Schlüsselelement 1.3 Berechnen Sie die Anzahl der Elemente Narbenschlüssel 1.4 Bestimmen Sie, ob das Element ist im set sismember key element 1.5 Gibt zufällig die angegebene Anzahl von Elementen aus der Sammlung srandmember key zurück 1.6 Entnimmt das Element zufällig dem set spop key 1.7 Smember-Schlüssel für alle Elemente abrufen 2 Operationen zwischen Sätzen 1 Finden Sie den Schnittpunkt-Sinterschlüssel mehrerer Sätze... 2 Anfrage Union mehrerer Sätze Suinon-Schlüssel... Speichern Suionstore-Zielschlüssel Schlüssel > intset (ganzzahlige Menge): Wenn die Elemente in der Menge alle Ganzzahlen sind und die Anzahl der Elemente geringer ist als die Konfiguration von set-max-intset-entries (Standard 512), verwendet Redis intset als interne Implementierung der Menge , wodurch die Speichernutzung reduziert wird Hash-Tabelle) Wenn der Sammlungstyp die Bedingungen von intset nicht erfüllen kann, verwendet Redis Hashtable als interne Implementierung der Sammlung 2.5. 3 Nutzungsszenarien Typische Anwendungsszenarien von Sammlungstypen ist ein Etikett. 1 Fügen Sie dem Benutzer ein Tag hinzu sadd user:1:tags tag1 tag2 2 Fügen Sie dem Tag einen Benutzer hinzu 3 Löschen Sie die Tags unter dem Benutzer srem user:1:tags tag1 tag5 4 Löschen Sie den Benutzer unter dem Tag srem tag1:users user:1 5 Tags berechnen, die für Benutzer von gemeinsamem Interesse sind sinter user:1 tags user:2 tags Entwicklungstipps: sadd=Tagging(tag) spop/srandmember =Zufälliges Element (zufällige Zahlen generieren, z. B. Lotterie) spop/srandmember=Zufälliges Element (zufällige Zahlen generieren, z. B. Lotterie) sadd+sinter=Social Graph (soziale Bedürfnisse) 2.6 Geordneter Satz Ein geordneter Satz besteht darin, dem Satz eine Punktzahl als Grundlage für die Sortierung hinzuzufügen 2.6.1 Befehl 1 In der Sammlung 1Mitglied hinzufügen zadd key score member nx xx ch Gibt die Anzahl der Elemente und Bewertungen der geordneten Menge zurück, die sich nach dieser Operation geändert haben, incr: Erhöhen der Bewertung Geordnete Mengen stellen im Vergleich zu Mengen ein Sortierfeld bereit, produzieren aber auch Unter Berücksichtigung der Kosten beträgt die zeitliche Komplexität von zadd O(log(n)) und die zeitliche Komplexität von sadd beträgt O(1) 2 Berechnen Sie die Anzahl der Mitglieder Scard Key 3 Berechnen Sie die Bewertung eines Mitglieds Zscore Key Member 4 Berechnen Sie die Rangfolge des Mitglieds Zrank Key Member 5 Mitglied löschen zrem key member 6 Erhöhen Sie die Punktzahl des Mitglieds Zincrby Key Inkrement Member 7 Geben Sie die Mitglieder im angegebenen Rangbereich zurück zrange key start end 8 Zurück zu den angegebenen Mitgliedern des Punktebereichs zrangebysore key min max 9 Gibt die Anzahl der Mitglieder im angegebenen Punktebereich zurück zcount