
Heim >Web-Frontend >js-Tutorial >Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell
Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell

- 小云云Original
- 2018-03-07 14:01:354216Durchsuche
1. Einführung
Wenn wir Crawler-Programme zum Crawlen von Webseiten verwenden, ist das Crawlen statischer Seiten im Allgemeinen relativ einfach, und wir haben bereits viele Fälle geschrieben. Aber wie kann man mit js dynamisch geladene Seiten crawlen?
Es gibt mehrere Crawling-Methoden für dynamische JS-Seiten:
Erreicht durch Selenium+PhantomJS.
Phantomjs ist ein Headless-Browser, Selenium ist ein automatisiertes Testframework. Fordern Sie die Seite über den Headless-Browser an, warten Sie, bis js geladen ist, und erhalten Sie die Daten dann durch automatisierte Tests Selen. Da Headless-Browser viele Ressourcen verbrauchen, mangelt es ihnen an Leistung.
Scrapy-Splash-Framework:
Splash ist als JS-Rendering-Dienst leichtgewichtig und basiert auf Twisted und QT-Browser-Engine und bietet direkte http-API. Die schnellen und leichten Funktionen erleichtern die verteilte Entwicklung.
Die Crawler-Frameworks Splash und Scrapy sind miteinander kompatibel und weisen eine bessere Crawling-Effizienz auf.
2. Aufbau der Splash-Umgebung
Der Splash-Dienst basiert auf dem Docker-Container, daher müssen wir zuerst den Docker-Container installieren.
2.1 Docker-Installation (Windows 10 Home-Version)
Wenn es sich um eine Win 10 Professional-Version oder andere Betriebssysteme handelt, ist die Installation von Docker in der Windows 10 Home-Version einfacher Zur Verwendung der Toolbox müssen die neuesten Tools installiert werden.
Informationen zur Installation von Docker finden Sie in der Dokumentation: Docker unter WIN10 installieren
2.2 Splash-Installation
docker pull scrapinghub/splash
2.3 Starten des Splash-Dienstes
docker run -p 8050:8050 scrapinghub/splash
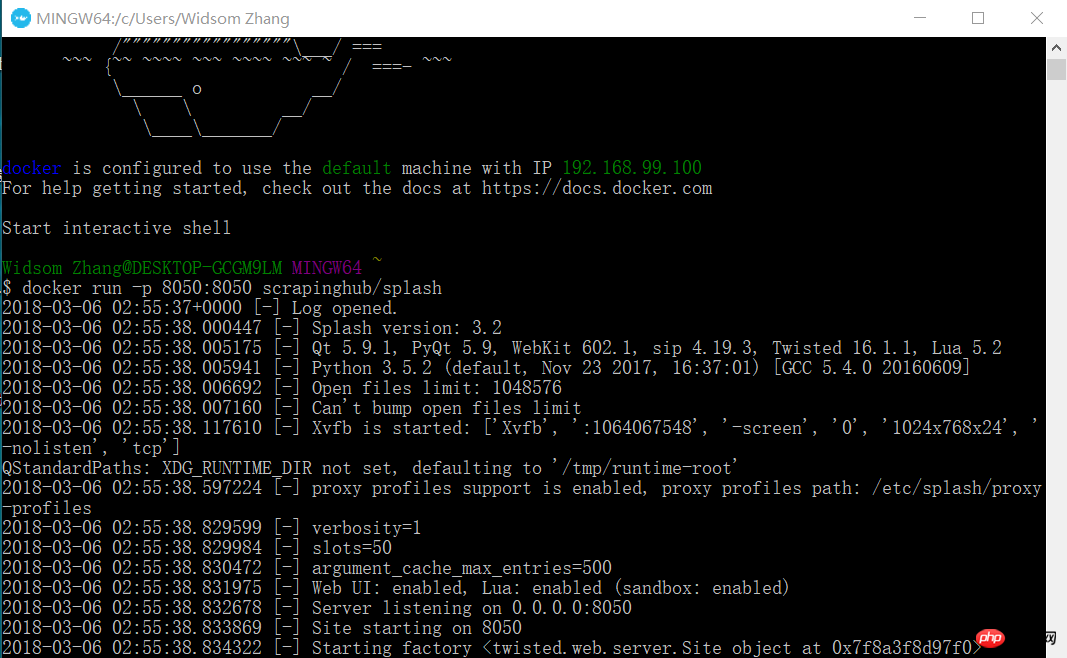
Öffnen Sie jetzt Ihren Browser und geben Sie 192.168.99.100:8050 ein. Sie sehen eine Schnittstelle wie diese.