key min max 10 Löschen Sie die aufsteigenden Elemente in der angegebenen Rangfolge zremrangebyrank key start end 11 Löschen Sie Mitglieder des angegebenen Bewertungsbereichs zremrangebyscore key min max 2 Operationen zwischen Sätzen 1 Kreuzung Zinter Store Ziel Zifferntaste 2 Union Zunionstore Ziel Zifferntaste 2.6.2 Interne Codierung Dort Es gibt zwei interne Kodierungen für geordnete Satztypen: 🎜> 1 Benutzer-Likes hinzufügen zdd user:ranking:2016_03_15 mike 3 1 Dann Zincrby user:ranking:2016_03_15 mike 1 2 Benutzer-Likes löschen ; zrevrangebyrank user:ranking:2016_03_15 0 9 4 Benutzerinformationen und Benutzerbewertungen anzeigen Diese Funktion kann den Benutzernamen als Schlüssel verwenden Suffix und speichern Sie die Benutzerinformationen in einem Hash-Typ. Für die Bewertung und das Ranking des Benutzers können die beiden Funktionen von zcore und zrank verwendet werden. 2.7.1 Einzelschlüsselverwaltung 1 Schlüssel, Schlüssel umbenennen, neuer Schlüssel 2 gibt zufällig einen Schlüssel zurück, randomkey 3 Schlüsselablauf -1 Schlüssel ist nicht festgelegt Abgelaufene Zeit-2 Schlüssel existiert nicht Schlüsselsekunden ablaufen: Der Schlüssel läuft nach Sekunden Sekunden ab Expire Key itmestamp Der Schlüssel läuft nach dem zweiten Zeitstempel ab. timestamp 5 Redis unterstützt die Ablaufzeit von nicht Interne Elemente der sekundären Datenstruktur. Die Ablaufzeit kann beispielsweise nicht für ein Element dieses Listentyps festgelegt werden. 6 Der Befehl setex wird als Set+Expire-Kombination verwendet atomar, verkürzt aber auch die Zeit der Netzwerkkommunikation 4 Migrationsschlüssel Die Migrationsschlüsselfunktion ist sehr wichtig: Verschieben, Dump +restore und migrate sind unterschiedlich 1 Verschiebung wird für die Datenmigration innerhalb von Redis verwendet 2 dump+restore wird implementiert in verschiedenen Redis Die Funktion der Datenmigration zwischen Instanzen Diese Migration ist in zwei Schritte unterteilt 1. Auf dem Quell-Redis serialisiert der Dump-Befehl den Schlüsselwert im RDB-Format 2 Auf dem Ziel-Redis stellt der Wiederherstellungsbefehl den oben genannten serialisierten Wert wieder her, wobei der TTL-Parameter die Ablaufzeit darstellt 3 migrate-Befehl wird verwendet, um Daten zwischen Redis-Instanzen zu migrieren 2.7.2 Schlüssel durchqueren Redis stellt zwei Befehle zum Durchlaufen aller Schlüssel bereit. Es handelt sich um Schlüssel und scannen 1 Vollständiges Durchlaufen des Schlüsseltastenmusters * Stellt die Übereinstimmung mit einem beliebigen Zeichen dar Stellt die Übereinstimmung mit einem Zeichen dar [] stellt die Übereinstimmung eines Zeichens dar Eine große Menge kann leicht zu Blockierungen führen 2 Progressive Durchquerung Scan kann sein Man geht davon aus, dass nur ein Teil der Schlüssel in einem Wörterbuch durchsucht wird, bis alle Schlüssel im Wörterbuch durchlaufen wurden. ’ bis _ bis _ bis „ Beim Hinzufügen Beim Löschen oder Löschen kann nicht garantiert werden, dass neue Schlüssel zu 2.7.3 Datenbankverwaltung Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung von 5 Redis-Datenstrukturen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