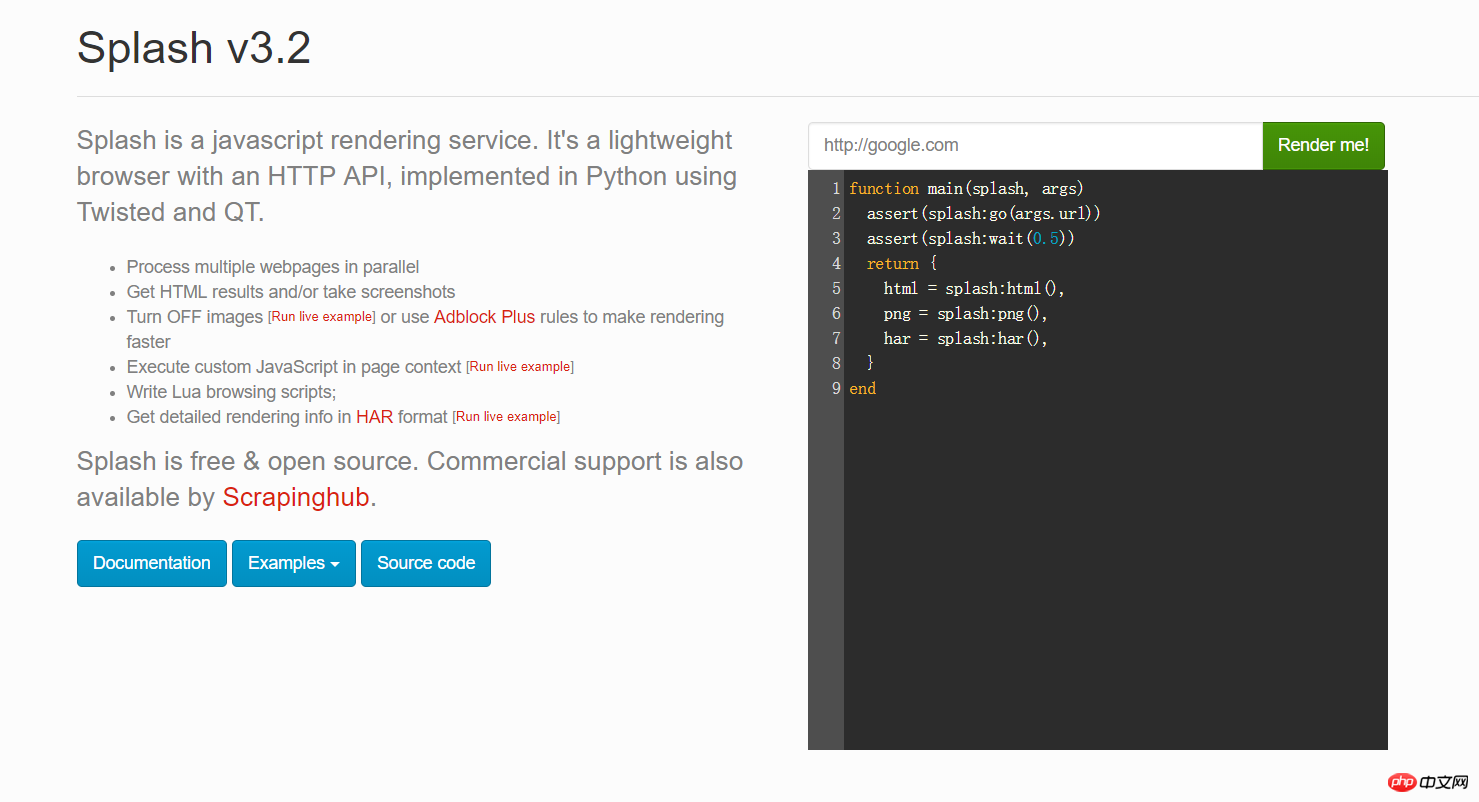
Sie können eine beliebige URL in das rote Feld im Bild oben eingeben und auf „Rendern“ klicken, um zu sehen, wie sie nach dem Rendern aussehen wird