ziplist (komprimierte Liste) Anzahl der Hash-Elemente
UserInfo getUserInfo(long id){
userRedisKey="user:info:"+id;
userInfoMap=redis.hgetAll(userRedisKey);
userInfoMap userInfo;
if(userInfoMap!=null){
userInfo=transferMapToUserInfo(userInfoMap);
}else{
userInfo=mysql.get(id);
redis.hmset(userRedisKey,tranferUserInfoToMap(userInfo));
redis.expire(userRedisKey,3600);
}
return userInfo;
}

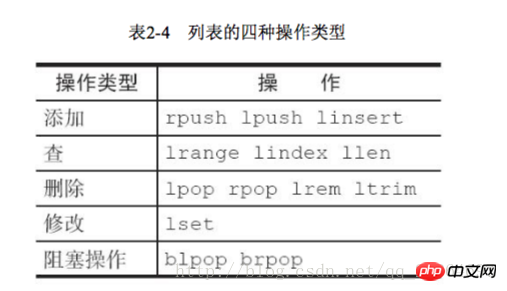
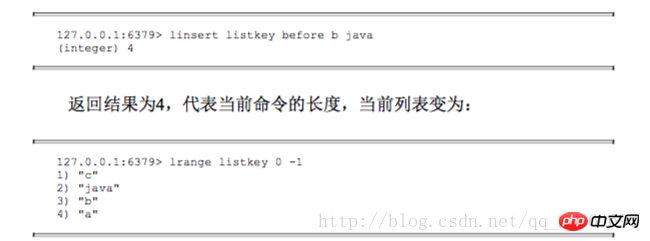
Ändern Sie den angegebenen Index. Zielelement lset key index newValue
3
1 Nachrichtenwarteschlange
Redis Die Kombination aus dem Befehl lpush + brpop kann eine Blockierungswarteschlange realisieren
🎜> Zwei Fragen: Erstens, ob jeweils eine große Anzahl von Artikeln erhalten wird Beim Paging müssen mehrere hgetall-Vorgänge ausgeführt werden. In diesem Fall sollten Sie erwägen, die Pipeline zum Abrufen in Stapeln zu verwenden oder die Artikeldaten in einen Zeichenfolgentyp zu serialisieren und mget zum Abrufen in Stapeln zu verwenden. Zweitens bietet der Befehl lrange beim Abrufen der Artikelliste an beiden Enden der Liste eine bessere Leistung. Wenn die Liste jedoch größer ist, wird die Leistung beim Abrufen der Elemente im mittleren Bereich der Liste schlechter. Sie können eine Aufteilung auf zwei Ebenen in Betracht ziehen
lpush+rpop=Queue(Warteschlange)
lpsh +ltrim=Capped Collection(begrenzte Sammlung)
Ziplist (komprimierte Liste) Wenn die Reihenfolge der geordneten Sammlung kleiner als die ZSET-MAX-Ziplist-Entries-Konfiguration ist und der Wert jedes Elements kleiner ist Als die ZSET-MAX-Ziplist-Value-Konfiguration verwendet Redis Ziplist Als interne Implementierung geordneter Sätze kann Ziplist die Speichernutzung effektiv reduzieren
Skiplist (Überspringliste) Wenn die Ziplist-Bedingungen nicht erfüllt sind, Bestellte Sets verwenden Skiplist als interne Implementierung, daher verringert sich die Lese- und Schreibeffizienz von Ziplist.
2.6.3 Nutzungsszenarien
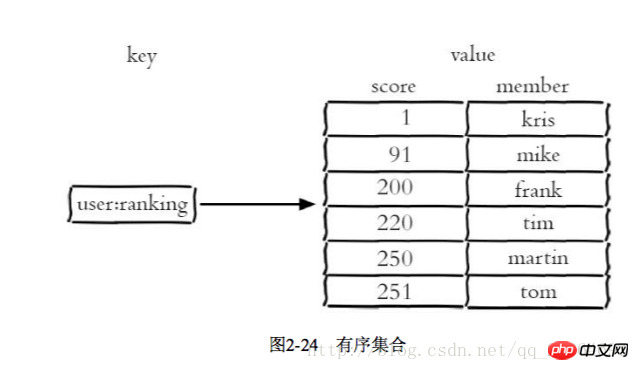
Ein typisches Nutzungsszenario für geordnete Sammlungen ist das Ranking-System. Beispielsweise muss eine Video-Website die von Benutzern hochgeladenen Videos bewerten

 1 Datenbank wechseln, dbIndex auswählen
1 Datenbank wechseln, dbIndex auswählen
2.8 Rückblick auf das Ende dieses Kapitels
Verwandte Empfehlungen:
Redis-Datenstruktur
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)