2.4 Installieren Python Das Scrapy-Splash-Paket
pip install scrapy-splash
3. Der Scrapy-Crawler lädt den js-Projekttest am Beispiel von Google News.
Aus geschäftlichen Gründen crawlen wir einige ausländische Nachrichten-Websites, wie zum Beispiel Google News. Aber ich fand heraus, dass es sich tatsächlich um JS-Code handelte. Also begann ich, das Scrapy-Splash-Framework zu verwenden und mit dem js-Rendering-Dienst von Splash zusammenzuarbeiten, um Daten zu erhalten. Schauen Sie sich insbesondere den folgenden Code an:
3.1 Settings.py-Konfigurationsinformationen
# 渲染服务的urlSPLASH_URL = 'http://192.168.99.100:8050'# 去重过滤器DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# 使用Splash的Http缓存HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}#下载器中间件DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 请求头DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}# 管道ITEM_PIPELINES = { 'news.pipelines.NewsPipeline': 300,
}3.2 Elementfelddefinition
class NewsItem(scrapy.Item): # 标题
title = scrapy.Field() # 图片的url链接
Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url = scrapy.Field() # 新闻来源
source = scrapy.Field() # 点击的url
action_url = scrapy.Field()3.3 Spider-Code
Erstellen Sie im Spider-Verzeichnis eine Datei new_spider.py mit folgendem Inhalt:
from scrapy import Spiderfrom scrapy_splash import SplashRequestfrom news.items import NewsItemclass GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"] def start_requests(self):
for url in self.start_urls: # 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1}) def parse(self, response):
for element in response.xpath('//p[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnellUrl = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url'] = Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnellUrl
item['action_url'] = actionUrl
item['source'] = source yield item3.4 Pipelines.py-Code
Speichern Sie die Artikeldaten in der MySQL-Datenbank.
db_news-Datenbank erstellen
CREATE DATABASE db_news
tb_news-Tabelle erstellen
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30), PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;NewsPipeline-Klasse
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor() def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url"], item["action_url"], item["source"]))
self.conn.commit() return item def close_spider(self):
self.cursor.close()
self.conn.close()3.5 Scrapy-Crawler ausführen
Auf der Konsole ausgeführt:
scrapy crawl google_news
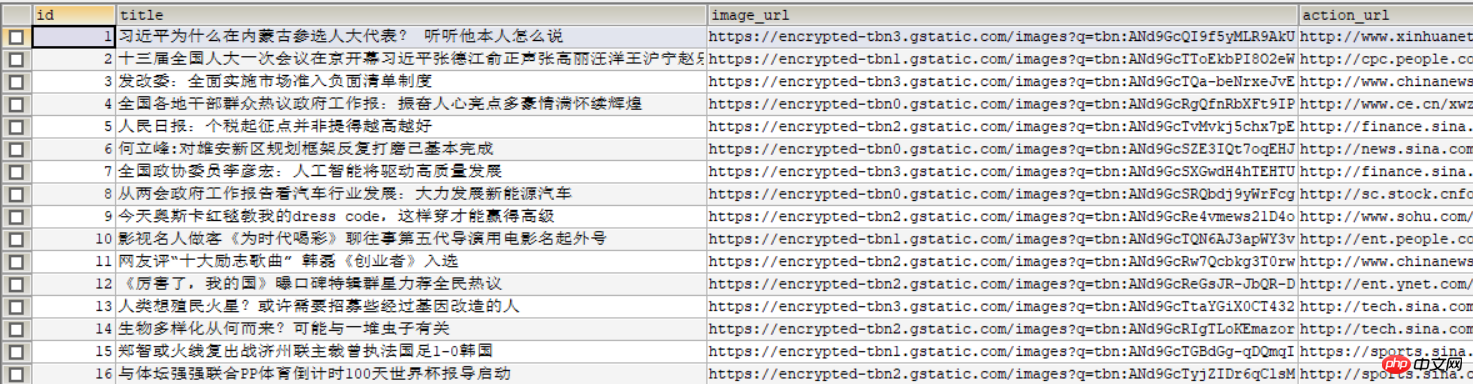
Das folgende Bild wird in der Datenbank angezeigt:
Verwandte Empfehlungen:
Grundlegende Einführung in Scrapy-Befehle
Einführung in das Scrapy-Crawler-Framework
Das obige ist der detaillierte Inhalt vonDas Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse